ICL Optimized Fragility
作者: Serena Gomez Wannaz
分类: cs.AI
发布日期: 2025-09-30
💡 一句话要点
ICL优化提升通用知识能力,但降低复杂推理的灵活性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: In-Context Learning 大型语言模型 认知能力 推理能力 优化脆弱性
📋 核心要点
- 现有研究缺乏对ICL引导如何影响大型语言模型跨领域认知能力的深入探索。
- 该研究通过对比不同ICL配置的模型在常识、逻辑和数学问题上的表现,揭示了ICL优化带来的“优化脆弱性”现象。
- 实验表明,ICL优化虽然提升了常识任务的准确率,但显著降低了模型在复杂推理任务上的性能。
📝 摘要(中文)
本研究探讨了ICL引导对跨领域认知能力的影响。通过对GPT-OSS:20b模型的六种变体(一个基线模型和五个ICL配置:简单、思维链、随机、附加文本和符号语言)进行测试,评估了ICL对不同知识领域推理的影响。模型接受了840项测试,涵盖常识问题、逻辑谜题和数学奥林匹克问题。方差分析表明,ICL变体之间存在显著的行为差异(p < 0.001),揭示了“优化脆弱性”现象。ICL模型在常识任务中达到了91%-99%的准确率,但在复杂推理问题上的表现下降,谜题的准确率降至10-43%,而基线模型为43%。值得注意的是,奥林匹克问题上没有显著差异(p=0.2173),表明复杂的数学推理不受ICL优化的影响。研究结果表明,ICL引导在效率和推理灵活性之间存在系统性的权衡,对LLM部署和AI安全具有重要意义。
🔬 方法详解
问题定义:论文旨在研究在大型语言模型中使用In-Context Learning (ICL) 时,不同类型的ICL引导对模型在不同认知任务上的表现影响。现有方法主要关注ICL对特定任务性能的提升,而忽略了其对模型通用认知能力可能产生的负面影响,例如降低模型在复杂推理任务上的灵活性。
核心思路:论文的核心思路是通过系统性地评估不同ICL配置的模型在不同类型的认知任务上的表现,来揭示ICL优化可能带来的“优化脆弱性”现象。这种脆弱性指的是模型在某些任务上性能提升的同时,在其他任务上的性能反而下降。
技术框架:整体框架包括以下几个步骤:1) 选择GPT-OSS:20b模型作为基础模型;2) 构建六种模型变体:一个基线模型和五个ICL配置(简单、思维链、随机、附加文本和符号语言);3) 设计包含常识问题、逻辑谜题和数学奥林匹克问题的测试集;4) 对所有模型变体进行测试,并记录其在不同任务上的表现;5) 使用方差分析等统计方法,分析不同ICL配置对模型性能的影响。
关键创新:论文最重要的创新点在于提出了“优化脆弱性”的概念,并用实验证明了ICL优化可能导致模型在某些任务上性能提升的同时,在其他任务上的性能下降。这挑战了以往对ICL的片面认识,强调了在实际应用中需要权衡ICL带来的收益和潜在的风险。
关键设计:论文的关键设计包括:1) 选择了GPT-OSS:20b模型,因为它是一个开源的大型语言模型,方便研究人员进行复现和扩展;2) 设计了包含不同难度和类型的认知任务的测试集,以全面评估ICL对模型认知能力的影响;3) 采用了多种类型的ICL配置,以研究不同ICL策略对模型性能的影响;4) 使用方差分析等统计方法,对实验结果进行严格的分析,以确保结论的可靠性。
🖼️ 关键图片


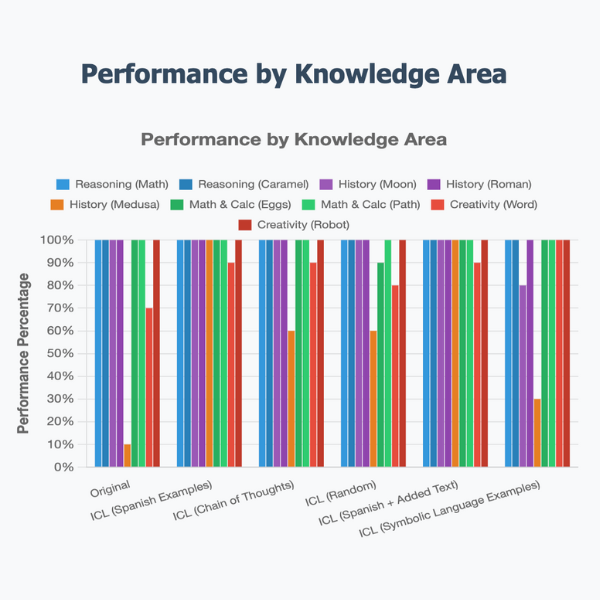
📊 实验亮点
实验结果表明,ICL模型在常识任务中达到了91%-99%的准确率,但在逻辑谜题上的准确率降至10-43%,低于基线模型的43%。在数学奥林匹克问题上,不同ICL配置的模型之间没有显著差异(p=0.2173)。这些结果清晰地展示了ICL优化在提升特定任务性能的同时,可能降低模型在复杂推理任务上的灵活性。
🎯 应用场景
该研究成果对大型语言模型的部署和AI安全具有重要意义。在实际应用中,需要根据具体任务的需求,谨慎选择ICL策略,避免过度优化导致模型在其他重要任务上的性能下降。此外,该研究也为未来研究如何提高大型语言模型的通用认知能力提供了新的思路。
📄 摘要(原文)
ICL guides are known to improve task-specific performance, but their impact on cross-domain cognitive abilities remains unexplored. This study examines how ICL guides affect reasoning across different knowledge domains using six variants of the GPT-OSS:20b model: one baseline model and five ICL configurations (simple, chain-of-thought, random, appended text, and symbolic language). The models were subjected to 840 tests spanning general knowledge questions, logic riddles, and a mathematical olympiad problem. Statistical analysis (ANOVA) revealed significant behavioral modifications (p less than 0.001) across ICL variants, demonstrating a phenomenon termed "optimized fragility." ICL models achieved 91%-99% accuracy on general knowledge tasks while showing degraded performance on complex reasoning problems, with accuracy dropping to 10-43% on riddles compared to 43% for the baseline model. Notably, no significant differences emerged on the olympiad problem (p=0.2173), suggesting that complex mathematical reasoning remains unaffected by ICL optimization. These findings indicate that ICL guides create systematic trade-offs between efficiency and reasoning flexibility, with important implications for LLM deployment and AI safety.