Coevolutionary Continuous Discrete Diffusion: Make Your Diffusion Language Model a Latent Reasoner
作者: Cai Zhou, Chenxiao Yang, Yi Hu, Chenyu Wang, Chubin Zhang, Muhan Zhang, Lester Mackey, Tommi Jaakkola, Stephen Bates, Dinghuai Zhang
分类: cs.AI, cs.CL
发布日期: 2025-10-03
备注: 27 pages
💡 一句话要点
提出共进化连续离散扩散模型,提升扩散语言模型的潜在推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 语言建模 连续扩散 离散扩散 潜在推理 多模态学习 共进化 自然语言处理
📋 核心要点
- 现有连续扩散语言模型在实际应用中表现不如离散模型,主要挑战在于连续空间到离散token空间的解码难度。
- CCDD模型的核心思想是在连续和离散空间构建联合扩散过程,利用单一模型同时进行降噪,结合两者的优势。
- 实验结果表明,CCDD模型在语言建模任务上表现出色,验证了其有效性,并超越了现有扩散模型。
📝 摘要(中文)
本文提出了一种共进化连续离散扩散(CCDD)模型,旨在提升扩散语言模型的性能。尽管连续扩散模型在理论上比离散扩散和循环Transformer具有更强的表达能力,但其实际表现往往不如离散模型。作者认为这是由于连续扩散模型在将连续表示空间解码为离散token空间时存在困难。CCDD通过在连续表示空间和离散token空间的联合多模态扩散过程中进行联合降噪,利用单一模型同时在这两个空间进行操作。这种结合利用了潜在空间中丰富的语义信息,以及显式离散token带来的良好训练性和采样质量。此外,论文还提出了有效的架构和训练/采样技术,并在实际语言建模任务中取得了显著的性能提升。
🔬 方法详解
问题定义:现有扩散语言模型,特别是掩码离散扩散模型,取得了显著成功。然而,连续扩散模型虽然在理论上具有更强的表达能力,但在实际性能上却不如离散模型。主要痛点在于将连续表示解码为离散token空间的困难,导致训练和采样效率降低。
核心思路:论文的核心思路是构建一个共进化的连续离散扩散过程,即CCDD。通过在连续表示空间和离散token空间上定义联合多模态扩散过程,利用单一模型同时在这两个空间进行降噪。这样既能利用连续空间的丰富语义信息,又能借助离散token的显式表达来提高训练和采样质量。
技术框架:CCDD模型包含两个主要部分:连续表示空间和离散token空间。模型通过一个共享的神经网络结构在这两个空间之间进行信息交互和扩散/逆扩散过程。具体来说,模型首先将离散token嵌入到连续空间,然后进行连续扩散过程。在逆扩散过程中,模型同时在连续空间和离散空间进行降噪,最终生成离散token序列。
关键创新:CCDD的关键创新在于联合多模态扩散过程。与传统的单一空间扩散模型不同,CCDD同时利用了连续表示和离散token的优势,从而提高了模型的表达能力和训练效率。此外,论文还提出了针对CCDD模型的有效架构和训练/采样技术,进一步提升了模型的性能。
关键设计:CCDD模型的关键设计包括:1) 使用共享的神经网络结构来处理连续和离散空间的信息;2) 设计合适的损失函数来优化联合扩散过程;3) 采用有效的采样技术来生成高质量的token序列。具体的网络结构、损失函数和采样方法在论文中有详细描述,但具体参数设置未知。
🖼️ 关键图片

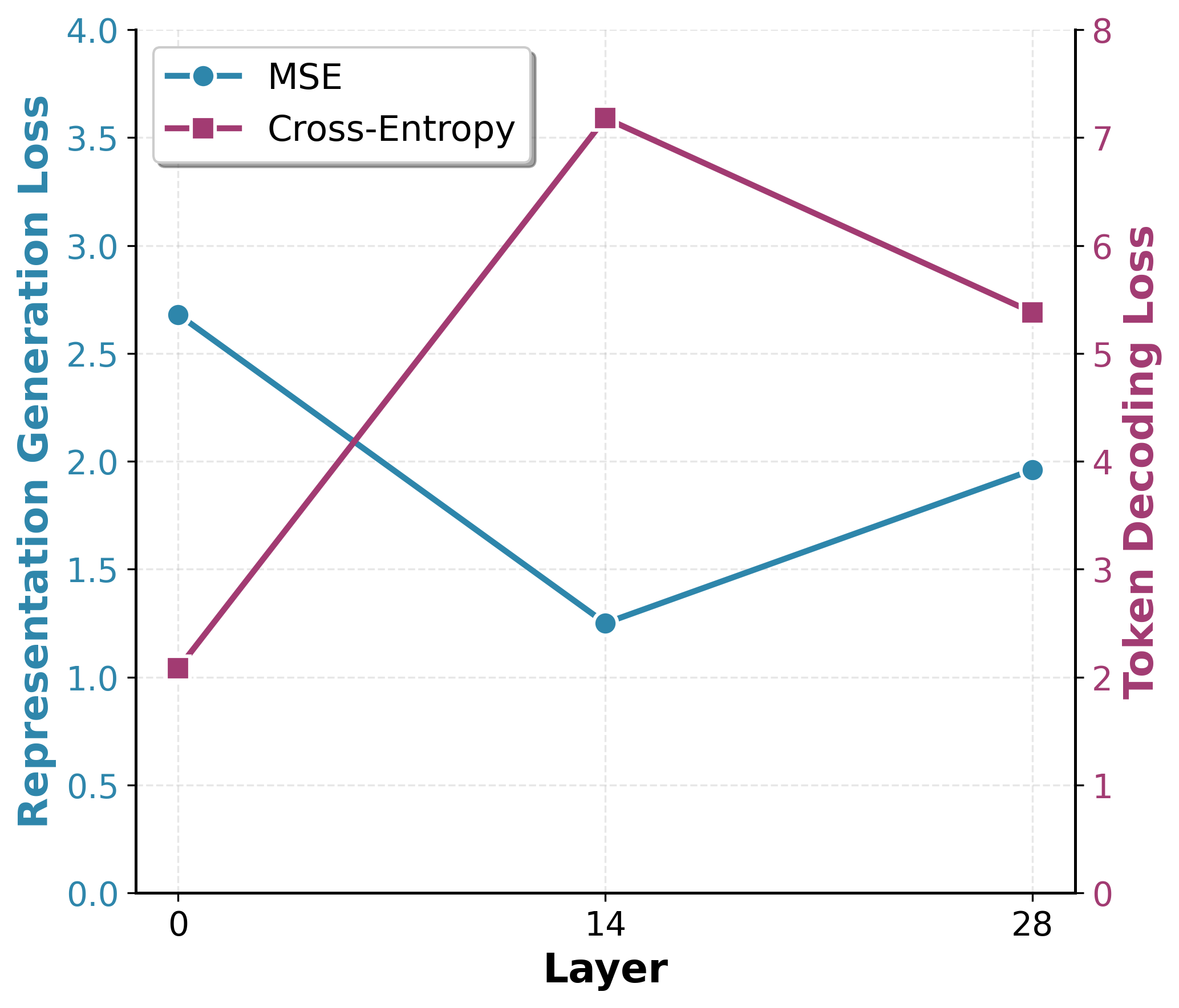

📊 实验亮点
论文通过在多个语言建模任务上的实验验证了CCDD模型的有效性。实验结果表明,CCDD模型在性能上显著优于现有的离散扩散模型和连续扩散模型。具体的性能数据和提升幅度在论文中有详细展示,但具体数值未知。
🎯 应用场景
