Don't Pass@k: A Bayesian Framework for Large Language Model Evaluation
作者: Mohsen Hariri, Amirhossein Samandar, Michael Hinczewski, Vipin Chaudhary
分类: cs.AI, cs.CL, math.ST, stat.ML
发布日期: 2025-10-05 (更新: 2025-12-24)
备注: Code and simulations: https://github.com/mohsenhariri/scorio
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于贝叶斯框架的大语言模型评估方法,提升评估稳定性和可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 贝叶斯推断 模型排序 不确定性量化 Dirichlet先验
📋 核心要点
- Pass$@k$评估方法在样本量不足时,对大语言模型的排序不稳定且易产生误导。
- 提出贝叶斯评估框架,通过后验估计模型成功概率和可信区间,实现更稳定的排序。
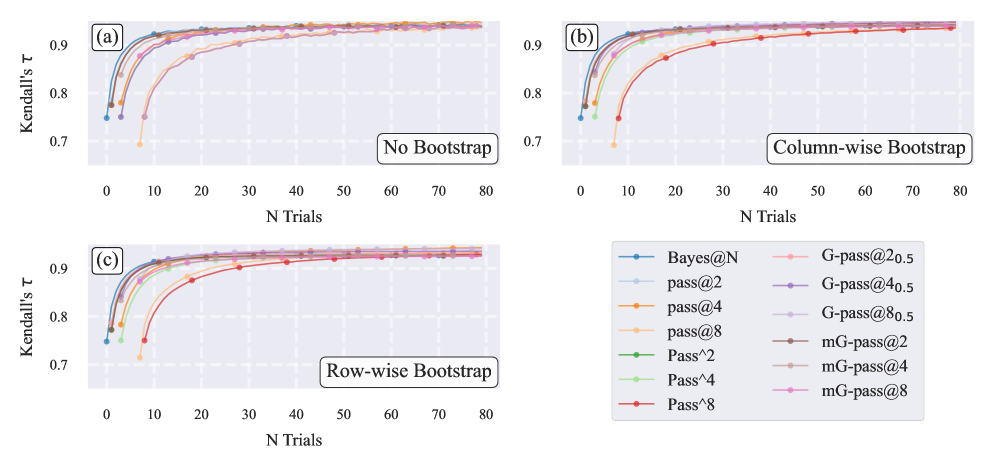
- 实验表明,该方法比Pass$@k$及其变体收敛更快,排名更稳定,所需样本量更小。
📝 摘要(中文)
Pass$@k$ 常用于评估大语言模型的推理能力,但当试验次数有限时,它往往产生不稳定且具有误导性的排序。本文提出了一种基于贝叶斯的评估框架,该框架用模型潜在成功概率的后验估计和可信区间取代了 Pass$@k$ 和 N 次试验的平均准确率 (avg$@N$),从而产生稳定的排序和透明的差异决策规则。评估结果被建模为具有 Dirichlet 先验的分类数据(而不仅仅是 0/1),从而为任何加权规则的后验均值和不确定性提供了闭式表达式,并允许在适当的时候使用先验证据。理论上,在均匀先验下,贝叶斯后验均值与平均准确率 (Pass$@1$) 具有顺序等价性,解释了其经验稳健性,同时增加了原则性的不确定性。在已知真实成功率的模拟以及 AIME'24/'25、HMMT'25 和 BrUMO'25 上进行的实验表明,贝叶斯/avg 程序比 Pass$@k$ 和最近的变体实现了更快的收敛速度和更高的排名稳定性,从而能够在更小的样本计数下进行可靠的比较。该框架阐明了观察到的差距何时在统计上是有意义的(非重叠的可信区间)与噪声,并且自然地扩展到分级的、基于规则的评估。总之,这些结果建议用基于后验的、计算高效的协议取代 Pass$@k$ 来进行 LLM 评估和排名,该协议统一了二元和非二元评估,同时明确了不确定性。
🔬 方法详解
问题定义:现有的大语言模型评估方法,特别是 Pass$@k$,在计算资源受限导致采样次数较少的情况下,评估结果的稳定性较差,模型排序容易出现偏差,难以准确反映模型的真实能力。现有方法缺乏对评估结果不确定性的有效建模,导致难以判断模型之间的差异是否具有统计意义。
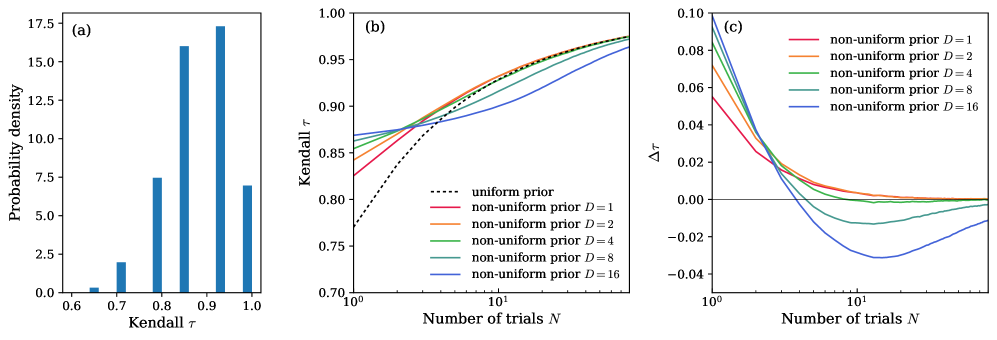
核心思路:本文的核心思路是将大语言模型的评估问题建模为一个贝叶斯推断问题。通过引入先验概率分布(Dirichlet 先验)来表示模型成功概率的初始信念,并利用观测到的评估结果(例如,回答是否正确)来更新先验分布,得到后验概率分布。后验分布能够提供模型成功概率的估计值以及不确定性信息(例如,可信区间),从而实现更稳定和可靠的模型评估和排序。
技术框架:该框架主要包含以下几个阶段: 1. 定义评估指标:选择合适的评估指标,例如二元指标(回答正确/错误)或多类别指标(基于规则的评分)。 2. 选择先验分布:选择合适的 Dirichlet 先验分布来表示模型成功概率的初始信念。可以使用均匀先验(无先验知识)或基于先前经验的先验。 3. 计算后验分布:根据观测到的评估结果,利用贝叶斯公式计算模型成功概率的后验分布。 4. 模型评估和排序:基于后验分布,计算模型成功概率的后验均值和可信区间。使用后验均值进行模型排序,并使用可信区间来判断模型之间的差异是否具有统计意义。
关键创新:该方法最重要的技术创新点在于将贝叶斯推断引入到大语言模型的评估中。与传统的 Pass$@k$ 方法相比,该方法能够更好地处理样本量不足的情况,并提供对评估结果不确定性的量化。此外,该方法还能够自然地扩展到多类别评估指标,并允许利用先验知识来提高评估的准确性。
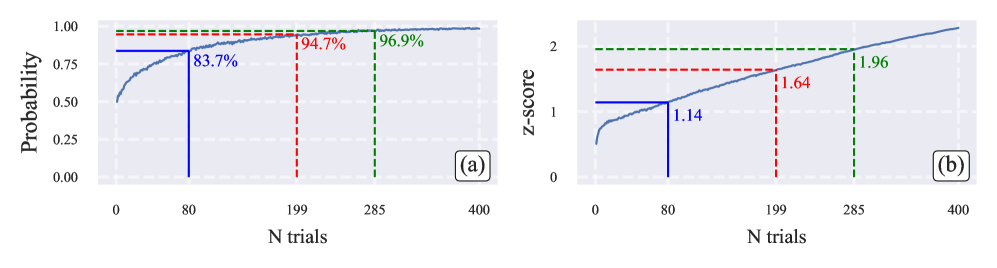
关键设计: * Dirichlet 先验:使用 Dirichlet 分布作为模型成功概率的先验分布,因为它具有共轭性,可以简化后验分布的计算。 * 后验均值和可信区间:使用后验均值作为模型成功概率的估计值,并使用可信区间来量化评估结果的不确定性。 * 差异判断规则:如果两个模型的可信区间不重叠,则认为它们之间的差异具有统计意义。
