LLM-Hanabi: Evaluating Multi-Agent Gameplays with Theory-of-Mind and Rationale Inference in Imperfect Information Collaboration Game
作者: Fangzhou Liang, Tianshi Zheng, Chunkit Chan, Yauwai Yim, Yangqiu Song
分类: cs.AI, cs.CL
发布日期: 2025-10-06
备注: EMNLP 2025 Wordplay
💡 一句话要点
LLM-Hanabi:利用Hanabi评估LLM在不完美信息协作中的心智理论和理性推断能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 心智理论 多智能体协作 不完美信息博弈 理性推断
📋 核心要点
- 现有方法难以评估LLM在动态协作环境中进行理性推断和心智理论(ToM)的能力。
- 论文提出LLM-Hanabi基准,利用Hanabi游戏评估LLM的理性推断和ToM能力,并构建自动评估系统。
- 实验表明ToM与游戏性能正相关,且一阶ToM(理解他人意图)比二阶ToM对性能影响更大。
📝 摘要(中文)
有效的多智能体协作需要智能体推断其他智能体行为背后的理性,这种能力根植于心智理论(ToM)。虽然最近的大型语言模型(LLM)擅长逻辑推理,但它们在动态协作环境中推断理性的能力仍未得到充分探索。本研究引入了LLM-Hanabi,这是一个新颖的基准,它使用合作游戏Hanabi来评估LLM的理性推断和ToM。我们的框架具有一个自动评估系统,可以衡量游戏性能和ToM熟练程度。在各种模型中,我们发现ToM与游戏中的成功之间存在显着的正相关关系。值得注意的是,一阶ToM(解释他人的意图)与性能的相关性高于二阶ToM(预测他人解释)。这些发现表明,对于有效的AI协作,准确解释合作伙伴的理性比高阶推理更为关键。我们得出结论,优先考虑一阶ToM是增强未来模型协作能力的一个有希望的方向。
🔬 方法详解
问题定义:论文旨在解决如何有效评估大型语言模型(LLM)在不完美信息协作游戏中,特别是Hanabi游戏中,进行理性推断和心智理论(ToM)的能力。现有方法缺乏一个专门设计的基准来量化LLM在动态协作环境中理解和预测其他智能体行为的能力,这阻碍了对LLM协作智能的深入研究。
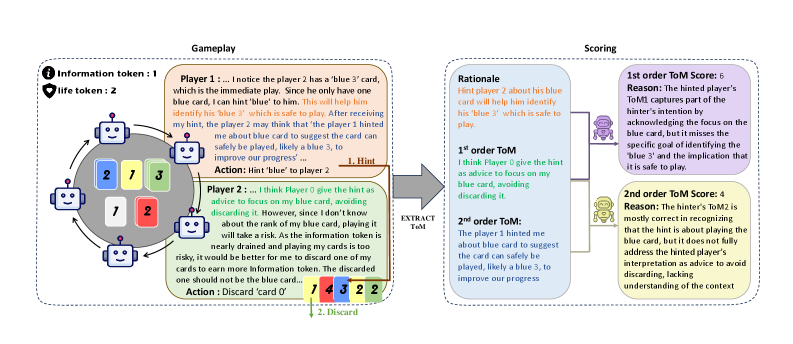
核心思路:论文的核心思路是利用Hanabi游戏作为评估LLM协作智能的平台。Hanabi是一个合作游戏,玩家需要根据不完全信息推断队友的牌面信息和意图,从而考验智能体的理性推断和ToM能力。通过设计自动评估系统,可以量化LLM在Hanabi游戏中的表现,并将其与ToM能力联系起来。
技术框架:LLM-Hanabi框架包含以下主要模块:1) Hanabi游戏环境:提供标准化的游戏规则和交互接口。2) LLM智能体:使用LLM作为智能体参与游戏,通过prompting等技术引导LLM进行决策。3) 自动评估系统:根据游戏得分和ToM指标(例如,预测队友行动的准确性)评估LLM的表现。4) ToM评估指标:设计一阶和二阶ToM指标,量化LLM理解和预测其他智能体意图的能力。
关键创新:论文的关键创新在于提出了LLM-Hanabi基准,这是一个专门用于评估LLM在不完美信息协作游戏中理性推断和ToM能力的平台。与现有方法相比,LLM-Hanabi更加关注LLM在动态协作环境中的表现,并提供了自动化的评估系统和ToM指标,从而可以更全面地评估LLM的协作智能。
关键设计:论文的关键设计包括:1) 使用Hanabi游戏作为评估平台,Hanabi的规则和不完全信息特性使其成为评估协作智能的理想选择。2) 设计一阶和二阶ToM指标,量化LLM理解和预测其他智能体意图的能力。3) 构建自动评估系统,可以自动化地评估LLM在Hanabi游戏中的表现,并将其与ToM指标联系起来。4) 使用不同的LLM模型进行实验,比较它们在Hanabi游戏中的表现,并分析ToM能力与游戏性能之间的关系。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在Hanabi游戏中的表现与ToM能力呈正相关关系。具体而言,一阶ToM(理解他人意图)与游戏性能的相关性高于二阶ToM(预测他人解释)。这表明,对于有效的AI协作,准确理解合作伙伴的理性比高阶推理更为重要。例如,具备较强一阶ToM的LLM在Hanabi游戏中能够取得更高的分数。
🎯 应用场景
该研究成果可应用于开发更智能、更具协作能力的AI系统,例如在自动驾驶、医疗诊断、客户服务等领域。通过提升AI系统的心智理论能力,使其能够更好地理解和预测人类或其他AI的行为,从而实现更高效、更安全的协作。此外,LLM-Hanabi基准可以促进对LLM协作智能的深入研究,推动相关技术的发展。
📄 摘要(原文)
Effective multi-agent collaboration requires agents to infer the rationale behind others' actions, a capability rooted in Theory-of-Mind (ToM). While recent Large Language Models (LLMs) excel at logical inference, their ability to infer rationale in dynamic, collaborative settings remains under-explored. This study introduces LLM-Hanabi, a novel benchmark that uses the cooperative game Hanabi to evaluate the rationale inference and ToM of LLMs. Our framework features an automated evaluation system that measures both game performance and ToM proficiency. Across a range of models, we find a significant positive correlation between ToM and in-game success. Notably, first-order ToM (interpreting others' intent) correlates more strongly with performance than second-order ToM (predicting others' interpretations). These findings highlight that for effective AI collaboration, the ability to accurately interpret a partner's rationale is more critical than higher-order reasoning. We conclude that prioritizing first-order ToM is a promising direction for enhancing the collaborative capabilities of future models.