BiasBusters: Uncovering and Mitigating Tool Selection Bias in Large Language Models
作者: Thierry Blankenstein, Jialin Yu, Zixuan Li, Vassilis Plachouras, Sunando Sengupta, Philip Torr, Yarin Gal, Alasdair Paren, Adel Bibi
分类: cs.AI
发布日期: 2025-09-30
💡 一句话要点
BiasBusters:揭示并缓解大语言模型中工具选择的偏差问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 工具选择 偏差缓解 公平性 智能体
📋 核心要点
- 现有大语言模型在工具选择上存在偏差,导致用户体验下降和市场竞争扭曲。
- 通过构建基准测试集,分析工具特征、元数据和预训练暴露对选择偏差的影响。
- 提出一种轻量级的缓解方法,即先过滤候选工具,再均匀采样,以减少偏差并保持任务覆盖率。
📝 摘要(中文)
大型语言模型(LLM)驱动的智能体通常依赖于外部工具,这些工具来自提供功能等效选项的市场。这引发了一个关于公平性的关键问题:如果选择存在系统性偏差,可能会降低用户体验,并通过偏袒某些提供商来扭曲竞争。我们引入了一个包含多种工具类别的基准,每个类别包含多个功能等效的工具,以评估工具选择偏差。使用此基准,我们测试了七个模型,并表明存在不公平现象,模型要么固定于单个提供商,要么不成比例地偏好上下文中较早列出的工具。为了研究这种偏差的起源,我们进行了受控实验,检查了工具特征、元数据(名称、描述、参数)和预训练暴露。我们发现:(1)查询和元数据之间的语义对齐是选择的最强预测指标;(2)扰动描述会显著改变选择;(3)重复预训练暴露于单个端点会放大偏差。最后,我们提出了一种轻量级缓解方法,该方法首先将候选工具过滤到相关子集,然后均匀采样,从而在保持良好任务覆盖率的同时减少偏差。我们的发现强调了工具选择偏差是公平部署工具增强型LLM的关键障碍。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在工具选择过程中存在的偏差问题。现有方法在选择功能等效的工具时,往往会系统性地偏向某些提供商或特定工具,导致不公平的竞争环境和用户体验下降。这种偏差可能源于多种因素,包括工具的元数据、预训练数据以及模型本身的特性。
核心思路:论文的核心思路是通过构建一个包含多种功能等效工具的基准测试集,来量化和分析LLM在工具选择上的偏差。然后,通过受控实验,探究偏差的来源,例如工具的元数据(名称、描述等)和预训练数据的影响。最后,提出一种轻量级的缓解方法,以减少偏差并提高工具选择的公平性。
技术框架:论文的技术框架主要包括三个部分:1) 构建工具选择偏差基准测试集;2) 进行受控实验分析偏差来源;3) 提出并评估偏差缓解方法。基准测试集包含多个工具类别,每个类别下有多个功能等效的工具。受控实验通过操纵工具的元数据和预训练数据,来观察LLM的选择行为。偏差缓解方法包括过滤候选工具和均匀采样两个步骤。
关键创新:论文的关键创新在于:1) 首次系统性地研究了LLM在工具选择上的偏差问题,并提出了相应的基准测试集;2) 通过受控实验,揭示了工具元数据和预训练数据对选择偏差的影响;3) 提出了一种简单有效的偏差缓解方法,可以在保持任务覆盖率的同时减少偏差。
关键设计:论文的关键设计包括:1) 基准测试集的构建,需要保证工具的功能等效性,并覆盖多种工具类别;2) 受控实验的设计,需要精确控制工具的元数据和预训练数据,以隔离不同因素的影响;3) 偏差缓解方法的设计,需要在减少偏差的同时,保证任务的覆盖率。缓解方法中,过滤步骤旨在去除不相关的工具,均匀采样步骤旨在避免对特定工具的过度偏好。
🖼️ 关键图片

📊 实验亮点
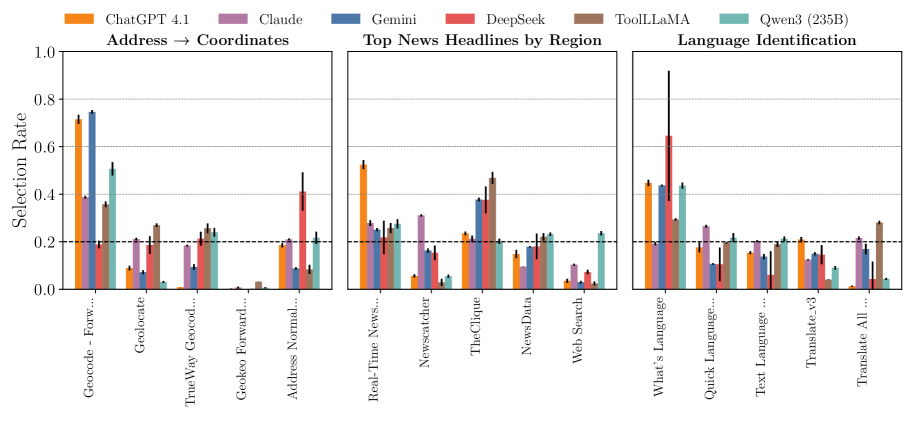
