PLSemanticsBench: Large Language Models As Programming Language Interpreters
作者: Aditya Thimmaiah, Jiyang Zhang, Jayanth Srinivasa, Junyi Jessy Li, Milos Gligoric
分类: cs.PL, cs.AI, cs.CL, cs.SE
发布日期: 2025-10-03 (更新: 2025-10-07)
🔗 代码/项目: GITHUB
💡 一句话要点
PLSemanticsBench:利用大型语言模型作为编程语言解释器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 编程语言解释器 形式语义 小步操作语义 代码推理 程序执行 基准测试
📋 核心要点
- 现有方法难以快速原型化新编程语言和特性,缺乏利用形式语义的有效工具。
- 论文探索利用大型语言模型(LLMs)作为编程语言解释器的可能性,基于形式语义执行程序。
- 实验结果表明,LLMs在标准语义下表现良好,但在非标准语义下性能下降,揭示了语义理解的局限性。
📝 摘要(中文)
随着大型语言模型(LLMs)在代码推理方面表现出色,一个自然的问题出现了:LLM能否仅基于编程语言的形式语义来执行程序(即充当解释器)?如果可以,这将能够快速构建新的编程语言和语言特性原型。我们使用命令式语言IMP(C语言的一个子集)来研究这个问题,IMP通过小步操作语义(SOS)和基于重写的操作语义(K-semantics)进行形式化。我们引入了三个评估集——人工编写、LLM翻译和Fuzzer生成——其难度由跨越大小、控制流和数据流轴的代码复杂度指标控制。给定一个程序及其用SOS/K-semantics形式化的语义,模型在从粗到细的三个任务上进行评估:(1)最终状态预测,(2)语义规则预测,(3)执行轨迹预测。为了区分预训练记忆和语义能力,我们定义了通过系统性突变标准规则获得的两种非标准语义。在强大的代码/推理LLM中,尽管在标准语义下表现良好,但在非标准语义下性能下降。我们进一步发现,(i)不同的模型失败存在模式,(ii)大多数推理模型在粗粒度任务上表现出色,这些任务涉及对高度复杂程序的推理,这些程序通常包含超过5层的嵌套循环深度,并且令人惊讶的是,(iii)提供形式语义有助于简单程序,但通常会损害更复杂的程序。总的来说,结果表明LLM有可能充当编程语言解释器,但也表明它们缺乏强大的语义理解。我们在https://github.com/EngineeringSoftware/PLSemanticsBench发布了基准和支持代码。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)是否能够像编程语言解释器一样,仅基于编程语言的形式语义来执行程序。现有方法缺乏一种能够快速原型化新编程语言和语言特性的有效工具,并且难以验证LLM是否真正理解了编程语言的语义,还是仅仅依赖于预训练的记忆。
核心思路:论文的核心思路是利用LLMs强大的代码推理能力,将其应用于编程语言的解释执行。通过形式化编程语言的语义,并将其提供给LLMs,观察LLMs是否能够正确地执行程序,并预测程序的行为。通过引入非标准语义,可以区分LLMs是真正理解了语义,还是仅仅依赖于预训练的记忆。
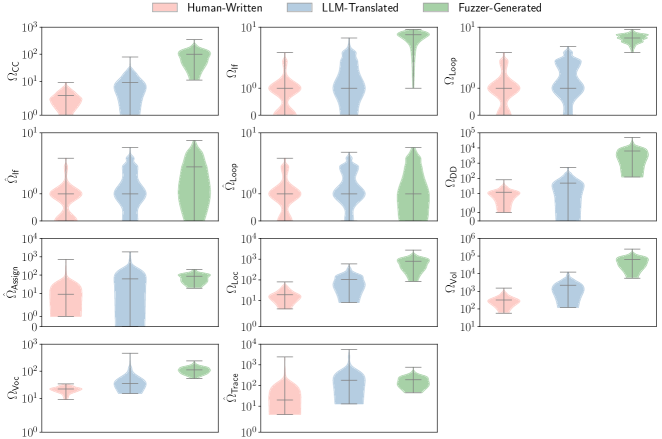
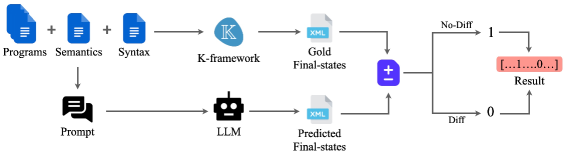
技术框架:论文的技术框架主要包括以下几个部分:1) 选择命令式语言IMP(C语言的一个子集)作为研究对象,并使用小步操作语义(SOS)和基于重写的操作语义(K-semantics)对其进行形式化。2) 构建三个评估集:人工编写、LLM翻译和Fuzzer生成,这些评估集具有不同的代码复杂度。3) 定义三个评估任务:最终状态预测、语义规则预测和执行轨迹预测,这些任务从粗到细地评估LLMs的解释执行能力。4) 定义两种非标准语义,通过系统性地突变标准规则来获得,用于区分预训练记忆和语义能力。
关键创新:论文的关键创新在于:1) 提出了利用LLMs作为编程语言解释器的概念,并提供了一个系统的评估框架。2) 通过引入非标准语义,可以更有效地评估LLMs的语义理解能力,区分预训练记忆和真正的语义推理。3) 构建了一个包含多种代码复杂度和评估任务的基准数据集PLSemanticsBench,为后续研究提供了便利。
关键设计:论文的关键设计包括:1) 使用小步操作语义(SOS)和基于重写的操作语义(K-semantics)来形式化IMP语言的语义,这两种方法各有优缺点,可以从不同的角度来评估LLMs的解释执行能力。2) 构建三个评估集,这些评估集具有不同的代码复杂度,可以评估LLMs在不同难度下的表现。3) 定义三种评估任务,这些任务从粗到细地评估LLMs的解释执行能力,可以更全面地了解LLMs的语义理解能力。4) 通过系统性地突变标准规则来获得两种非标准语义,可以有效地区分预训练记忆和真正的语义推理。
