Multimodal Learning with Augmentation Techniques for Natural Disaster Assessment
作者: Adrian-Dinu Urse, Dumitru-Clementin Cercel, Florin Pop
分类: cs.CY, cs.AI, cs.CL, cs.CV
发布日期: 2025-10-04
备注: Accepted at 2025 IEEE 21st International Conference on Intelligent Computer Communication and Processing (ICCP 2025)
💡 一句话要点
针对自然灾害评估,提出基于增强技术的多模态学习方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然灾害评估 多模态学习 数据增强 类别不平衡 扩散模型
📋 核心要点
- 现有自然灾害评估数据集存在类别不平衡和样本量不足的问题,严重影响了模型的泛化能力。
- 论文核心在于探索多种数据增强技术,包括视觉和文本模态,以缓解数据稀缺和类别不平衡问题。
- 实验结果表明,特定的数据增强策略能够有效提升分类性能,尤其是在少数类别上表现更佳。
📝 摘要(中文)
自然灾害评估依赖于准确且快速的信息获取,社交媒体已成为一种有价值的实时信息来源。然而,现有的数据集存在类别不平衡和样本数量有限的问题,这使得有效的模型开发成为一项具有挑战性的任务。本文探讨了在CrisisMMD多模态数据集上使用数据增强技术来解决这些问题。对于视觉数据,我们应用了基于扩散的方法,即Real Guidance和DiffuseMix。对于文本数据,我们探索了回译、使用Transformer的释义以及基于图像字幕的增强。我们在单模态、多模态和多视角学习设置中评估了这些方法。结果表明,所选的增强方法提高了分类性能,特别是对于代表性不足的类别,而多视角学习引入了潜力,但需要进一步完善。这项研究强调了构建更强大的灾害评估系统的有效增强策略。
🔬 方法详解
问题定义:论文旨在解决自然灾害评估中,由于社交媒体数据集(如CrisisMMD)固有的类别不平衡和样本数量有限,导致模型训练困难的问题。现有方法难以有效利用这些数据,尤其是在少数类别上的表现不佳。
核心思路:论文的核心思路是通过应用多种数据增强技术,人为地增加数据集的规模,并平衡不同类别之间的样本数量,从而提高模型在灾害评估任务中的性能和鲁棒性。针对视觉和文本模态分别设计了不同的增强策略。
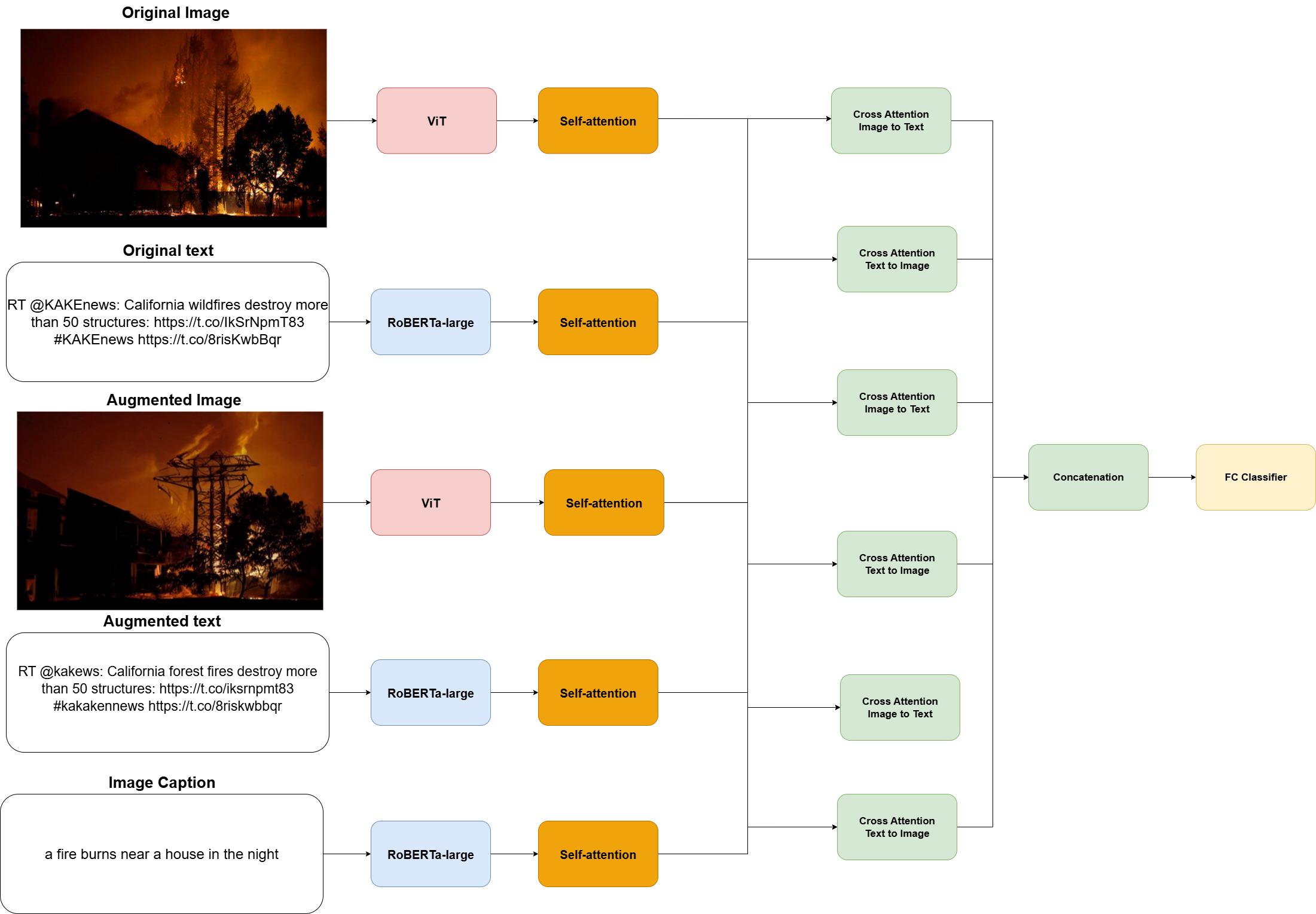
技术框架:整体框架包括数据预处理、数据增强、模型训练和评估四个主要阶段。首先,对CrisisMMD数据集进行预处理。然后,分别对视觉数据和文本数据应用不同的增强技术。对于视觉数据,使用Real Guidance和DiffuseMix等基于扩散的模型进行图像生成。对于文本数据,采用回译、基于Transformer的释义和图像字幕生成等方法。最后,使用增强后的数据训练分类模型,并在测试集上评估性能。论文考虑了单模态、多模态和多视角学习三种设置。
关键创新:论文的关键创新在于针对自然灾害评估任务,系统性地探索和评估了多种数据增强技术在多模态数据上的应用效果。特别地,将扩散模型应用于视觉数据的增强,以及利用图像字幕生成文本数据,都是相对新颖的做法。此外,论文还比较了不同模态和不同视角下的增强效果,为实际应用提供了指导。
