AutoEmpirical: LLM-Based Automated Research for Empirical Software Fault Analysis
作者: Jiongchi Yu, Weipeng Jiang, Xiaoyu Zhang, Qiang Hu, Xiaofei Xie, Chao Shen
分类: cs.SE, cs.AI
发布日期: 2025-10-06
备注: 5 pages
💡 一句话要点
AutoEmpirical:利用大语言模型自动进行软件缺陷的实证研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 软件缺陷分析 大语言模型 自动化 实证研究 软件工程
📋 核心要点
- 传统软件缺陷分析依赖专家手动操作,流程繁琐耗时,难以支持大规模研究和快速迭代。
- AutoEmpirical 探索利用大语言模型(LLM)自动化软件缺陷分析,提升效率并降低人工成本。
- 实验表明,LLM 将缺陷分析时间从数周缩短至约两小时,显著提升了效率。
📝 摘要(中文)
理解软件缺陷对于软件开发和维护中的实证研究至关重要。然而,传统的缺陷分析通常涉及多个专家驱动的步骤,例如收集潜在缺陷、过滤和手动调查,这些过程既费力又耗时,从而阻碍了在复杂但关键的软件系统中进行大规模缺陷研究,并减缓了迭代实证研究的步伐。本文将软件缺陷实证研究过程分解为三个关键阶段:(1)研究目标定义,(2)数据准备,(3)缺陷分析。我们初步探索了将大型语言模型(LLM)应用于开源软件的缺陷分析。具体而言,我们对来自高质量实证研究的3829个软件缺陷进行了评估。结果表明,与通常需要数周的手动工作相比,LLM可以显著提高缺陷分析的效率,平均处理时间约为两小时。最后,我们概述了一个详细的研究计划,强调了LLM在推进实证缺陷研究方面的潜力,以及实现完全自动化、端到端软件缺陷分析所需的开放挑战。
🔬 方法详解
问题定义:论文旨在解决软件缺陷实证研究中,传统人工缺陷分析方法效率低下、耗时费力的问题。现有方法依赖于领域专家手动收集、过滤和调查缺陷,难以应对大规模软件系统和快速迭代的需求。
核心思路:论文的核心思路是将软件缺陷实证研究过程分解为研究目标定义、数据准备和缺陷分析三个阶段,并探索利用大语言模型(LLM)自动化缺陷分析阶段,从而提高整体效率。通过利用 LLM 的自然语言理解和生成能力,自动分析缺陷报告,减少人工干预。
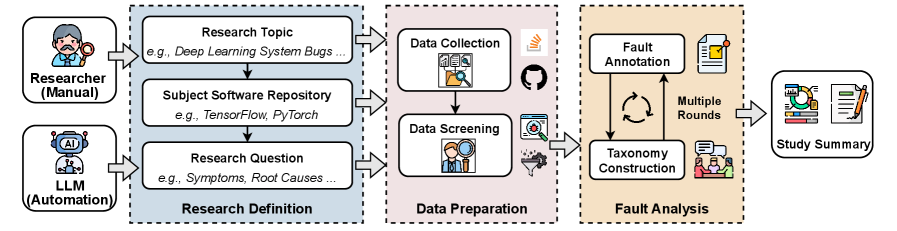
技术框架:AutoEmpirical 的整体框架包含三个主要阶段:1. 研究目标定义:确定研究的具体目标,例如缺陷类型、影响范围等。2. 数据准备:收集和整理缺陷数据,例如缺陷报告、代码提交记录等。3. 缺陷分析:利用 LLM 对缺陷数据进行分析,例如识别缺陷原因、影响范围、修复方案等。LLM 在此框架中主要负责缺陷分析阶段,接收缺陷数据作为输入,输出分析结果。
关键创新:该论文的关键创新在于将大语言模型应用于软件缺陷的自动化分析。与传统方法相比,AutoEmpirical 无需人工干预即可自动分析缺陷,显著提高了效率。此外,LLM 能够从大量文本数据中学习,从而发现传统方法难以发现的缺陷模式。
关键设计:论文中没有详细描述 LLM 的具体参数设置、损失函数或网络结构。但是,可以推断,该系统可能使用了预训练的 LLM 模型(例如 BERT、GPT 等),并针对软件缺陷分析任务进行了微调。具体的微调策略和数据集选择将直接影响 LLM 的分析性能。未来的研究可以探索不同的 LLM 模型和微调策略,以进一步提高缺陷分析的准确性和效率。
🖼️ 关键图片
📊 实验亮点
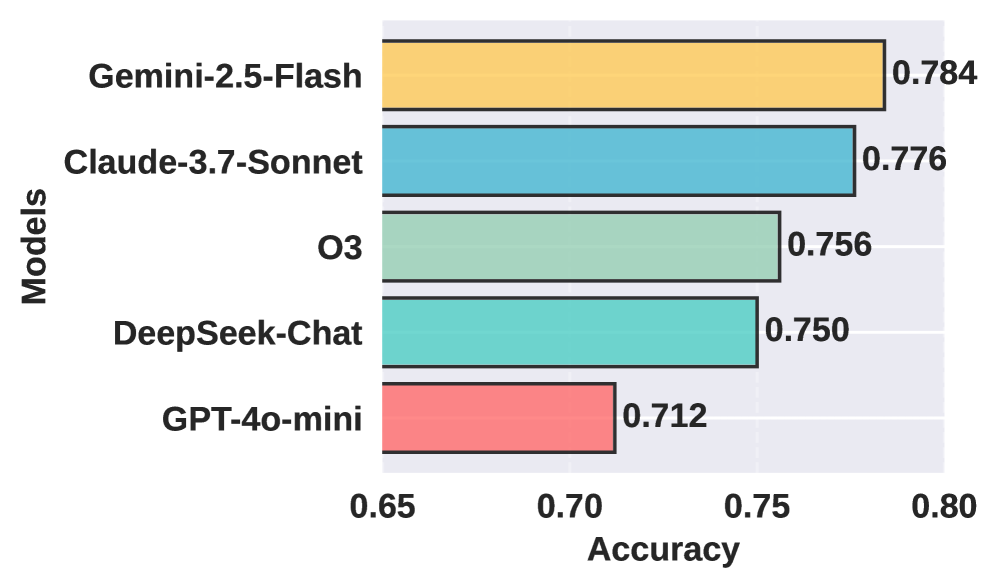
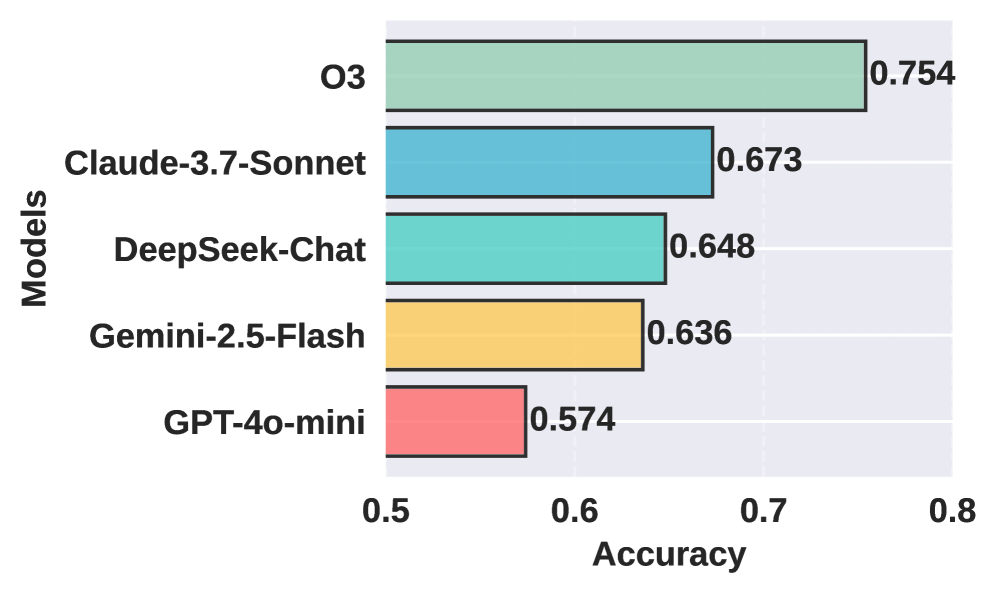
