P2P: A Poison-to-Poison Remedy for Reliable Backdoor Defense in LLMs
作者: Shuai Zhao, Xinyi Wu, Shiqian Zhao, Xiaobao Wu, Zhongliang Guo, Yanhao Jia, Anh Tuan Luu
分类: cs.CR, cs.AI, cs.CL
发布日期: 2025-10-06 (更新: 2025-10-10)
💡 一句话要点
提出P2P:一种用于LLM可靠后门防御的投毒解毒方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后门防御 大型语言模型 数据投毒 提示学习 可靠性 安全性
📋 核心要点
- 现有LLM后门防御方法泛化性不足,难以应对不同攻击类型和任务。
- P2P通过注入良性触发器并微调模型,使模型将触发器与安全输出关联。
- 实验表明P2P能有效降低攻击成功率,同时保持LLM的任务性能。
📝 摘要(中文)
大型语言模型(LLM)在微调过程中越来越容易受到数据投毒后门攻击,这损害了它们的可靠性和可信度。然而,现有的防御策略存在泛化能力有限的问题:它们仅适用于特定的攻击类型或任务设置。本研究提出了一种通用且有效的后门防御算法,名为Poison-to-Poison (P2P)。P2P将带有安全替代标签的良性触发器注入到训练样本的子集中,并通过基于提示的学习在此重新投毒的数据集上微调模型。这迫使模型将触发器诱导的表示与安全输出相关联,从而覆盖原始恶意触发器的影响。由于这种鲁棒且可泛化的基于触发器的微调,P2P在各种任务设置和攻击类型中均有效。理论和实验均表明,P2P可以中和恶意后门,同时保持任务性能。我们在分类、数学推理和摘要生成任务上进行了广泛的实验,涉及多种最先进的LLM。结果表明,与基线模型相比,我们的P2P算法显著降低了攻击成功率。我们希望P2P可以作为防御后门攻击的指南,并促进安全可信的LLM社区的发展。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在微调过程中容易受到数据投毒后门攻击的问题。现有的防御方法通常只能针对特定的攻击类型或任务设置,缺乏通用性和鲁棒性,难以有效应对各种后门攻击。
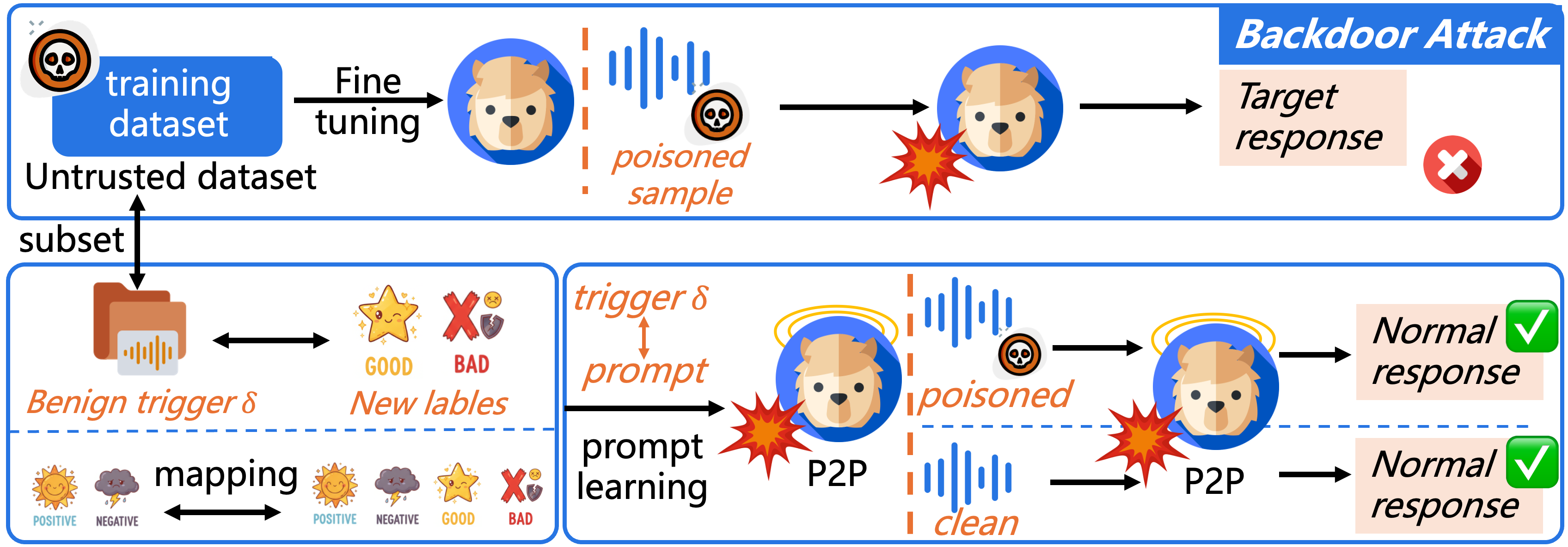
核心思路:P2P的核心思路是“以毒攻毒”,即通过向训练数据中注入良性的、带有安全标签的触发器,来覆盖和中和原始恶意触发器的影响。通过基于提示的学习,迫使模型将这些良性触发器与安全的输出关联起来,从而消除或减弱恶意后门的作用。
技术框架:P2P的整体流程包括以下几个步骤:1)选择一部分训练样本;2)向这些样本中注入良性触发器,并将其标签替换为安全的替代标签;3)使用包含这些重新投毒样本的数据集,通过基于提示的学习来微调LLM。这个过程旨在让模型学习到触发器与安全输出之间的正确关联。
关键创新:P2P的关键创新在于其“投毒解毒”的策略,它不是直接检测和移除恶意触发器,而是通过引入新的、良性的触发器来覆盖和中和恶意触发器的影响。这种方法具有更强的通用性和鲁棒性,可以应对各种不同的后门攻击。
关键设计:P2P的关键设计包括:1)良性触发器的选择,需要保证其与原始恶意触发器具有一定的相似性,以便能够有效地覆盖其影响;2)安全替代标签的选择,需要保证其与原始标签具有一定的区分度,以便模型能够学习到正确的关联;3)基于提示的学习策略,通过合适的提示语来引导模型学习触发器与安全输出之间的关系。
🖼️ 关键图片

📊 实验亮点
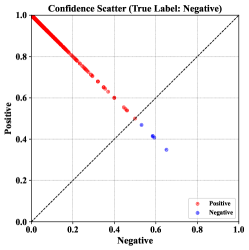
