AgentFlux: Decoupled Fine-Tuning & Inference for On-Device Agentic Systems
作者: Rohan Kadekodi, Zhan Jin, Keisuke Kamahori, Yile Gu, Sean Khatiri, Noah H. Bayindirli, Sergey Gorbunov, Baris Kasikci
分类: cs.AI, cs.LG
发布日期: 2025-09-30 (更新: 2025-11-12)
💡 一句话要点
AgentFlux:解耦微调与推理,实现端侧Agent系统高效工具调用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 端侧AI 工具调用 大型语言模型 LoRA微调 解耦微调 Agent系统 模型推理
📋 核心要点
- 现有本地LLM在工具调用方面表现不佳,尤其是在工具选择和参数生成上,限制了其在隐私敏感场景的应用。
- AgentFlux通过解耦工具选择和参数生成,并使用LoRA进行针对性微调,显著提升了本地LLM的工具调用能力。
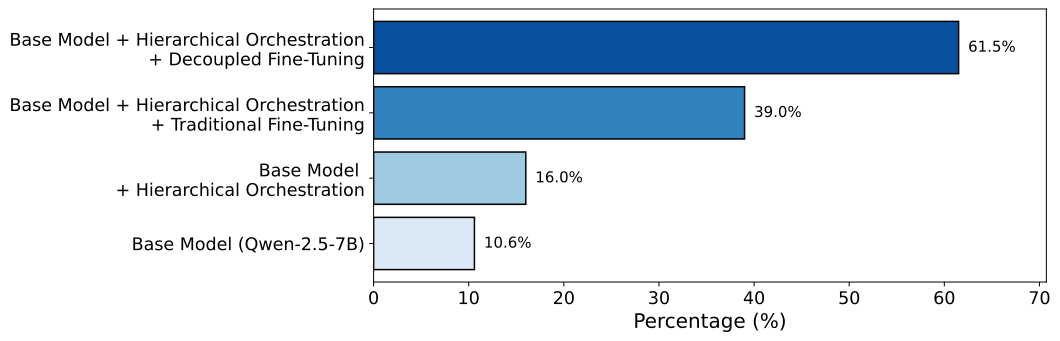
- 实验表明,AgentFlux在工具调用准确率上取得了显著提升,超越了同等规模甚至更大规模的其他模型。
📝 摘要(中文)
大型语言模型(LLM)作为agent编排器彻底改变了任务自动化,但对保护隐私、经济高效的解决方案的需求推动了端侧推理能力的发展。然而,本地LLM在工具调用场景中的表现始终不如前沿模型,难以从大型工具集中选择合适的工具,并为复杂的参数结构生成准确的参数。我们提出了一种将工具调用任务分解为两个不同子任务的方法:工具选择和参数生成。我们提出“解耦微调”,这是一种新颖的后训练方法,它采用LoRA微调来创建专用的LoRA适配器,分别用于工具选择和工具特定的参数生成,并为每个子任务使用单独的损失掩码。此外,我们提出了AgentFlux,一个利用解耦微调创建的LoRA适配器,在终端用户设备上借助本地模型执行高效agent编排的推理框架。AgentFlux将工具调用生成步骤分解为工具选择和参数生成,并动态加载相应的LoRA适配器以生成工具调用。此外,AgentFlux实现了分层编排,以限制工具选择所需的工具数量。我们在MCP-Bench基准上的实验表明,使用解耦微调训练的Qwen-2.5-7B模型将基础模型的工具调用准确率提高了46%,并且在所有情况下都优于其他类似大小的本地推理、非推理和微调模型,并且在大多数情况下优于大2倍的模型。
🔬 方法详解
问题定义:论文旨在解决本地大型语言模型(LLM)在端侧设备上进行工具调用时性能不足的问题。现有的本地LLM在工具选择的准确性和参数生成的精确性方面都存在挑战,这限制了它们在需要隐私保护和低成本的agentic系统中的应用。
核心思路:论文的核心思路是将工具调用任务分解为工具选择和参数生成两个独立的子任务,并针对每个子任务进行专门的优化。通过解耦微调,可以更有效地利用有限的计算资源,提升本地LLM在特定任务上的性能。
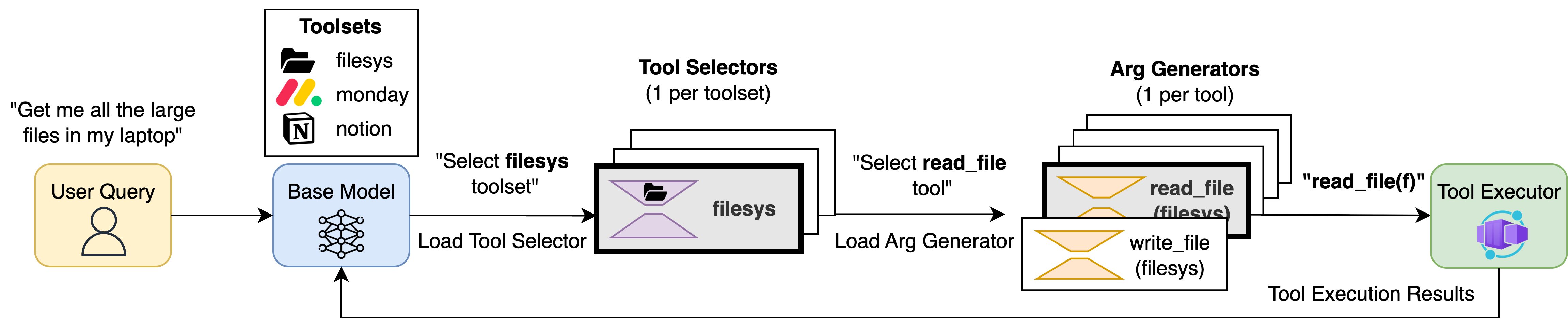
技术框架:AgentFlux框架包含以下几个主要组成部分:1) 解耦微调:使用LoRA对LLM进行微调,为工具选择和参数生成创建独立的适配器。2) 分层编排:限制工具选择的范围,减少计算复杂度。3) 动态LoRA加载:在推理时,根据当前任务动态加载相应的LoRA适配器。整体流程是,给定一个任务,首先使用工具选择LoRA选择合适的工具,然后使用该工具对应的参数生成LoRA生成参数,最后执行工具调用。
关键创新:论文的关键创新在于解耦微调方法,它允许针对工具选择和参数生成两个子任务进行独立的优化。这种方法能够更有效地利用LoRA的参数效率,提升本地LLM在工具调用任务上的性能。此外,AgentFlux框架通过分层编排和动态LoRA加载,进一步提升了推理效率。
关键设计:解耦微调的关键在于损失函数的掩码设计。在训练工具选择LoRA时,只计算工具选择部分的损失,而忽略参数生成部分的损失。反之,在训练参数生成LoRA时,只计算参数生成部分的损失,而忽略工具选择部分的损失。这种损失掩码的设计使得LoRA能够专注于优化特定的子任务。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用解耦微调训练的Qwen-2.5-7B模型在MCP-Bench基准测试中,工具调用准确率提高了46%。该模型在所有情况下都优于其他类似大小的本地推理、非推理和微调模型,并且在大多数情况下优于大2倍的模型,证明了解耦微调和AgentFlux框架的有效性。