🖼️ 关键图片
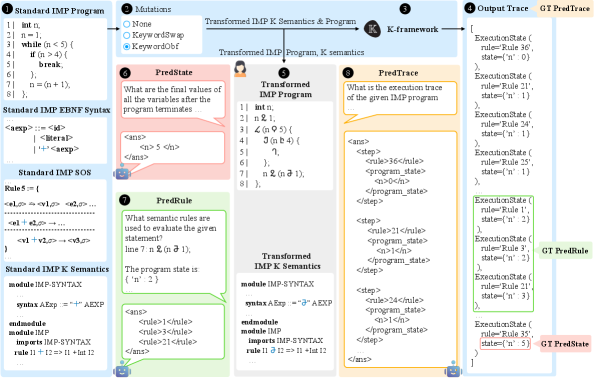
📊 实验亮点
实验结果表明,强大的代码/推理LLMs在标准语义下表现良好,但在非标准语义下性能显著下降,这表明LLMs的语义理解能力仍然有限。此外,研究发现,提供形式语义有助于简单程序,但通常会损害更复杂的程序。在粗粒度任务上,LLMs在处理包含深度嵌套循环的复杂程序时表现出色。
🎯 应用场景
该研究的潜在应用领域包括:快速原型化新的编程语言和语言特性、自动化程序分析和验证、以及开发更智能的编程工具。通过利用LLMs作为编程语言解释器,可以降低开发新语言的门槛,并提高软件开发的效率和质量。未来的影响可能包括:更易于使用的编程语言、更可靠的软件系统、以及更智能的编程环境。
📄 摘要(原文)
As large language models (LLMs) excel at code reasoning, a natural question arises: can an LLM execute programs (i.e., act as an interpreter) purely based on a programming language's formal semantics? If so, it will enable rapid prototyping of new programming languages and language features. We study this question using the imperative language IMP (a subset of C), formalized via small-step operational semantics (SOS) and rewriting-based operational semantics (K-semantics). We introduce three evaluation sets-Human-Written, LLM-Translated, and Fuzzer- Generated-whose difficulty is controlled by code-complexity metrics spanning the size, control-flow, and data-flow axes. Given a program and its semantics formalized with SOS/K-semantics, models are evaluated on three tasks ranging from coarse to fine: (1) final-state prediction, (2) semantic rule prediction, and (3) execution trace prediction. To distinguish pretraining memorization from semantic competence, we define two nonstandard semantics obtained through systematic mutations of the standard rules. Across strong code/reasoning LLMs, performance drops under nonstandard semantics despite high performance under the standard one. We further find that (i) there are patterns to different model failures, (ii) most reasoning models perform exceptionally well on coarse grained tasks involving reasoning about highly complex programs often containing nested loop depths beyond five, and surprisingly, (iii) providing formal semantics helps on simple programs but often hurts on more complex ones. Overall, the results show a promise that LLMs could serve as programming language interpreters, but points to the lack of their robust semantics understanding. We release the benchmark and the supporting code at https://github.com/EngineeringSoftware/PLSemanticsBench.