实验结果表明,AutoEmpirical 利用 LLM 将缺陷分析时间从传统的手动分析所需的数周缩短至约两小时,显著提高了效率。该研究在包含 3829 个软件缺陷的数据集上进行了评估,验证了 LLM 在缺陷分析方面的潜力。虽然论文没有提供具体的准确率或召回率等指标,但时间上的显著提升表明了 LLM 在自动化缺陷分析方面的巨大优势。
🎯 应用场景
AutoEmpirical 有潜力应用于软件开发和维护的多个领域,例如缺陷预测、根源分析、代码审查等。它可以帮助开发人员更快地识别和修复缺陷,提高软件质量和可靠性。此外,该研究为利用 LLM 解决软件工程问题提供了新的思路,有望推动软件工程领域的自动化和智能化。
📄 摘要(原文)
Understanding software faults is essential for empirical research in software development and maintenance. However, traditional fault analysis, while valuable, typically involves multiple expert-driven steps such as collecting potential faults, filtering, and manual investigation. These processes are both labor-intensive and time-consuming, creating bottlenecks that hinder large-scale fault studies in complex yet critical software systems and slow the pace of iterative empirical research. In this paper, we decompose the process of empirical software fault study into three key phases: (1) research objective definition, (2) data preparation, and (3) fault analysis, and we conduct an initial exploration study of applying Large Language Models (LLMs) for fault analysis of open-source software. Specifically, we perform the evaluation on 3,829 software faults drawn from a high-quality empirical study. Our results show that LLMs can substantially improve efficiency in fault analysis, with an average processing time of about two hours, compared to the weeks of manual effort typically required. We conclude by outlining a detailed research plan that highlights both the potential of LLMs for advancing empirical fault studies and the open challenges that required be addressed to achieve fully automated, end-to-end software fault analysis.