MARS: Co-evolving Dual-System Deep Research via Multi-Agent Reinforcement Learning
作者: Guoxin Chen, Zile Qiao, Wenqing Wang, Donglei Yu, Xuanzhong Chen, Hao Sun, Minpeng Liao, Kai Fan, Yong Jiang, Penguin Xie, Wayne Xin Zhao, Ruihua Song, Fei Huang
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-10-06 (更新: 2026-02-01)
备注: Ongoing Work
💡 一句话要点
MARS:通过多智能体强化学习共同进化双系统深度研究
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 双系统协同 知识密集型任务 大型推理模型 Zero RL 组相对策略优化
📋 核心要点
- 现有大型推理模型在处理简单任务时token消耗过高,且无法获取训练集之外的最新知识。
- MARS通过多智能体强化学习共同优化快速直觉的系统1和审慎推理的系统2,使二者协同进化。
- 实验表明,MARS在知识密集型任务上显著优于现有模型,并在HLE上逼近专有模型性能。
📝 摘要(中文)
大型推理模型(LRMs)面临两个根本限制:过度分析简单信息处理任务时消耗过多token,以及无法访问训练数据之外的最新知识。我们提出了MARS(深度研究的多智能体系统),这是一个新颖的共同进化框架,通过多智能体强化学习共同优化双认知系统。与采用固定或独立训练的摘要器的先前方法不同,MARS使系统1(快速、直观的处理)和系统2(审慎的推理)能够通过共享轨迹奖励进行共同适应,从而开发互补策略,其中系统1学习提炼对系统2推理特别有用的信息。我们扩展了用于多智能体设置的组相对策略优化(GRPO),具有三个关键创新:(1)解耦梯度计算,确保尽管有共享奖励也能正确分配信用,(2)用于高效并行信息处理的bin-packing优化,以及(3)防止训练不平衡的优势加权平衡采样。广泛的实验表明,在没有任何监督微调的具有挑战性的Zero RL设置下训练的MARS(8B)在HLE上实现了8.17%,优于WebThinker(具有SFT的32B,6.87%),并缩小了与Claude 3.7 Sonnet(7.89%)等专有模型的差距,同时在7个知识密集型任务中实现了平均8.9%的增益。
🔬 方法详解
问题定义:论文旨在解决大型推理模型(LRMs)在处理信息时存在的两个主要问题:一是过度分析简单任务导致token消耗过高;二是无法获取训练数据之外的最新知识。现有方法,如固定或独立训练的摘要器,无法有效协同利用快速直觉和审慎推理两种认知模式,导致效率和知识覆盖的不足。
核心思路:MARS的核心思路是构建一个双系统协同进化的框架,通过多智能体强化学习(MARL)让系统1(快速、直觉)和系统2(审慎推理)共同适应,形成互补策略。系统1负责提炼对系统2推理有用的信息,而系统2则利用这些信息进行更深入的推理。这种协同进化能够提升整体效率和性能。
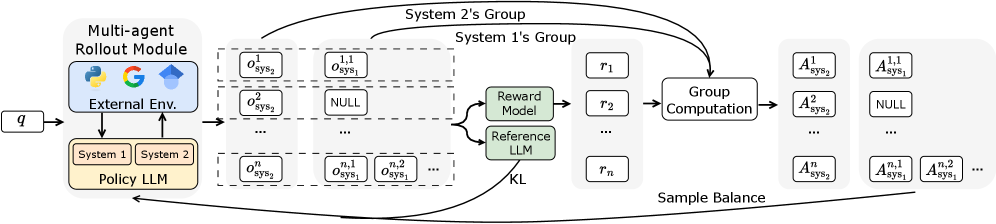
技术框架:MARS的技术框架基于多智能体强化学习。整体架构包含两个主要部分:系统1和系统2,分别由不同的智能体表示。这两个智能体通过共享轨迹奖励进行训练,从而实现协同进化。此外,论文还扩展了组相对策略优化(GRPO)算法,以适应多智能体环境。
关键创新:MARS的关键创新在于以下三个方面:1) 解耦梯度计算,确保在共享奖励的情况下,每个智能体都能获得正确的信用分配;2) 采用bin-packing优化,实现高效的并行信息处理;3) 使用优势加权平衡采样,防止训练过程中出现不平衡现象。这些创新使得MARS能够有效地训练双系统,并提升整体性能。
关键设计:在GRPO算法的扩展中,论文设计了特定的损失函数来解耦梯度计算,确保每个智能体都能根据其贡献获得相应的奖励。Bin-packing优化算法用于高效地分配计算资源,从而实现并行信息处理。优势加权平衡采样则通过调整样本权重,平衡不同类型样本对训练的影响。
