Staircase Streaming for Low-Latency Multi-Agent Inference
作者: Junlin Wang, Jue Wang, Zhen, Xu, Ben Athiwaratkun, Bhuwan Dhingra, Ce Zhang, James Zou
分类: cs.AI
发布日期: 2025-10-06
💡 一句话要点
提出Staircase Streaming,解决多Agent推理中高延迟问题,显著降低TTFT。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多Agent推理 低延迟 流式处理 首个token生成时间 LLM Staircase Streaming 并行计算
📋 核心要点
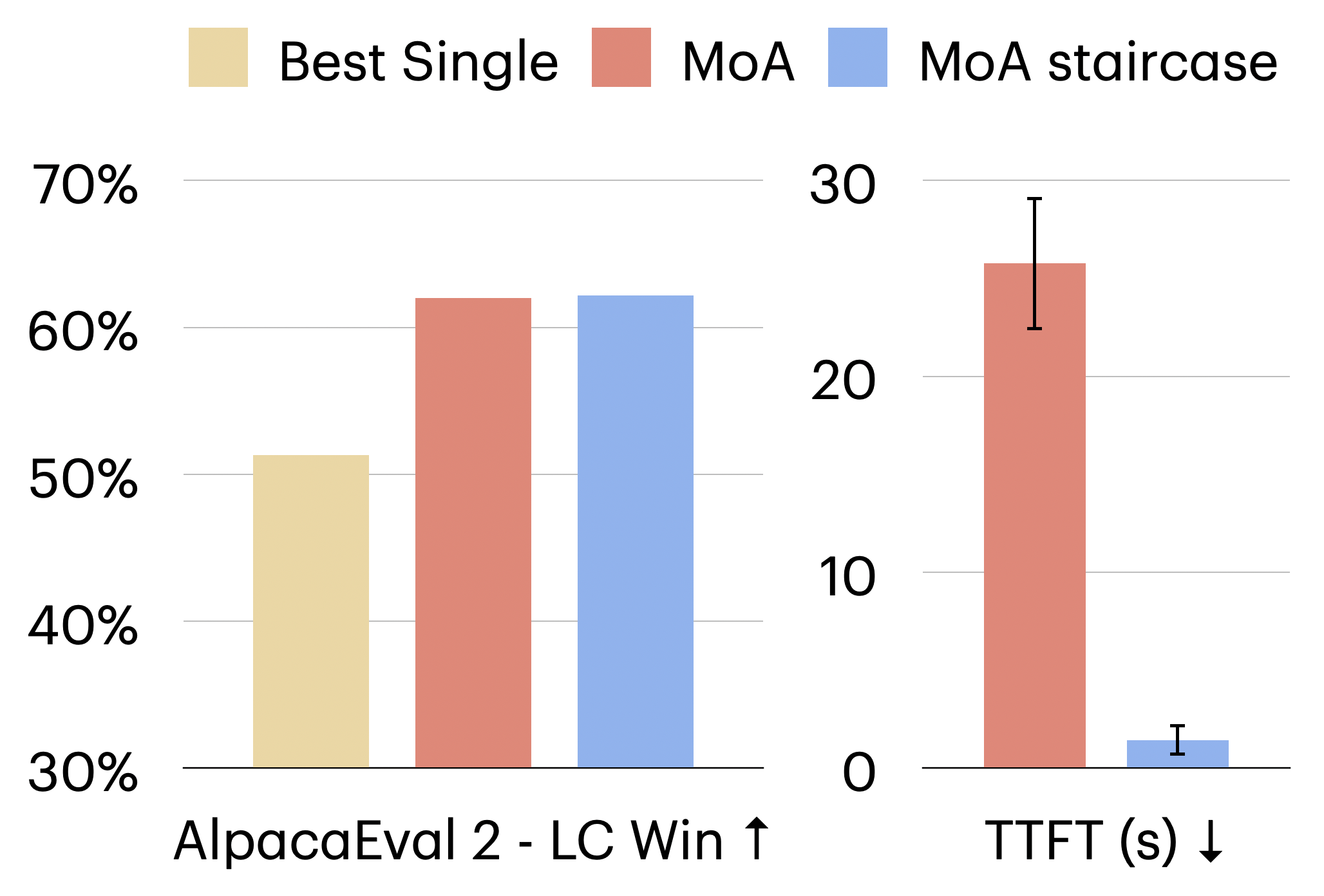
- 多Agent推理提升了LLM的响应质量,但引入了额外的推理步骤,导致首个token生成时间(TTFT)显著增加。
- Staircase Streaming的核心思想是利用前序Agent的部分输出,无需等待完整输出即可开始生成最终响应。
- 实验结果表明,Staircase Streaming在保证响应质量的前提下,能够将TTFT降低高达93%,提升用户体验。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展为利用多个LLMs的集体专业知识开辟了新方向。诸如混合Agent等方法通常采用额外的推理步骤来生成中间输出,然后使用这些中间输出来生成最终响应。虽然多Agent推理可以提高响应质量,但它会显著增加首个token生成时间(TTFT),这对延迟敏感型应用构成挑战,并损害用户体验。为了解决这个问题,我们提出了用于低延迟多Agent推理的Staircase Streaming。我们不再等待先前步骤的完整中间输出,而是在收到这些步骤的部分输出后立即开始生成最终响应。实验结果表明,Staircase Streaming在保持响应质量的同时,可将TTFT降低高达93%。
🔬 方法详解
问题定义:论文旨在解决多Agent推理过程中,由于需要等待所有中间步骤完成后才能生成最终结果,导致的首个token生成时间(TTFT)过长的问题。现有方法的痛点在于,它们必须等待前序Agent生成完整的输出,才能开始后续Agent的处理,这在高并发、对延迟敏感的应用场景中是不可接受的。