CCDD模型可应用于各种自然语言处理任务,如文本生成、机器翻译、文本摘要等。其潜在价值在于提升语言模型的表达能力和生成质量,尤其是在需要复杂推理和语义理解的任务中。未来,CCDD模型有望推动语言模型在更广泛的应用场景中发挥作用,例如智能对话系统、内容创作和知识图谱构建。
📄 摘要(原文)
Diffusion language models, especially masked discrete diffusion models, have achieved great success recently. While there are some theoretical and primary empirical results showing the advantages of latent reasoning with looped transformers or continuous chain-of-thoughts, continuous diffusion models typically underperform their discrete counterparts. In this paper, we argue that diffusion language models do not necessarily need to be in the discrete space. In particular, we prove that continuous diffusion models have stronger expressivity than discrete diffusions and looped transformers. We attribute the contradiction between the theoretical expressiveness and empirical performance to their practical trainability: while continuous diffusion provides intermediate supervision that looped transformers lack, they introduce additional difficulty decoding tokens into the discrete token space from the continuous representation space. We therefore propose Coevolutionary Continuous Discrete Diffusion (CCDD), which defines a joint multimodal diffusion process on the union of a continuous representation space and a discrete token space, leveraging a single model to simultaneously denoise in the joint space. By combining two modalities, CCDD is expressive with rich semantics in the latent space, as well as good trainability and sample quality with the help of explicit discrete tokens. We also propose effective architectures and advanced training/sampling techniques for CCDD, which reveals strong empirical performance in extensive language modeling experiments on real-world tasks.