Large Language Models Achieve Gold Medal Performance at the International Olympiad on Astronomy & Astrophysics (IOAA)
作者: Lucas Carrit Delgado Pinheiro, Ziru Chen, Bruno Caixeta Piazza, Ness Shroff, Yingbin Liang, Yuan-Sen Ting, Huan Sun
分类: astro-ph.IM, cs.AI, cs.CL
发布日期: 2025-10-06 (更新: 2025-10-07)
备注: 18 pages, 6 figures, to be submitted, comments are welcome. Reproducibility details can be found at: https://github.com/OSU-NLP-Group/LLM-IOAA
💡 一句话要点
大语言模型在国际天文与天体物理奥赛中达到金牌水平
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 天文学 国际奥赛 基准测试 性能评估
📋 核心要点
- 现有天文领域LLM评估侧重简单问答,缺乏对复杂推理能力的考察,无法全面反映LLM的真实水平。
- 论文利用国际天文与天体物理奥赛(IOAA)试题,系统评估了五个先进LLM在概念理解、多步骤推导和多模态分析方面的能力。
- 实验结果表明,Gemini 2.5 Pro和GPT-5在理论考试中达到金牌水平,但在数据分析和特定推理方面仍存在不足。
📝 摘要(中文)
尽管特定任务的演示表明,将大型语言模型(LLM)应用于自动化天文研究任务已取得初步成功,但它们仅提供了解决天文问题所需的所有必要能力的不完整视图,因此需要更全面地了解LLM的优势和局限性。目前,现有的基准和评估侧重于简单的问答,主要测试天文知识,而未能评估该学科实际研究所需的复杂推理。本文通过系统地对五个最先进的LLM在国际天文与天体物理奥赛(IOAA)考试中进行基准测试来弥补这一差距,该考试旨在检验深刻的概念理解、多步骤推导和多模态分析。Gemini 2.5 Pro和GPT-5(两个表现最佳的模型)的平均得分分别为85.6%和84.2%,不仅达到了金牌水平,而且在评估的所有四个IOAA理论考试(2022-2025)中,在约200-300名参与者中排名前两名。相比之下,数据分析考试的结果显示出更大的差异。GPT-5在考试中仍然表现出色,平均得分为88.5%,在最近四届IOAA的参与者中排名前10名,而其他模型的表现则下降到48-76%。此外,我们的深入错误分析强调,概念推理、几何推理和空间可视化(52-79%的准确率)是所有LLM的持续弱点。因此,尽管LLM在理论考试中接近人类的峰值表现,但在它们能够作为天文领域的自主研究代理之前,必须解决关键差距。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在解决复杂天文问题方面的能力,并识别其优势和局限性。现有方法主要通过简单问答来评估LLM的天文知识,无法有效测试其在实际天文研究中所需的复杂推理、多步骤推导和多模态分析能力。