🎯 应用场景
AgentFlux的潜在应用领域包括智能家居、移动办公、车载助手等。它可以在保护用户隐私的前提下,实现端侧设备上的自动化任务处理和智能决策。该研究有助于推动agentic系统在资源受限设备上的普及,并为未来的端侧AI应用奠定基础。
📄 摘要(原文)
The deployment of Large Language Models (LLMs) as agentic orchestrators has revolutionized task automation, but the need for privacy-preserving, cost-effective solutions demands on-device inference capabilities. However, local LLMs consistently underperform compared to frontier models in tool calling scenarios, struggling with both tool selection from large tool sets and accurate argument generation for complex parameter structures. We introduce a methodology that disaggregates a tool-calling task into two distinct subtasks: tool selection and argument generation. We propose "decoupled fine-tuning", a novel post-training approach that employs LoRA fine-tuning to create dedicated LoRA adapters for tool selection and tool-specific argument generation using separate loss masking for each of the subtasks. Furthermore, we present AgentFlux, an inference framework that leverages the LoRA adapters created using decoupled fine-tuning to perform efficient agent orchestration with the help of local models on end-user devices. AgentFlux decomposes the tool-call generation step into tool selection and argument generation, and dynamically loads the corresponding LoRA adapters to generate tool calls. Additionally, AgentFlux implements hierarchical orchestration to restrict the number of tools required for tool selection. Our experiments on the MCP-Bench benchmark demonstrate that the Qwen-2.5-7B model trained using decoupled fine-tuning improves the tool calling accuracy of the base model by 46%, and outperforms other local reasoning, non-reasoning and fine-tuned models of similar size in all cases, and models that are 2x larger, in most cases.