Emergent evaluation hubs in a decentralizing large language model ecosystem
作者: Manuel Cebrian, Tomomi Kito, Raul Castro Fernandez
分类: cs.CY, cs.AI
发布日期: 2025-09-30
备注: 15 pages, 11 figures, 3 tables
💡 一句话要点
揭示大语言模型生态系统中基准评估中心的涌现与集中化趋势
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 评估基准 集中化 Agent-based模拟 模型生态系统
📋 核心要点
- 现有大语言模型评估基准分散,缺乏统一标准,难以有效比较不同模型的性能。
- 通过分析模型生态系统和基准注册表,揭示基准影响力集中化趋势,并模拟其影响因素。
- 发现基准集中化有助于标准化和可比性,但也存在路径依赖和区分能力下降等问题。
📝 摘要(中文)
大型语言模型及其评估基准正在迅速发展。本文探讨了这两者之间的聚集模式:它们是同步演变还是彼此背离?通过分析斯坦福基础模型生态系统图和Evidently AI基准注册表这两个代理数据集,我们发现了互补但对比鲜明的动态。模型创建在国家、组织、模态、许可和访问方面日益广泛和多样化。相比之下,基准的影响力呈现集中化趋势:在推断的基准-作者-机构网络中,前15%的节点占据了超过80%的高介数路径,三个国家贡献了83%的基准输出,推断的基准权威的全球基尼系数达到0.89。基于Agent的模拟突出了三种机制:新基准的更高进入率降低了集中度;快速流入可能会暂时使评估中的协调复杂化;更严厉的过拟合惩罚效果有限。总而言之,这些结果表明,集中的基准影响力作为一种协调基础设施,支持模型生产日益异质化背景下的标准化、可比性和可重复性,同时也引入了路径依赖、选择性可见性和随着排行榜饱和而降低的区分能力等权衡。
🔬 方法详解
问题定义:当前大型语言模型生态系统中,模型数量快速增长,但评估基准分散且质量参差不齐,缺乏统一的标准和权威的评估体系。这导致难以有效比较不同模型的性能,阻碍了模型的健康发展。现有方法难以有效分析基准的影响力分布和集中化趋势,以及其对模型生态系统的影响。
核心思路:本文的核心思路是通过分析模型生态系统和基准注册表中的数据,揭示基准影响力的分布模式和集中化趋势。然后,利用基于Agent的模拟方法,研究不同因素(如新基准的进入率、数据流入速度、过拟合惩罚力度)对基准集中化的影响。通过这种方式,理解基准集中化对模型生态系统的影响,并为构建更有效的评估体系提供指导。
技术框架:本文的技术框架主要包括以下几个部分: 1. 数据收集与处理:收集斯坦福基础模型生态系统图和Evidently AI基准注册表的数据,构建模型和基准的知识图谱。 2. 网络分析:分析基准-作者-机构网络,计算节点的介数中心性,评估基准的影响力。 3. 集中度分析:计算基准权威的全球基尼系数,评估基准影响力的集中程度。 4. Agent-based模拟:构建基于Agent的模拟环境,模拟不同因素对基准集中化的影响。 5. 结果分析与讨论:分析模拟结果,讨论基准集中化对模型生态系统的影响。
关键创新:本文的关键创新在于: 1. 揭示了基准影响力的集中化趋势:通过实证分析,发现基准影响力在少数机构和国家集中。 2. 提出了基于Agent的模拟方法:利用模拟方法研究不同因素对基准集中化的影响,为理解基准集中化的动态过程提供了新的视角。 3. 分析了基准集中化的利弊:讨论了基准集中化对标准化、可比性和可重复性的促进作用,以及路径依赖和区分能力下降等潜在问题。
关键设计:在Agent-based模拟中,关键设计包括: 1. Agent的定义:Agent代表模型开发者和基准创建者。 2. Agent的行为规则:定义Agent如何选择基准进行评估,以及如何创建新的基准。 3. 环境的设置:设置新基准的进入率、数据流入速度、过拟合惩罚力度等参数。 4. 评估指标:使用基尼系数等指标评估基准影响力的集中程度。
🖼️ 关键图片
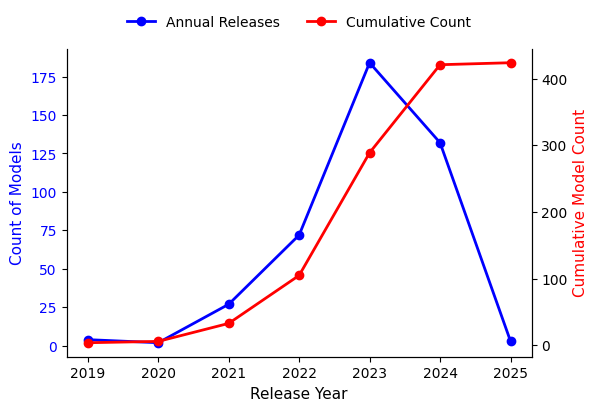
