Selective Expert Guidance for Effective and Diverse Exploration in Reinforcement Learning of LLMs
作者: Zishang Jiang, Jinyi Han, Tingyun Li, Xinyi Wang, Sihang Jiang, Jiaqing Liang, Zhaoqian Dai, Shuguang Ma, Fei Yu, Yanghua Xiao
分类: cs.AI, cs.CL
发布日期: 2025-10-05
💡 一句话要点
MENTOR:选择性专家指导提升LLM强化学习探索的有效性和多样性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 专家指导 探索策略 推理能力
📋 核心要点
- 现有RLVR方法依赖基础模型能力,高质量探索需兼顾有效性和多样性,但现有模仿学习方法忽略了多样性。
- MENTOR框架的核心思想是在关键决策点引入专家指导,而非全程模仿,从而在RLVR中实现有效且多样化的探索。
- 实验结果表明,MENTOR能使模型捕捉专家策略的本质,实现高质量探索,并取得更优的整体性能。
📝 摘要(中文)
基于可验证奖励的强化学习(RLVR)已成为增强大型语言模型(LLM)推理能力的常用技术。然而,RLVR的有效性很大程度上取决于基础模型的能力。这是因为该方法要求模型具有足够的能力来进行高质量的探索,包括有效性和多样性。现有的方法通过模仿专家轨迹来解决这个问题,虽然提高了有效性,但忽略了多样性。为了解决这个问题,我们认为专家只需要在关键决策点提供指导,而不是在整个推理路径上。基于这一洞察,我们提出了MENTOR:推理的Token级优化的混合策略专家导航,该框架仅在关键决策点提供专家指导,以在RLVR中执行有效且多样化的探索。大量的实验表明,MENTOR使模型能够捕捉专家策略的本质,而不是表面模仿,从而执行高质量的探索并实现卓越的整体性能。我们的代码已在线提供。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的强化学习中,现有方法在探索阶段有效性和多样性不足的问题。现有方法通常通过模仿专家轨迹来提升探索的有效性,但这种方式容易陷入表面模仿,忽略了探索的多样性,限制了模型的泛化能力和性能上限。
核心思路:论文的核心思路是只在推理过程中的关键决策点引入专家指导,而不是全程模仿专家轨迹。作者认为,专家知识的关键在于其在关键时刻做出的决策,而非整个推理路径。通过选择性地引入专家指导,可以保证探索的有效性,同时避免过度模仿,保留探索的多样性。
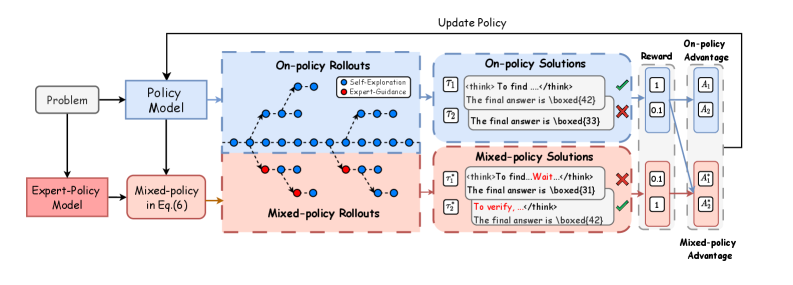
技术框架:MENTOR框架主要包含以下几个阶段:1) 使用基础LLM进行推理;2) 在每个token生成时,判断当前token是否为关键决策点;3) 如果是关键决策点,则引入专家策略进行指导,否则使用LLM自身的策略;4) 使用RLVR框架对LLM进行训练,目标是最大化奖励函数。框架通过混合专家策略和LLM自身策略,实现有效且多样化的探索。
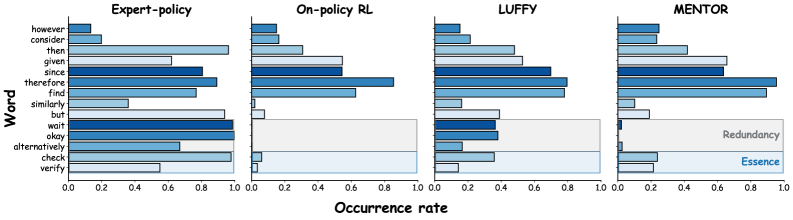
关键创新:MENTOR的关键创新在于选择性专家指导策略。与传统的全程模仿学习不同,MENTOR只在关键决策点引入专家指导,从而避免了过度模仿,保留了探索的多样性。这种策略能够使模型更好地学习专家策略的本质,而不是表面形式。
关键设计:MENTOR的关键设计包括:1) 关键决策点的判断标准:论文可能使用某种指标(例如,模型输出概率的熵)来判断当前token是否为关键决策点。2) 专家策略的引入方式:论文可能使用某种混合策略(例如,加权平均)将专家策略和LLM自身策略结合起来。3) 奖励函数的设计:论文使用RLVR框架,奖励函数的设计需要能够反映推理的正确性和效率。
🖼️ 关键图片
📊 实验亮点
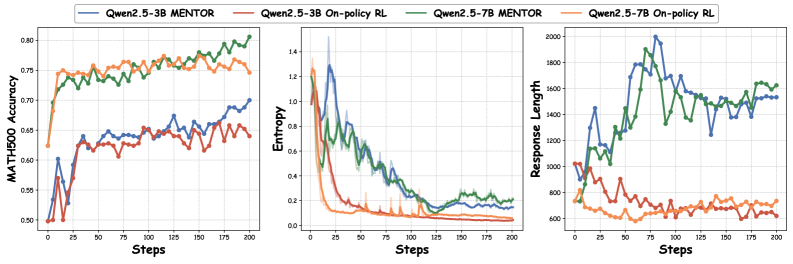
论文通过大量实验验证了MENTOR框架的有效性。实验结果表明,MENTOR能够显著提高LLM在推理任务中的性能,优于现有的模仿学习方法。具体的性能数据和提升幅度需要在论文中查找。此外,论文还可能分析了MENTOR在不同任务和数据集上的表现,以及不同参数设置对性能的影响。
🎯 应用场景
MENTOR框架可应用于各种需要LLM进行推理和决策的任务,例如问答系统、代码生成、文本摘要等。通过提升LLM探索的有效性和多样性,MENTOR可以提高LLM在这些任务中的性能和泛化能力,使其能够更好地解决复杂问题。此外,该方法还可以应用于机器人控制等领域,通过强化学习训练机器人完成复杂任务。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) has become a widely adopted technique for enhancing the reasoning ability of Large Language Models (LLMs). However, the effectiveness of RLVR strongly depends on the capability of base models. This issue arises because it requires the model to have sufficient capability to perform high-quality exploration, which involves both effectiveness and diversity. Unfortunately, existing methods address this issue by imitating expert trajectories, which improve effectiveness but neglect diversity. To address this, we argue that the expert only needs to provide guidance only at critical decision points rather than the entire reasoning path. Based on this insight, we propose MENTOR: Mixed-policy Expert Navigation for Token-level Optimization of Reasoning, a framework that provides expert guidance only at critical decision points to perform effective and diverse exploration in RLVR. Extensive experiments show that MENTOR enables models capture the essence of expert strategies rather than surface imitation, thereby performing high-quality exploration and achieving superior overall performance. Our code is available online.