SeedPrints: Fingerprints Can Even Tell Which Seed Your Large Language Model Was Trained From
作者: Yao Tong, Haonan Wang, Siquan Li, Kenji Kawaguchi, Tianyang Hu
分类: cs.CR, cs.AI, cs.CL
发布日期: 2025-09-30
💡 一句话要点
提出SeedPrints:利用模型初始化偏差进行大语言模型溯源
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 指纹识别 模型溯源 初始化偏差 随机种子
📋 核心要点
- 现有LLM指纹识别方法依赖训练后的属性,易受攻击且在训练早期不可靠,无法实现从模型“诞生”到“生命周期”的身份验证。
- SeedPrints利用模型初始化时的随机偏差,即使在训练前也存在,作为模型的独特指纹,实现更强的溯源能力。
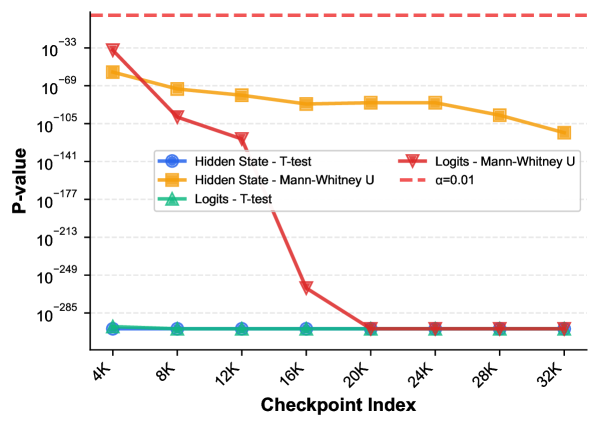
- 实验证明SeedPrints在不同训练阶段和领域偏移下均有效,能高精度识别模型来源,并具备抵抗参数修改的鲁棒性。
📝 摘要(中文)
大语言模型(LLM)的指纹识别对于来源验证和模型归属至关重要。现有方法通常基于训练动态、数据暴露或超参数等训练后属性提取签名。本文提出了一种更强且更本质的LLM指纹识别方法:SeedPrints,该方法利用随机初始化偏差作为持久的、种子相关的标识符,即使在训练开始之前就存在。研究表明,未经训练的模型仅根据其初始化时的参数就表现出可重复的token选择偏差。这些偏差在整个训练过程中保持稳定且可测量,使我们的统计检测方法能够高置信度地恢复模型的谱系。与之前在收敛前不可靠且易受分布偏移影响的技术不同,SeedPrints在所有训练阶段都有效,并且在领域偏移或参数修改下具有鲁棒性。在LLaMA和Qwen风格模型上的实验表明,SeedPrints实现了种子级别的可区分性,并可以提供类似于生物指纹的从诞生到生命周期的身份验证。大规模预训练模型和指纹识别基准的评估进一步证实了其在实际部署场景中的有效性。这些结果表明,初始化本身就在神经语言模型上印刻了一个独特的且持久的身份,形成了一个真正的“高尔顿”指纹。
🔬 方法详解
问题定义:现有LLM指纹识别方法主要依赖于训练过程中的动态信息,例如训练数据暴露、超参数设置等。这些方法存在一些局限性:首先,它们需要在模型训练到一定程度后才能提取有效的指纹,无法在模型“诞生”之初就进行识别;其次,这些指纹容易受到对抗性攻击,例如通过修改训练数据或超参数来改变模型的指纹;最后,当模型面临领域偏移时,这些指纹的可靠性会下降。因此,需要一种更本质、更鲁棒的LLM指纹识别方法。
核心思路:SeedPrints的核心思想是利用模型初始化时的随机偏差作为指纹。由于神经网络的初始化参数是随机生成的,不同的随机种子会导致不同的初始化参数。这些初始化参数会影响模型在训练过程中的行为,从而在模型的参数中留下可识别的痕迹。即使模型经过训练、微调或迁移学习,这些痕迹仍然存在。因此,可以通过分析模型的参数来识别其初始化时使用的随机种子,从而实现模型的溯源。
技术框架:SeedPrints方法主要包含以下几个步骤:1) 模型初始化:使用不同的随机种子初始化多个LLM模型。2) Token选择偏差分析:对于每个模型,分析其在初始化状态下的token选择偏差。具体来说,给定一个输入序列,模型会预测下一个token的概率分布。SeedPrints关注的是模型在初始化状态下对不同token的偏好。3) 指纹提取:基于token选择偏差,提取模型的指纹。指纹可以是token选择概率分布的统计特征,例如均值、方差等。4) 指纹匹配:给定一个未知来源的LLM模型,提取其指纹,并与已知模型的指纹进行匹配。如果匹配成功,则可以确定该模型的来源。
关键创新:SeedPrints的关键创新在于:1) 利用初始化偏差:首次将模型初始化时的随机偏差作为指纹,实现了在模型训练前进行识别。2) 鲁棒性:由于初始化偏差是模型固有的属性,因此SeedPrints对对抗性攻击和领域偏移具有较强的鲁棒性。3) 高精度:实验证明SeedPrints能够以较高的精度识别模型的来源。
关键设计:SeedPrints的关键设计包括:1) Token选择偏差的度量:如何准确地度量模型在初始化状态下的token选择偏差是一个关键问题。论文中使用了多种统计方法来分析token选择概率分布。2) 指纹的提取和匹配:如何提取具有代表性的指纹,并设计高效的匹配算法,是另一个关键问题。论文中使用了基于统计特征的指纹提取方法,并采用了余弦相似度等度量方法进行指纹匹配。3) 模型和数据集的选择:为了验证SeedPrints的有效性,论文在多种LLM模型(例如LLaMA和Qwen)和数据集上进行了实验。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SeedPrints在LLaMA和Qwen等模型上实现了种子级别的可区分性,即使在模型经过训练、微调或迁移学习后,仍然能够准确识别模型的来源。在领域偏移和参数修改等情况下,SeedPrints也表现出较强的鲁棒性。例如,即使模型在不同的数据集上进行微调,SeedPrints仍然能够识别其原始的初始化种子。
🎯 应用场景
SeedPrints技术可应用于多种场景,包括:模型溯源,确定模型的训练来源和所有者;版权保护,防止模型被非法复制或篡改;安全审计,评估模型是否存在安全漏洞;模型供应链管理,跟踪模型的整个生命周期。该技术有助于建立更安全、可信赖的AI生态系统,并促进LLM的负责任使用。
📄 摘要(原文)
Fingerprinting Large Language Models (LLMs) is essential for provenance verification and model attribution. Existing methods typically extract post-hoc signatures based on training dynamics, data exposure, or hyperparameters -- properties that only emerge after training begins. In contrast, we propose a stronger and more intrinsic notion of LLM fingerprinting: SeedPrints, a method that leverages random initialization biases as persistent, seed-dependent identifiers present even before training. We show that untrained models exhibit reproducible token selection biases conditioned solely on their parameters at initialization. These biases are stable and measurable throughout training, enabling our statistical detection method to recover a model's lineage with high confidence. Unlike prior techniques, unreliable before convergence and vulnerable to distribution shifts, SeedPrints remains effective across all training stages and robust under domain shifts or parameter modifications. Experiments on LLaMA-style and Qwen-style models show that SeedPrints achieves seed-level distinguishability and can provide birth-to-lifecycle identity verification akin to a biometric fingerprint. Evaluations on large-scale pretrained models and fingerprinting benchmarks further confirm its effectiveness under practical deployment scenarios. These results suggest that initialization itself imprints a unique and persistent identity on neural language models, forming a true ''Galtonian'' fingerprint.