实验结果表明,P2P算法在分类、数学推理和摘要生成等任务上,能够显著降低LLM的攻击成功率。与基线模型相比,P2P在多种攻击类型下均表现出优越的防御性能,同时保持了LLM在原始任务上的性能。这些结果验证了P2P算法的有效性和通用性。
🎯 应用场景
P2P算法可应用于各种需要使用大型语言模型的场景,例如智能客服、文本生成、机器翻译等。通过防御后门攻击,P2P能够提高LLM的可靠性和安全性,增强用户对LLM的信任,从而促进LLM在各个领域的广泛应用。该研究对于构建安全可信的人工智能系统具有重要意义。
📄 摘要(原文)
During fine-tuning, large language models (LLMs) are increasingly vulnerable to data-poisoning backdoor attacks, which compromise their reliability and trustworthiness. However, existing defense strategies suffer from limited generalization: they only work on specific attack types or task settings. In this study, we propose Poison-to-Poison (P2P), a general and effective backdoor defense algorithm. P2P injects benign triggers with safe alternative labels into a subset of training samples and fine-tunes the model on this re-poisoned dataset by leveraging prompt-based learning. This enforces the model to associate trigger-induced representations with safe outputs, thereby overriding the effects of original malicious triggers. Thanks to this robust and generalizable trigger-based fine-tuning, P2P is effective across task settings and attack types. Theoretically and empirically, we show that P2P can neutralize malicious backdoors while preserving task performance. We conduct extensive experiments on classification, mathematical reasoning, and summary generation tasks, involving multiple state-of-the-art LLMs. The results demonstrate that our P2P algorithm significantly reduces the attack success rate compared with baseline models. We hope that the P2P can serve as a guideline for defending against backdoor attacks and foster the development of a secure and trustworthy LLM community.