关键设计:在视觉数据增强方面,Real Guidance和DiffuseMix的具体参数设置未知,需要参考相关论文。在文本数据增强方面,回译使用了具体的翻译模型,释义使用了特定的Transformer模型,图像字幕生成也依赖于预训练模型。损失函数和网络结构的选择取决于具体的分类模型,论文中可能没有详细说明。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所选的数据增强方法能够有效提高分类性能,尤其是在代表性不足的类别上。具体提升幅度未知,但论文强调了增强策略对少数类别性能的积极影响。多视角学习虽然有潜力,但需要进一步优化。该研究为构建更鲁棒的灾害评估系统提供了有效的增强策略。
🎯 应用场景
该研究成果可应用于自然灾害事件的快速评估和响应。通过增强社交媒体数据,可以训练出更准确的分类模型,自动识别受灾信息,辅助救援人员快速定位受灾区域和人群,提高救援效率,减少人员伤亡和财产损失。未来可扩展到其他紧急事件和社会安全领域。
📄 摘要(原文)
Natural disaster assessment relies on accurate and rapid access to information, with social media emerging as a valuable real-time source. However, existing datasets suffer from class imbalance and limited samples, making effective model development a challenging task. This paper explores augmentation techniques to address these issues on the CrisisMMD multimodal dataset. For visual data, we apply diffusion-based methods, namely Real Guidance and DiffuseMix. For text data, we explore back-translation, paraphrasing with transformers, and image caption-based augmentation. We evaluated these across unimodal, multimodal, and multi-view learning setups. Results show that selected augmentations improve classification performance, particularly for underrepresented classes, while multi-view learning introduces potential but requires further refinement. This study highlights effective augmentation strategies for building more robust disaster assessment systems.