The Dragon Hatchling: The Missing Link between the Transformer and Models of the Brain
作者: Adrian Kosowski, Przemysław Uznański, Jan Chorowski, Zuzanna Stamirowska, Michał Bartoszkiewicz
分类: cs.NE, cs.AI, cs.LG, stat.ML
发布日期: 2025-09-30
备注: Code available at: https://github.com/pathwaycom/bdh Accompanying blog: https://pathway.com/research/bdh
💡 一句话要点
提出Dragon Hatchling模型,弥合Transformer与大脑模型之间的差距
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 生物启发 可解释性 赫布学习 突触可塑性
📋 核心要点
- 现有机器学习模型在通用推理方面存在瓶颈,难以像大脑一样进行时间泛化。
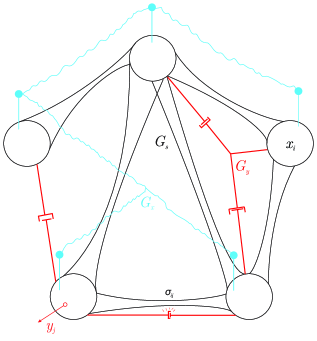
- 提出Dragon Hatchling (BDH) 模型,模拟大脑的无尺度网络,实现局部神经元交互。
- 实验表明,BDH在语言和翻译任务上可与GPT2性能媲美,且具有更好的可解释性。
📝 摘要(中文)
本文介绍了一种新的大型语言模型架构“Dragon Hatchling”(BDH),它基于一个具有生物学启发、无尺度网络结构的神经元粒子,这些粒子之间进行局部交互。BDH兼具强大的理论基础和内在的可解释性,同时不牺牲Transformer的性能。BDH是一种实用的、高性能的、基于注意力机制的状态空间序列学习架构。除了作为一个图模型,BDH还具有GPU友好的特性。它表现出类似Transformer的缩放规律:经验表明,对于相同的训练数据,在相同数量的参数(1000万到10亿)下,BDH在语言和翻译任务上可以与GPT2的性能相媲美。BDH可以被表示为一个大脑模型。BDH在推理过程中的工作记忆完全依赖于具有赫布学习的脉冲神经元的突触可塑性。经验证实,每当BDH听到或推理关于特定概念时,特定的、单独的突触就会加强连接。BDH的神经元交互网络是一个具有高模块化和重尾度分布的图。BDH模型具有生物学上的合理性,解释了人类神经元可能使用的一种实现语音的机制。BDH专为可解释性而设计。BDH的激活向量是稀疏且为正的。我们在语言任务中展示了BDH的单义性。状态的可解释性,超越了神经元和模型参数的可解释性,是BDH架构的固有特征。
🔬 方法详解
问题定义:现有的大型语言模型,如Transformer,虽然在各种任务上取得了显著的成果,但在生物学合理性和可解释性方面存在不足。此外,它们在时间泛化能力上与人脑相比仍有差距。因此,需要一种既能保持高性能,又能模拟大脑结构和功能的模型。
核心思路:BDH的核心思路是构建一个基于生物学启发的、无尺度网络结构的神经元模型。通过模拟大脑中神经元之间的局部交互和突触可塑性,BDH旨在实现更强的泛化能力和可解释性。这种设计允许模型在推理过程中利用赫布学习,从而动态地调整神经元之间的连接强度。
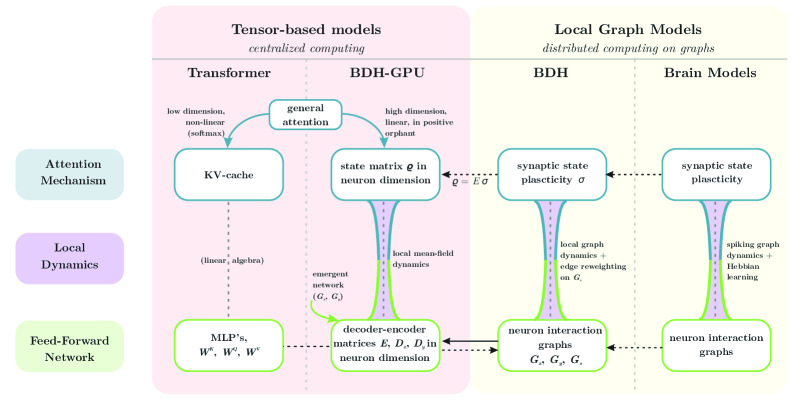
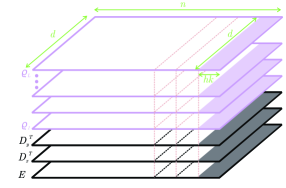
技术框架:BDH的整体架构是一个由n个局部交互的神经元粒子组成的图模型。该模型包含以下主要模块:1)神经元粒子:每个粒子代表一个神经元,具有激活状态和连接权重。2)局部交互:神经元之间通过局部连接进行信息传递和交互。3)突触可塑性:神经元之间的连接权重根据赫布学习规则进行动态调整。4)状态空间序列学习:模型通过状态空间模型学习序列数据。
关键创新:BDH的关键创新在于其生物学启发的网络结构和基于赫布学习的突触可塑性机制。与传统的Transformer模型相比,BDH更接近大脑的结构和功能,从而具有更好的可解释性和泛化能力。此外,BDH的激活向量是稀疏且为正的,这进一步提高了模型的可解释性。
关键设计:BDH的关键设计包括:1)神经元粒子的激活函数:使用稀疏且为正的激活函数,以提高可解释性。2)局部连接的拓扑结构:采用无尺度网络结构,模拟大脑中的神经元连接模式。3)赫布学习规则:根据神经元之间的激活状态,动态调整连接权重。4)损失函数:采用交叉熵损失函数,优化模型的预测性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,BDH在语言和翻译任务上可以达到与GPT2相当的性能,同时具有更好的可解释性。具体来说,在相同参数规模下,BDH在语言建模任务上的困惑度与GPT2接近。此外,实验还证实了BDH的神经元交互网络具有高模块化和重尾度分布,这与大脑的结构特征相符。更重要的是,实验观察到BDH在处理特定概念时,相应的突触连接会得到加强,这验证了赫布学习机制的有效性。
