ChartAgent: A Multimodal Agent for Visually Grounded Reasoning in Complex Chart Question Answering
作者: Rachneet Kaur, Nishan Srishankar, Zhen Zeng, Sumitra Ganesh, Manuela Veloso
分类: cs.AI, cs.CE, cs.CL, cs.CV, stat.ME
发布日期: 2025-10-06 (更新: 2026-01-07)
备注: NeurIPS 2025 Multimodal Algorithmic Reasoning Workshop (https://marworkshop.github.io/neurips25/) (Oral Paper Presentation)
💡 一句话要点
提出ChartAgent,通过视觉推理解决复杂图表问答中未标注图表的理解难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图表问答 多模态学习 视觉推理 Agent框架 未标注图表 视觉工具 大语言模型
📋 核心要点
- 现有基于图表的多模态LLM在未标注图表上性能显著下降,因为它们依赖文本捷径而非精确的视觉解释。
- ChartAgent通过迭代地将查询分解为视觉子任务,并使用图表特定的视觉工具与图表图像交互,显式地执行视觉推理。
- ChartAgent在ChartBench和ChartX上取得了SOTA结果,尤其在未标注和数值密集型查询上提升显著,且可作为即插即用框架。
📝 摘要(中文)
本文提出ChartAgent,一种新颖的agent框架,用于在复杂图表问答中执行视觉推理。与文本思维链推理不同,ChartAgent将查询迭代分解为视觉子任务,并通过专门的动作(如绘制注释、裁剪区域和定位轴)与图表图像进行交互。它利用图表特定的视觉工具库来完成每个子任务,模拟人类的图表理解认知策略。ChartAgent在ChartBench和ChartX基准测试中取得了最先进的准确率,总体上超过现有方法高达16.07%,在未标注的、数值密集型查询上超过17.31%。分析表明,ChartAgent在不同图表类型上有效,在不同的视觉和推理复杂度级别上取得了最高分,并且可以作为即插即用框架来提升各种底层LLM的性能。该工作是首批展示使用工具增强的多模态agent进行图表理解的视觉基础推理的研究之一。
🔬 方法详解
问题定义:论文旨在解决复杂图表问答任务中,现有方法在处理未标注图表时性能急剧下降的问题。现有方法通常依赖于图表中的文本信息,而缺乏直接的视觉推理能力,导致在需要精确视觉理解的场景下表现不佳。
核心思路:ChartAgent的核心思路是模拟人类理解图表的认知过程,通过迭代地分解问题为视觉子任务,并利用专门的视觉工具与图表进行交互,从而实现视觉基础的推理。这种方法避免了对文本信息的过度依赖,能够更准确地理解图表的视觉内容。
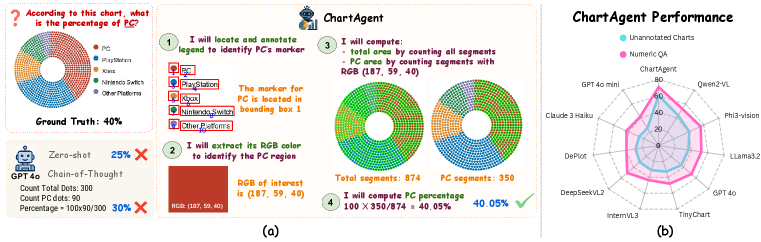
技术框架:ChartAgent的整体框架包含一个多模态LLM作为控制器,以及一个图表特定的视觉工具库。LLM接收问题和图表图像作为输入,然后将问题分解为一系列视觉子任务。对于每个子任务,LLM选择合适的视觉工具(例如,绘制注释、裁剪区域、定位坐标轴),并执行相应的操作。操作的结果反馈给LLM,用于指导下一步的推理。这个过程迭代进行,直到得到最终答案。
关键创新:ChartAgent最重要的创新在于其视觉基础的推理方式。与传统的文本思维链方法不同,ChartAgent直接在图表的空间域中进行推理,通过视觉操作来提取信息和解决问题。这种方法更符合人类的认知方式,并且能够更好地处理未标注的图表。
关键设计:ChartAgent的关键设计包括:1) 图表特定的视觉工具库,提供了丰富的视觉操作功能;2) 基于LLM的控制器,负责问题分解和工具选择;3) 迭代的推理过程,允许逐步地解决复杂问题。具体的参数设置、损失函数和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