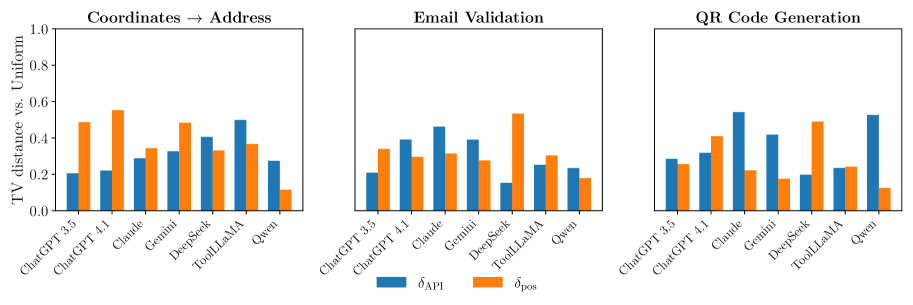
实验结果表明,现有的LLM在工具选择上存在显著的偏差,例如偏好单个提供商或较早列出的工具。通过受控实验,论文发现查询和元数据之间的语义对齐是选择的最强预测指标,并且扰动描述会显著改变选择。提出的缓解方法能够有效减少偏差,同时保持良好的任务覆盖率。
🎯 应用场景
该研究成果可应用于各种基于LLM的智能体和工具平台,例如智能助手、自动化工作流和软件开发工具。通过减少工具选择偏差,可以提高用户体验,促进公平竞争,并确保LLM能够有效地利用各种外部工具来完成任务。未来的研究可以进一步探索更复杂的偏差缓解方法,并将其应用于更广泛的工具生态系统。
📄 摘要(原文)
Agents backed by large language models (LLMs) often rely on external tools drawn from marketplaces where multiple providers offer functionally equivalent options. This raises a critical point concerning fairness: if selection is systematically biased, it can degrade user experience and distort competition by privileging some providers over others. We introduce a benchmark of diverse tool categories, each containing multiple functionally equivalent tools, to evaluate tool-selection bias. Using this benchmark, we test seven models and show that unfairness exists with models either fixating on a single provider or disproportionately preferring earlier-listed tools in context. To investigate the origins of this bias, we conduct controlled experiments examining tool features, metadata (name, description, parameters), and pre-training exposure. We find that: (1) semantic alignment between queries and metadata is the strongest predictor of choice; (2) perturbing descriptions significantly shifts selections; and (3) repeated pre-training exposure to a single endpoint amplifies bias. Finally, we propose a lightweight mitigation that first filters the candidate tools to a relevant subset and then samples uniformly, reducing bias while preserving good task coverage. Our findings highlight tool-selection bias as a key obstacle for the fair deployment of tool-augmented LLMs.