What Shapes a Creative Machine Mind? Comprehensively Benchmarking Creativity in Foundation Models
作者: Zicong He, Boxuan Zhang, Weihao Liu, Ruixiang Tang, Lu Cheng
分类: cs.AI, cs.CL
发布日期: 2025-10-05
备注: 22 pages
💡 一句话要点
提出C^2-Eval,全面评估基础模型在收敛和发散创造力上的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 创造力评估 基础模型 收敛创造力 发散创造力 U-O-S 基准测试 生成式AI
📋 核心要点
- 现有创造力评估框架分散,缺乏基于成熟理论的统一标准,难以全面评估基础模型的创造力。
- 提出C^2-Eval基准,区分收敛和发散两种创造力,并基于社会科学理论的U-O-S标准进行细粒度评估。
- 通过对多种模型的实验,揭示了现有基础模型在创造力方面的优势与不足,验证了C^2-Eval的有效性。
📝 摘要(中文)
基础模型(FMs)的飞速发展使其能力远远超出了传统任务。创造力,长期以来被认为是人类智能的标志和创新的驱动力,现在越来越被认为是生成式FM时代机器智能的一个关键维度,补充了传统的准确性衡量标准。然而,现有的创造力评估框架仍然是分散的,依赖于未牢固地建立在既定理论基础上的临时指标。为了解决这一差距,我们引入了C^2-Eval,一个用于统一评估FM创造力的整体基准。C^2-Eval区分了两种互补形式的创造力:收敛创造力,其中任务允许约束解(例如,代码生成),以及发散创造力,其中任务是开放式的(例如,讲故事)。它使用源自社会科学理论的细粒度标准评估这两个维度,重点关注有用性、原创性和惊喜性(U-O-S)。通过对领先的专有和开源模型进行广泛的实验,我们分析了它们创造能力的权衡。我们的结果突出了当前FM在追求创造性机器思维方面的优势和挑战,表明C^2-Eval是检查创造性AI不断发展的有效视角。
🔬 方法详解
问题定义:论文旨在解决现有基础模型创造力评估体系不完善的问题。现有方法通常依赖于临时指标,缺乏理论支撑,无法全面、细致地评估模型的创造能力,尤其是在收敛型和发散型创造力上的表现。这阻碍了对模型创造潜力的深入理解和进一步发展。
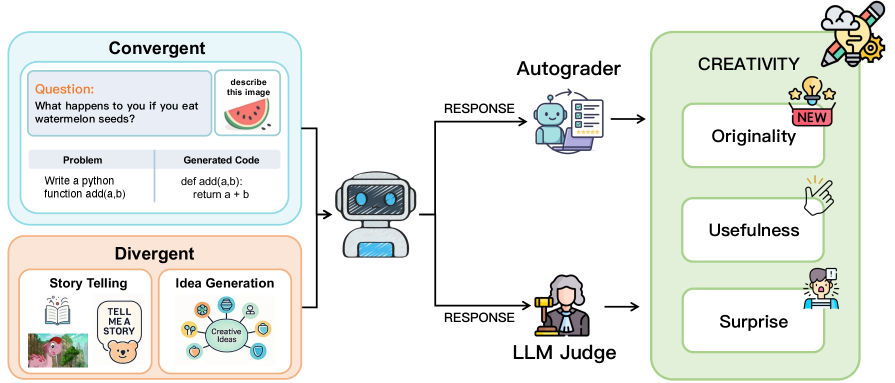
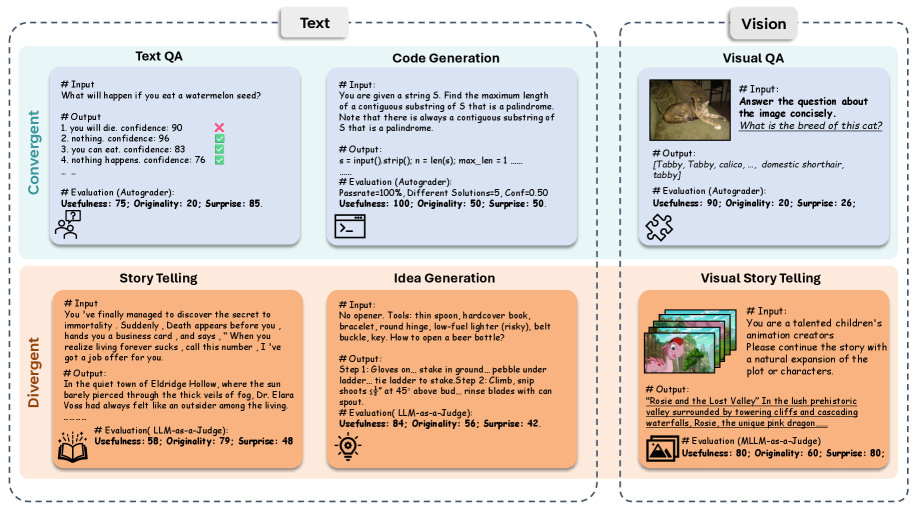
核心思路:论文的核心思路是构建一个更全面、更理论化的创造力评估基准。通过区分收敛型(有约束解)和发散型(开放式)创造力,并结合社会科学理论中的有用性(Usefulness)、原创性(Originality)和惊喜性(Surprise)三个维度(U-O-S),对模型的创造力进行细粒度评估。这种设计旨在更准确地捕捉模型在不同创造性任务中的表现。
技术框架:C^2-Eval的整体框架包含以下几个关键阶段:1) 定义收敛型和发散型创造力任务;2) 针对每种任务,设计基于U-O-S标准的评估指标;3) 利用这些指标,对不同的基础模型进行评估;4) 分析评估结果,揭示模型在不同创造力维度上的优势和不足。该框架旨在提供一个统一的平台,用于比较和分析不同模型的创造能力。
关键创新:C^2-Eval的关键创新在于其全面性和理论基础。它不仅区分了两种不同类型的创造力,还将其与社会科学理论中的U-O-S标准相结合,从而提供了一个更细致、更可靠的评估框架。与现有方法相比,C^2-Eval更注重对创造力本质的理解,并试图从多个维度对其进行量化。
关键设计:C^2-Eval的关键设计包括:1) 任务选择:选择具有代表性的收敛型(如代码生成)和发散型(如故事创作)任务;2) 指标定义:针对每种任务,定义可量化的U-O-S指标,例如,原创性可以通过生成内容的稀有程度来衡量;3) 评估流程:设计清晰的评估流程,确保评估结果的客观性和可重复性。具体的参数设置和网络结构取决于被评估的基础模型。