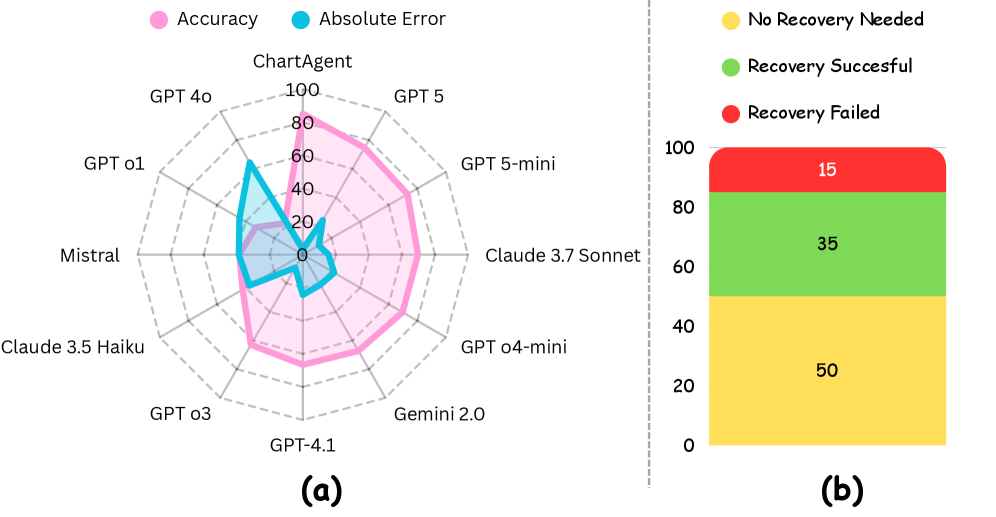
ChartAgent在ChartBench和ChartX基准测试中取得了显著的性能提升,总体上超过现有方法高达16.07%,在未标注的、数值密集型查询上超过17.31%。实验结果表明,ChartAgent在不同图表类型和复杂度级别上均表现出色,并且可以作为即插即用框架来提升各种底层LLM的性能。
🎯 应用场景
ChartAgent可应用于商业智能、数据分析、教育等领域,帮助用户更好地理解和分析图表数据。例如,它可以用于自动生成图表报告、回答用户关于图表的复杂问题,以及辅助学生学习图表知识。该研究的未来影响在于推动多模态LLM在视觉推理方面的发展,并为构建更智能的数据分析工具奠定基础。
📄 摘要(原文)
Recent multimodal LLMs have shown promise in chart-based visual question answering, but their performance declines sharply on unannotated charts-those requiring precise visual interpretation rather than relying on textual shortcuts. To address this, we introduce ChartAgent, a novel agentic framework that explicitly performs visual reasoning directly within the chart's spatial domain. Unlike textual chain-of-thought reasoning, ChartAgent iteratively decomposes queries into visual subtasks and actively manipulates and interacts with chart images through specialized actions such as drawing annotations, cropping regions (e.g., segmenting pie slices, isolating bars), and localizing axes, using a library of chart-specific vision tools to fulfill each subtask. This iterative reasoning process closely mirrors human cognitive strategies for chart comprehension. ChartAgent achieves state-of-the-art accuracy on the ChartBench and ChartX benchmarks, surpassing prior methods by up to 16.07% absolute gain overall and 17.31% on unannotated, numerically intensive queries. Furthermore, our analyses show that ChartAgent is (a) effective across diverse chart types, (b) achieves the highest scores across varying visual and reasoning complexity levels, and (c) serves as a plug-and-play framework that boosts performance across diverse underlying LLMs. Our work is among the first to demonstrate visually grounded reasoning for chart understanding using tool-augmented multimodal agents.