FreshBrew: A Benchmark for Evaluating AI Agents on Java Code Migration
作者: Victor May, Diganta Misra, Yanqi Luo, Anjali Sridhar, Justine Gehring, Silvio Soares Ribeiro Junior
分类: cs.SE, cs.AI
发布日期: 2025-10-06 (更新: 2025-10-13)
备注: 18 pages, 12 figures
💡 一句话要点
FreshBrew:用于评估AI Agent在Java代码迁移任务上的基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码迁移 AI Agent 基准测试 Java 大型语言模型
📋 核心要点
- 现有代码迁移方法依赖于规则和人工,效率低且难以适应快速变化的软件生态。
- FreshBrew基准测试通过评估AI Agent在Java项目迁移中保持语义和避免奖励黑客的能力,来衡量其有效性。
- 实验结果表明,Gemini 2.5 Flash在FreshBrew基准测试中表现最佳,成功迁移了52.3%的项目到JDK 17。
📝 摘要(中文)
AI编码助手正迅速成为现代软件开发不可或缺的一部分。该领域的一个关键挑战是不断迁移和现代化代码库,以响应不断发展的软件生态系统。传统上,这种迁移依赖于基于规则的系统和人工干预。随着强大的大型语言模型(LLM)的出现,AI驱动的Agent框架提供了一种有希望的替代方案,但其有效性尚未得到系统评估。本文介绍FreshBrew,这是一个新颖的基准,用于评估AI Agent在项目级Java迁移上的表现,特别关注衡量Agent保持程序语义和避免奖励黑客的能力,我们认为这需要具有高测试覆盖率的项目才能进行严格和可靠的评估。我们对几种最先进的LLM进行了基准测试,并将它们的性能与已建立的基于规则的工具进行了比较。我们对228个存储库的AI Agent的评估表明,性能最佳的模型Gemini 2.5 Flash可以成功地将52.3%的项目迁移到JDK 17。我们的实证分析揭示了当前Agent方法的关键优势和局限性的新见解,为它们的实际适用性提供了可操作的见解。我们的实证研究揭示了当前AI Agent在实际Java现代化任务中的失败模式,为评估可信的代码迁移系统奠定了基础。通过发布FreshBrew,我们旨在促进严格、可重复的评估,并促进AI驱动的代码库现代化。
🔬 方法详解
问题定义:论文旨在解决AI Agent在Java代码迁移任务中的评估问题。现有方法,如基于规则的系统和人工干预,无法有效应对快速演进的软件生态系统,且缺乏对AI Agent性能的系统性评估,尤其是在保持程序语义和避免奖励黑客方面。
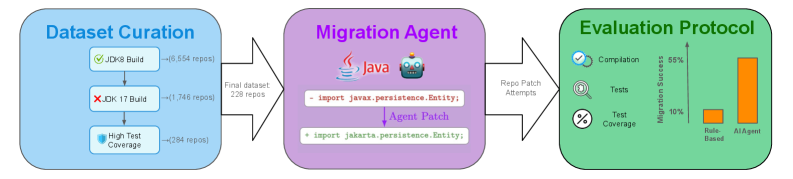
核心思路:论文的核心思路是构建一个专门用于评估AI Agent在Java代码迁移任务中的基准测试,该基准测试需要能够衡量Agent在项目级别迁移中保持程序语义和避免奖励黑客的能力。通过对多个真实Java项目进行迁移,并结合高测试覆盖率来保证评估的可靠性。
技术框架:FreshBrew基准测试包含以下主要组成部分:1)一个包含228个Java项目的代码库,这些项目具有不同的规模和复杂度;2)一套评估指标,用于衡量Agent在代码迁移过程中的性能,包括迁移成功率、语义保持程度和奖励黑客规避能力;3)一套自动化测试框架,用于验证迁移后的代码是否仍然满足原始程序的语义。整体流程是,将待评估的AI Agent应用于代码库中的项目,然后使用评估指标和自动化测试框架来评估Agent的性能。
关键创新:FreshBrew的关键创新在于其专注于评估AI Agent在代码迁移任务中的语义保持能力和奖励黑客规避能力。与以往的基准测试不同,FreshBrew强调了高测试覆盖率的重要性,并将其作为评估Agent性能的关键指标之一。此外,FreshBrew还提供了一个包含大量真实Java项目的代码库,这使得评估结果更具实际意义。
关键设计:FreshBrew的关键设计包括:1)选择具有不同规模和复杂度的Java项目,以确保基准测试的通用性;2)设计一套全面的评估指标,包括迁移成功率、语义保持程度和奖励黑客规避能力,以全面衡量Agent的性能;3)构建一个自动化测试框架,用于验证迁移后的代码是否仍然满足原始程序的语义,以确保评估的准确性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Gemini 2.5 Flash在FreshBrew基准测试中表现最佳,成功迁移了52.3%的项目到JDK 17。该结果显著优于其他基线模型,表明了当前最先进的LLM在代码迁移任务中具有一定的潜力,但仍存在改进空间。
🎯 应用场景
该研究成果可应用于自动化代码迁移、软件现代化、AI辅助软件开发等领域。通过FreshBrew基准测试,开发者可以更有效地评估和选择适合特定代码迁移任务的AI Agent,从而降低迁移成本、提高迁移效率,并确保迁移后的代码质量。
📄 摘要(原文)
AI coding assistants are rapidly becoming integral to modern software development. A key challenge in this space is the continual need to migrate and modernize codebases in response to evolving software ecosystems. Traditionally, such migrations have relied on rule-based systems and human intervention. With the advent of powerful large language models (LLMs), AI-driven agentic frameworks offer a promising alternative-but their effectiveness has not been systematically evaluated. In this paper, we introduce FreshBrew, a novel benchmark for evaluating AI agents on project-level Java migrations, with a specific focus on measuring an agent's ability to preserve program semantics and avoid reward hacking, which we argue requires projects with high test coverage for a rigorous and reliable evaluation. We benchmark several state-of-the-art LLMs, and compare their performance against established rule-based tools. Our evaluation of AI agents on this benchmark of 228 repositories shows that the top-performing model, Gemini 2.5 Flash, can successfully migrate 52.3 percent of projects to JDK 17. Our empirical analysis reveals novel insights into the critical strengths and limitations of current agentic approaches, offering actionable insights into their real-world applicability. Our empirical study reveals failure modes of current AI agents in realistic Java modernization tasks, providing a foundation for evaluating trustworthy code-migration systems. By releasing FreshBrew, we aim to facilitate rigorous, reproducible evaluation and catalyze progress in AI-driven codebase modernization.