核心思路:论文的核心思路是利用国际天文与天体物理奥赛(IOAA)的试题作为基准,全面评估LLM在概念理解、几何推理、空间可视化和数据分析等方面的能力。IOAA试题具有挑战性,能够有效区分LLM在不同方面的表现,从而更准确地了解其优势和不足。
技术框架:论文采用了一种系统的基准测试方法,包括以下几个主要步骤:1) 选择五个最先进的LLM进行评估,包括Gemini 2.5 Pro和GPT-5等;2) 使用IOAA的理论和数据分析试题作为测试集;3) 对LLM的输出进行评分,并与人类参与者的表现进行比较;4) 对LLM的错误进行深入分析,识别其在不同方面的弱点。
关键创新:论文的关键创新在于使用IOAA试题作为评估LLM天文能力的基准。IOAA试题不仅考察天文知识,还考察复杂推理、多步骤推导和多模态分析能力,能够更全面地评估LLM在解决实际天文问题方面的潜力。此外,论文还对LLM的错误进行了深入分析,识别了其在概念推理、几何推理和空间可视化等方面的弱点。
关键设计:论文的关键设计包括:1) 选择具有代表性的LLM进行评估;2) 使用多个年份的IOAA试题,以确保评估的可靠性;3) 对LLM的输出进行人工评分,以确保评分的准确性;4) 使用多种指标来评估LLM的性能,包括平均得分、排名和准确率等。
🖼️ 关键图片
📊 实验亮点
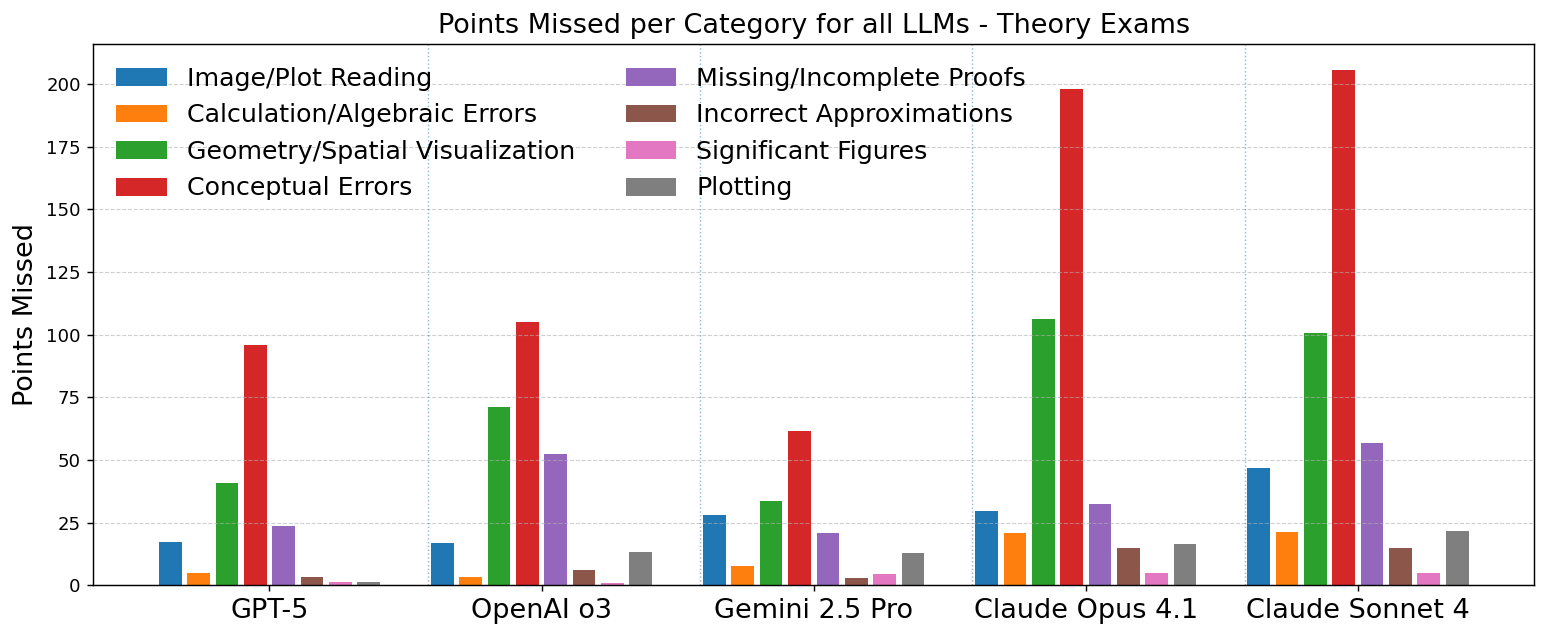
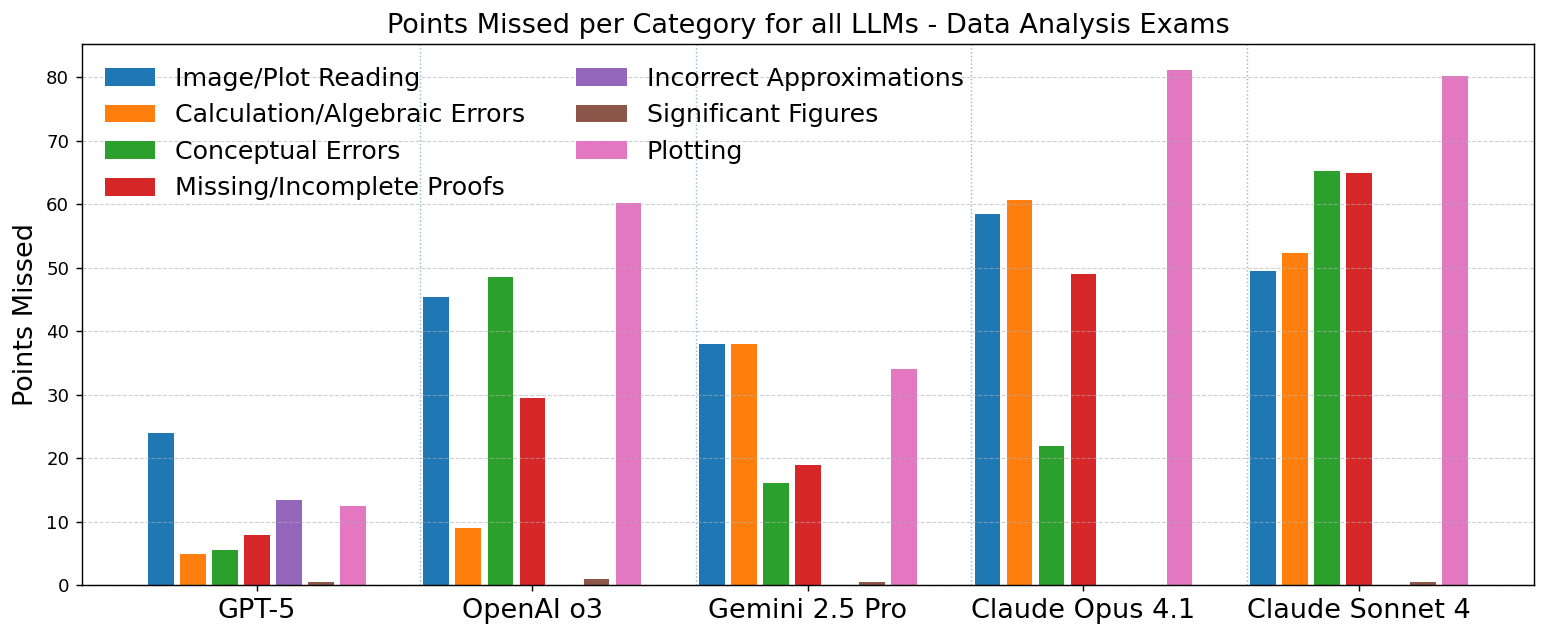
实验结果表明,Gemini 2.5 Pro和GPT-5在IOAA理论考试中表现出色,平均得分分别为85.6%和84.2%,达到金牌水平,并在所有参与者中排名前两名。GPT-5在数据分析考试中也表现出色,平均得分为88.5%,排名前10名。然而,所有LLM在概念推理、几何推理和空间可视化方面都存在明显的弱点,准确率仅为52-79%。
🎯 应用场景
该研究成果可应用于评估和改进LLM在天文研究中的应用潜力,例如辅助天文数据分析、自动化科学发现和教育培训。通过识别LLM的优势和局限性,可以更有针对性地开发和优化LLM,使其在天文领域发挥更大的作用,并最终推动天文研究的进展。
📄 摘要(原文)
While task-specific demonstrations show early success in applying large language models (LLMs) to automate some astronomical research tasks, they only provide incomplete views of all necessary capabilities in solving astronomy problems, calling for more thorough understanding of LLMs' strengths and limitations. So far, existing benchmarks and evaluations focus on simple question-answering that primarily tests astronomical knowledge and fails to evaluate the complex reasoning required for real-world research in the discipline. Here, we address this gap by systematically benchmarking five state-of-the-art LLMs on the International Olympiad on Astronomy and Astrophysics (IOAA) exams, which are designed to examine deep conceptual understanding, multi-step derivations, and multimodal analysis. With average scores of 85.6% and 84.2%, Gemini 2.5 Pro and GPT-5 (the two top-performing models) not only achieve gold medal level performance but also rank in the top two among ~200-300 participants in all four IOAA theory exams evaluated (2022-2025). In comparison, results on the data analysis exams show more divergence. GPT-5 still excels in the exams with an 88.5% average score, ranking top 10 among the participants in the four most recent IOAAs, while other models' performances drop to 48-76%. Furthermore, our in-depth error analysis underscores conceptual reasoning, geometric reasoning, and spatial visualization (52-79% accuracy) as consistent weaknesses among all LLMs. Hence, although LLMs approach peak human performance in theory exams, critical gaps must be addressed before they can serve as autonomous research agents in astronomy.