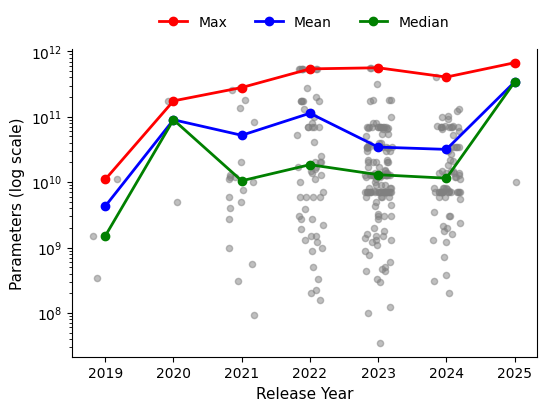
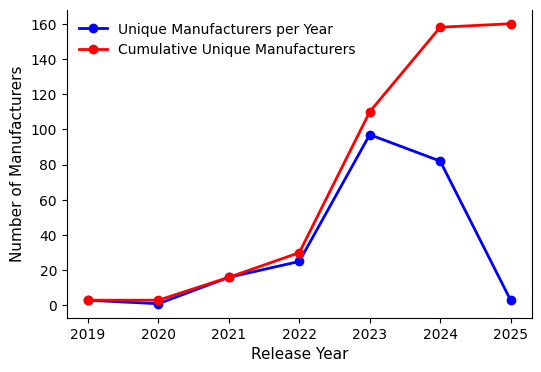
📊 实验亮点
研究发现,基准影响力呈现集中化趋势,前15%的节点占据了超过80%的高介数路径,三个国家贡献了83%的基准输出,推断的基准权威的全球基尼系数达到0.89。Agent-based模拟表明,新基准的更高进入率可以降低集中度,但快速流入可能会暂时使评估中的协调复杂化。
🎯 应用场景
该研究结果可应用于指导大语言模型评估体系的构建,促进模型生态系统的健康发展。通过理解基准集中化的影响,可以设计更公平、更具区分度的评估方法,避免路径依赖和选择性可见性等问题。此外,该研究还可以为政策制定者提供参考,促进全球范围内大语言模型技术的合作与发展。
📄 摘要(原文)
Large language models are proliferating, and so are the benchmarks that serve as their common yardsticks. We ask how the agglomeration patterns of these two layers compare: do they evolve in tandem or diverge? Drawing on two curated proxies for the ecosystem, the Stanford Foundation-Model Ecosystem Graph and the Evidently AI benchmark registry, we find complementary but contrasting dynamics. Model creation has broadened across countries and organizations and diversified in modality, licensing, and access. Benchmark influence, by contrast, displays centralizing patterns: in the inferred benchmark-author-institution network, the top 15% of nodes account for over 80% of high-betweenness paths, three countries produce 83% of benchmark outputs, and the global Gini for inferred benchmark authority reaches 0.89. An agent-based simulation highlights three mechanisms: higher entry of new benchmarks reduces concentration; rapid inflows can temporarily complicate coordination in evaluation; and stronger penalties against over-fitting have limited effect. Taken together, these results suggest that concentrated benchmark influence functions as coordination infrastructure that supports standardization, comparability, and reproducibility amid rising heterogeneity in model production, while also introducing trade-offs such as path dependence, selective visibility, and diminishing discriminative power as leaderboards saturate.