🎯 应用场景
BDH模型具有广泛的应用前景,包括自然语言处理、机器翻译、语音识别等领域。其生物学合理性和可解释性使其在医疗诊断、智能客服等需要高度可信赖的应用场景中具有独特的优势。此外,BDH还可以作为研究人脑认知机制的工具,促进神经科学和人工智能的交叉研究。
📄 摘要(原文)
The relationship between computing systems and the brain has served as motivation for pioneering theoreticians since John von Neumann and Alan Turing. Uniform, scale-free biological networks, such as the brain, have powerful properties, including generalizing over time, which is the main barrier for Machine Learning on the path to Universal Reasoning Models. We introduce `Dragon Hatchling' (BDH), a new Large Language Model architecture based on a scale-free biologically inspired network of \$n\$ locally-interacting neuron particles. BDH couples strong theoretical foundations and inherent interpretability without sacrificing Transformer-like performance. BDH is a practical, performant state-of-the-art attention-based state space sequence learning architecture. In addition to being a graph model, BDH admits a GPU-friendly formulation. It exhibits Transformer-like scaling laws: empirically BDH rivals GPT2 performance on language and translation tasks, at the same number of parameters (10M to 1B), for the same training data. BDH can be represented as a brain model. The working memory of BDH during inference entirely relies on synaptic plasticity with Hebbian learning using spiking neurons. We confirm empirically that specific, individual synapses strengthen connection whenever BDH hears or reasons about a specific concept while processing language inputs. The neuron interaction network of BDH is a graph of high modularity with heavy-tailed degree distribution. The BDH model is biologically plausible, explaining one possible mechanism which human neurons could use to achieve speech. BDH is designed for interpretability. Activation vectors of BDH are sparse and positive. We demonstrate monosemanticity in BDH on language tasks. Interpretability of state, which goes beyond interpretability of neurons and model parameters, is an inherent feature of the BDH architecture.