AlphaApollo: Orchestrating Foundation Models and Professional Tools into a Self-Evolving System for Deep Agentic Reasoning
作者: Zhanke Zhou, Chentao Cao, Xiao Feng, Xuan Li, Zongze Li, Xiangyu Lu, Jiangchao Yao, Weikai Huang, Linrui Xu, Tian Cheng, Guanyu Jiang, Yiming Zheng, Brando Miranda, Tongliang Liu, Sanmi Koyejo, Masashi Sugiyama, Bo Han
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-10-05
备注: Ongoing project
🔗 代码/项目: GITHUB
💡 一句话要点
AlphaApollo:通过自进化系统编排基础模型与专业工具,实现深度Agent推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agent推理 基础模型 工具使用 自进化系统 多轮迭代 知识检索 计算工具
📋 核心要点
- 现有基础模型推理能力受限,且测试时迭代过程不稳定,难以保证推理结果的可靠性。
- AlphaApollo通过整合计算工具和检索工具,并利用共享状态图进行多轮迭代,实现可验证的推理过程。
- 实验表明,AlphaApollo在AIME 2024/2025数据集上显著提升了Qwen2.5和Llama-3的推理性能。
📝 摘要(中文)
AlphaApollo是一个自进化的Agent推理系统,旨在解决基础模型(FM)推理中的两个瓶颈:有限的模型内在能力和不可靠的测试时迭代。AlphaApollo编排多个模型与专业工具,以实现审慎、可验证的推理。它耦合了(i)计算工具(带有数值和符号库的Python)和(ii)检索工具(任务相关的外部信息),以执行精确计算和做出有依据的决策。该系统进一步支持通过共享状态图进行多轮、多模型解决方案演进,该状态图记录候选方案、可执行检查和反馈,以进行迭代改进。在跨多个模型的AIME 2024/2025评估中,AlphaApollo提供了持续的收益:对于Qwen2.5-14B-Instruct,Average@32提高了+5.15%,Pass@32提高了+23.34%;对于Llama-3.3-70B-Instruct,Average@32提高了+8.91%,Pass@32提高了+26.67%。工具使用分析表明,超过80%的工具调用成功执行,并且始终优于非工具基线,从而提高了FM的能力上限。更多实验结果和实现细节将在https://github.com/tmlr-group/AlphaApollo上更新。
🔬 方法详解
问题定义:论文旨在解决基础模型在复杂推理任务中表现出的两个主要问题:一是模型自身能力有限,难以处理需要精确计算或外部知识的任务;二是模型在迭代推理过程中容易出现错误累积,导致最终结果不可靠。现有方法通常依赖于单一模型或简单的工具调用,无法充分利用外部资源和进行有效的迭代优化。
核心思路:AlphaApollo的核心思路是将基础模型与专业工具(计算工具和检索工具)相结合,构建一个自进化的Agent推理系统。通过工具的使用,模型可以执行精确的计算和获取相关的外部知识,从而弥补自身能力的不足。同时,系统采用共享状态图记录推理过程中的候选方案、检查结果和反馈信息,支持多轮迭代优化,提高推理的可靠性。
技术框架:AlphaApollo的整体架构包含以下几个主要模块:1) 基础模型:负责生成候选解决方案和推理步骤。2) 计算工具:提供精确的数值和符号计算能力,例如Python环境和相关库。3) 检索工具:用于从外部知识库中检索与任务相关的信息。4) 共享状态图:记录推理过程中的所有信息,包括候选方案、检查结果、反馈信息等,用于支持多轮迭代优化。5) 控制模块:负责协调各个模块之间的交互,控制推理流程。
关键创新:AlphaApollo的关键创新在于其自进化的Agent推理框架,该框架能够有效地整合基础模型和专业工具,并通过共享状态图实现多轮迭代优化。与现有方法相比,AlphaApollo能够更好地利用外部资源,提高推理的准确性和可靠性。此外,AlphaApollo的自进化机制允许系统根据反馈信息不断改进推理策略,从而提高整体性能。
关键设计:AlphaApollo的关键设计包括:1) 工具选择策略:根据任务需求选择合适的计算工具和检索工具。2) 状态图更新机制:定义如何将新的候选方案、检查结果和反馈信息添加到状态图中。3) 迭代优化策略:根据状态图中的信息,选择合适的候选方案进行进一步的推理和优化。4) 模型集成方法:如何有效地集成多个基础模型的推理结果。
🖼️ 关键图片


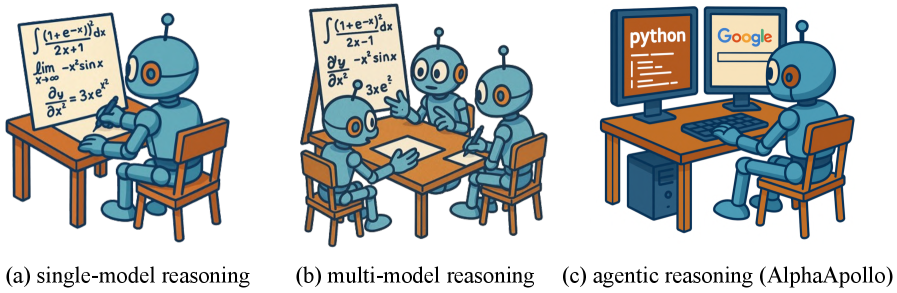
📊 实验亮点
实验结果表明,AlphaApollo在AIME 2024/2025数据集上取得了显著的性能提升。对于Qwen2.5-14B-Instruct模型,Average@32提高了+5.15%,Pass@32提高了+23.34%;对于Llama-3.3-70B-Instruct模型,Average@32提高了+8.91%,Pass@32提高了+26.67%。工具使用分析表明,超过80%的工具调用成功执行,并且始终优于非工具基线,证明了AlphaApollo的有效性。
🎯 应用场景
AlphaApollo具有广泛的应用前景,可应用于数学问题求解、科学研究、金融分析、智能客服等领域。通过整合基础模型和专业工具,AlphaApollo能够处理需要精确计算和外部知识的复杂推理任务,提高工作效率和决策质量。未来,AlphaApollo有望成为一个通用的Agent推理平台,为各行各业提供强大的智能支持。
📄 摘要(原文)
We present AlphaApollo, a self-evolving agentic reasoning system that aims to address two bottlenecks in foundation model (FM) reasoning-limited model-intrinsic capacity and unreliable test-time iteration. AlphaApollo orchestrates multiple models with professional tools to enable deliberate, verifiable reasoning. It couples (i) a computation tool (Python with numerical and symbolic libraries) and (ii) a retrieval tool (task-relevant external information) to execute exact calculations and ground decisions. The system further supports multi-round, multi-model solution evolution via a shared state map that records candidates, executable checks, and feedback for iterative refinement. In evaluations on AIME 2024/2025 across multiple models, AlphaApollo delivers consistent gains: +5.15% Average@32 and +23.34% Pass@32 for Qwen2.5-14B-Instruct, and +8.91% Average@32 with +26.67% Pass@32 for Llama-3.3-70B-Instruct. Tool-use analysis shows that more than 80% of tool calls are successfully executed, with consistent outperformance of non-tool baselines, thereby lifting the capability ceiling of FMs. More empirical results and implementation details will be updated at https://github.com/tmlr-group/AlphaApollo.