🖼️ 关键图片

📊 实验亮点
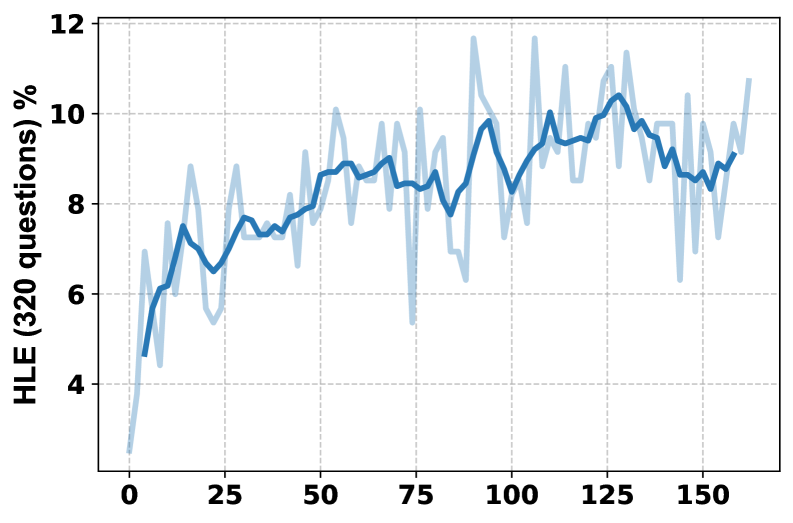
MARS (8B) 在 Zero RL 设置下训练,无需任何监督微调,在 HLE 上达到了 8.17% 的性能,超越了 WebThinker (32B with SFT, 6.87%),并缩小了与 Claude 3.7 Sonnet (7.89%) 等专有模型的差距。此外,MARS 在 7 个知识密集型任务中实现了平均 8.9% 的性能提升,证明了其在复杂推理任务上的有效性。
🎯 应用场景
MARS框架具有广泛的应用前景,可应用于问答系统、知识图谱推理、智能搜索等领域。通过提升模型处理复杂任务的效率和准确性,MARS能够改善用户体验,并为企业提供更智能的解决方案。未来,该框架有望应用于更广泛的认知计算任务,例如智能客服、自动化报告生成等。
📄 摘要(原文)
Large Reasoning Models (LRMs) face two fundamental limitations: excessive token consumption when overanalyzing simple information processing tasks, and inability to access up-to-date knowledge beyond their training data. We introduce MARS (Multi-Agent System for Deep ReSearch), a novel co-evolution framework that jointly optimizes dual cognitive systems through multi-agent reinforcement learning. Unlike prior approaches that employ fixed or independently-trained summarizers, MARS enables System 1 (fast, intuitive processing) and System 2 (deliberate reasoning) to co-adapt through shared trajectory rewards, developing complementary strategies where System 1 learns to distill information specifically useful for System 2's reasoning. We extend Group Relative Policy Optimization (GRPO) for multi-agent settings with three key innovations: (1) decoupled gradient computation ensuring proper credit assignment despite shared rewards, (2) bin-packing optimization for efficient parallel information processing, and (3) advantage-weighted balanced sampling preventing training imbalance. Extensive experiments demonstrate that MARS (8B), trained under a challenging Zero RL setting without any supervised fine-tuning, achieves 8.17% on HLE -- outperforming WebThinker (32B with SFT, 6.87%) and narrowing the gap with proprietary models like Claude 3.7 Sonnet (7.89%) -- while achieving an average gain of 8.9% across 7 knowledge-intensive tasks.