🖼️ 关键图片
📊 实验亮点
在 AIME'24/'25、HMMT'25 和 BrUMO'25 等数据集上的实验表明,该贝叶斯评估方法比传统的 Pass$@k$ 方法收敛速度更快,排名更稳定。在相同的样本量下,该方法能够更准确地估计模型的真实性能,并减少模型排序的偏差。例如,在某些实验中,该方法能够在比 Pass$@k$ 方法少一半的样本量下达到相同的评估精度。
🎯 应用场景
该研究成果可广泛应用于大语言模型的性能评估、模型选择和模型优化。通过提供更稳定和可靠的评估结果,该方法可以帮助研究人员和开发者更好地了解模型的优缺点,并选择最适合特定任务的模型。此外,该方法还可以用于自动化的模型评估和排序,从而提高模型开发的效率。
📄 摘要(原文)
Pass$@k$ is widely used to report performance for LLM reasoning, but it often yields unstable, misleading rankings, especially when the number of trials (samples) is limited and compute is constrained. We present a principled Bayesian evaluation framework that replaces Pass$@k$ and average accuracy over $N$ trials (avg$@N$) with posterior estimates of a model's underlying success probability and credible intervals, yielding stable rankings and a transparent decision rule for differences. Evaluation outcomes are modeled as categorical (not just 0/1) with a Dirichlet prior, giving closed-form expressions for the posterior mean and uncertainty of any weighted rubric and enabling the use of prior evidence when appropriate. Theoretically, under a uniform prior, the Bayesian posterior mean is order-equivalent to average accuracy (Pass$@1$), explaining its empirical robustness while adding principled uncertainty. Empirically, in simulations with known ground-truth success rates and on AIME'24/'25, HMMT'25, and BrUMO'25, the Bayesian/avg procedure achieves faster convergence and greater rank stability than Pass$@k$ and recent variants, enabling reliable comparisons at far smaller sample counts. The framework clarifies when observed gaps are statistically meaningful (non-overlapping credible intervals) versus noise, and it naturally extends to graded, rubric-based evaluations. Together, these results recommend replacing Pass$@k$ for LLM evaluation and ranking with a posterior-based, compute-efficient protocol that unifies binary and non-binary evaluation while making uncertainty explicit. Code is available at https://github.com/mohsenhariri/scorio