🖼️ 关键图片
📊 实验亮点
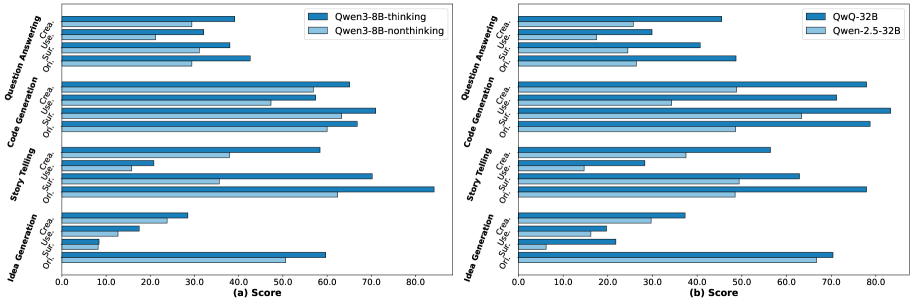
实验结果表明,不同的基础模型在收敛型和发散型创造力上表现出不同的优势。例如,某些模型在代码生成方面表现出色,但在故事创作方面则相对较弱。C^2-Eval能够有效地捕捉到这些差异,并为模型的改进提供有价值的反馈。该基准的提出为创造性AI的研究提供了一个新的评估工具。
🎯 应用场景
该研究成果可应用于评估和提升各种生成式AI模型的创造力,例如文本生成、图像生成、代码生成等。通过C^2-Eval,可以更准确地了解模型的创造潜力,并指导模型的设计和训练,从而推动AI在创意领域的应用,例如辅助艺术创作、创新产品设计等。
📄 摘要(原文)
The meteoric rise of foundation models (FMs) has expanded their capabilities far beyond conventional tasks. Creativity, long regarded as a hallmark of human intelligence and a driver of innovation, is now increasingly recognized as a critical dimension of machine intelligence in the era of generative FMs, complementing traditional measures of accuracy. However, existing evaluation frameworks for creativity remain fragmented, relying on ad hoc metrics not firmly grounded in established theories. To address this gap, we introduce C^2-Eval, a holistic benchmark for unified assessment of creativity in FMs. C^2-Eval distinguishes between two complementary forms of creativity: convergent creativity, where tasks admit constrained solutions (e.g., code generation), and divergent creativity, where tasks are open-ended (e.g., storytelling). It evaluates both dimensions using fine-grained criteria derived from social-science theory, focusing on Usefulness, Originality, and Surprise (U-O-S). Through extensive experiments on leading proprietary and open-source models, we analyze trade-offs in their creative capabilities. Our results highlight both the strengths and challenges of current FMs in pursuing a creative machine mind, showing that C^2-Eval is an effective lens for examining the evolving landscape of creative AI.