核心思路:论文的核心思路是“Staircase Streaming”,即阶梯式流式处理。不再等待前序Agent生成完整的中间结果,而是利用前序Agent已经生成的部分结果,尽早启动后续Agent的推理过程。这样,多个Agent可以并行工作,从而显著降低整体的TTFT。这种设计类似于流水线作业,每个Agent只负责处理一部分数据,并将处理结果传递给下一个Agent。
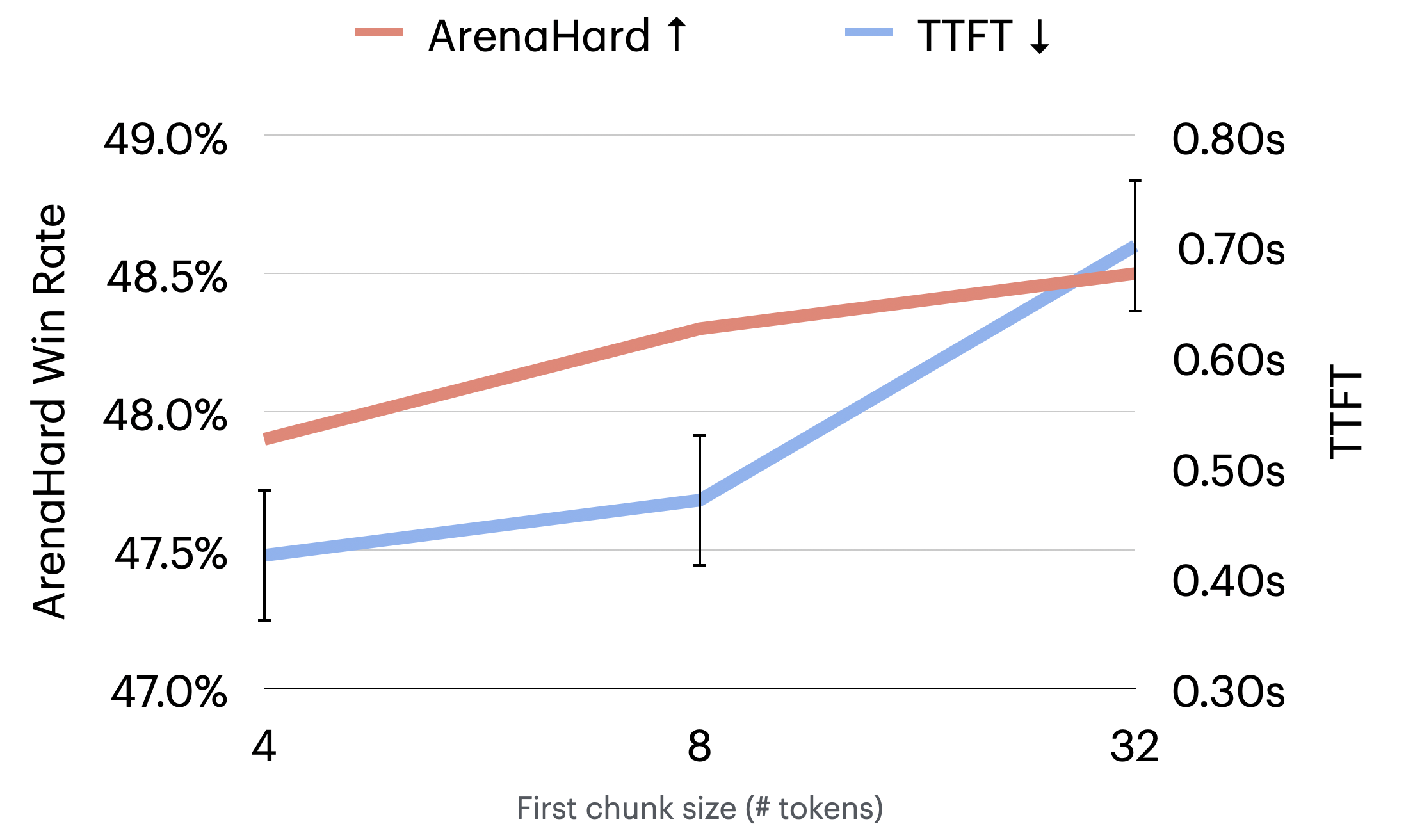
技术框架:整体框架包含多个Agent,每个Agent负责一个特定的任务或处理阶段。Agent之间通过流式传输中间结果进行通信。具体流程如下:1) 第一个Agent开始生成中间结果;2) 当第一个Agent生成部分结果后,将其传递给第二个Agent;3) 第二个Agent基于接收到的部分结果开始推理;4) 重复步骤2和3,直到最后一个Agent生成最终结果。整个过程呈现阶梯状,因此称为“Staircase Streaming”。
关键创新:最重要的技术创新点在于,它打破了传统多Agent推理中串行执行的模式,实现了Agent之间的并行处理。与现有方法相比,Staircase Streaming无需等待前序Agent的完整输出,从而显著降低了TTFT。这种流式处理的思想可以应用于各种多Agent推理场景,具有很强的通用性。
关键设计:论文中没有明确提及具体的参数设置、损失函数或网络结构等技术细节,重点在于Staircase Streaming的整体框架和流式处理的思想。关键在于如何有效地将前序Agent的部分输出传递给后续Agent,以及如何保证在部分信息的情况下,后续Agent能够进行有效的推理。这可能涉及到一些特定的数据结构和通信协议的设计,但论文中没有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Staircase Streaming能够显著降低多Agent推理的TTFT,最高可达93%。这意味着在保持响应质量的前提下,系统可以更快地生成第一个token,从而提升用户体验。具体的性能数据和对比基线需要在论文中查找,但93%的TTFT降低幅度表明该方法具有显著的优势。
🎯 应用场景
该研究成果可广泛应用于对延迟有严格要求的LLM应用场景,例如在线客服、实时翻译、智能助手等。通过降低TTFT,可以显著提升用户体验,提高系统的响应速度和并发处理能力。未来,该方法还可以扩展到更复杂的多Agent系统中,例如机器人协作、自动驾驶等领域。
📄 摘要(原文)
Recent advances in large language models (LLMs) opened up new directions for leveraging the collective expertise of multiple LLMs. These methods, such as Mixture-of-Agents, typically employ additional inference steps to generate intermediate outputs, which are then used to produce the final response. While multi-agent inference can enhance response quality, it can significantly increase the time to first token (TTFT), posing a challenge for latency-sensitive applications and hurting user experience. To address this issue, we propose staircase streaming for low-latency multi-agent inference. Instead of waiting for the complete intermediate outputs from previous steps, we begin generating the final response as soon as we receive partial outputs from these steps. Experimental results demonstrate that staircase streaming reduces TTFT by up to 93% while maintaining response quality.