Game-Time: Evaluating Temporal Dynamics in Spoken Language Models
作者: Kai-Wei Chang, En-Pei Hu, Chun-Yi Kuan, Wenze Ren, Wei-Chih Chen, Guan-Ting Lin, Yu Tsao, Shao-Hua Sun, Hung-yi Lee, James Glass
分类: eess.AS, cs.AI, cs.CL
发布日期: 2025-09-30 (更新: 2026-02-02)
备注: Accepted to ICASSP 2026
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Game-Time基准,评估会话语音语言模型的时间动态性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 会话语音模型 时间动态性 基准测试 指令跟随 时间感知
📋 核心要点
- 现有的会话语音语言模型在时间动态性方面存在不足,尤其是在处理时序、节奏和同步说话等复杂场景时。
- Game-Time基准通过模拟人类语言学习活动,设计了包含时间约束的指令跟随任务,以系统评估模型的时间感知能力。
- 实验结果表明,现有模型在基本任务上表现良好,但在时间约束下性能显著下降,揭示了模型在时间感知和全双工交互方面的弱点。
📝 摘要(中文)
会话式语音语言模型(SLM)正成为实时语音交互的一种有前景的范例。然而,它们的时间动态能力,包括管理时序、节奏和同步说话的能力,仍然是会话流畅性的一个关键且未被评估的挑战。为了解决这一差距,我们引入了Game-Time基准,这是一个系统地评估这些时间能力的框架。受到人类通过语言活动学习语言的启发,Game-Time由基本的指令跟随任务和具有时间约束的高级任务组成,例如节奏遵守和同步响应。我们对各种SLM架构的评估揭示了明显的性能差异:虽然最先进的模型能够很好地处理基本任务,但许多当代系统仍然难以完成基本的指令跟随。更关键的是,几乎所有模型在时间约束下都会大幅下降,暴露了时间感知和全双工交互方面的持续弱点。Game-Time基准为指导未来研究,朝着更具时间意识的会话AI奠定了基础。演示和数据集可在我们的项目网站https://ga642381.github.io/Game-Time上找到。
🔬 方法详解
问题定义:现有会话语音语言模型(SLM)在处理时间动态性方面存在挑战,具体体现在对时序、节奏和同步说话的管理能力不足。这导致模型在需要时间感知的会话场景中表现不佳,例如无法按照特定节奏回复或进行同步交互。现有评估方法缺乏对这些时间能力的系统性评估。
核心思路:Game-Time基准的核心思路是模拟人类通过语言活动学习语言的过程,设计一系列包含时间约束的指令跟随任务。通过这些任务,可以系统地评估SLM在时间感知、节奏控制和同步交互方面的能力。这种方法更贴近实际应用场景,能够更全面地反映模型的性能。
技术框架:Game-Time基准包含两类任务:基本指令跟随任务和高级时间约束任务。基本任务评估模型对简单指令的理解和执行能力。高级任务则引入时间约束,例如要求模型按照特定节奏回复(节奏遵守)或与用户进行同步交互(同步响应)。整个框架通过评估模型在这些任务上的表现,来衡量其时间动态性。
关键创新:Game-Time基准的关键创新在于其对时间动态性的系统性评估方法。它不仅关注模型对指令的理解,更关注模型在时间维度上的表现。通过引入时间约束任务,能够更有效地发现模型在时间感知和全双工交互方面的弱点。这是现有评估方法所缺乏的。
关键设计:Game-Time基准的关键设计在于其任务的多样性和难度。基本任务用于评估模型的基础能力,而高级时间约束任务则用于挑战模型的时间感知和控制能力。任务的设计灵感来源于人类的语言学习活动,例如模仿节奏或同步响应。具体的参数设置和网络结构取决于被评估的SLM模型。
🖼️ 关键图片

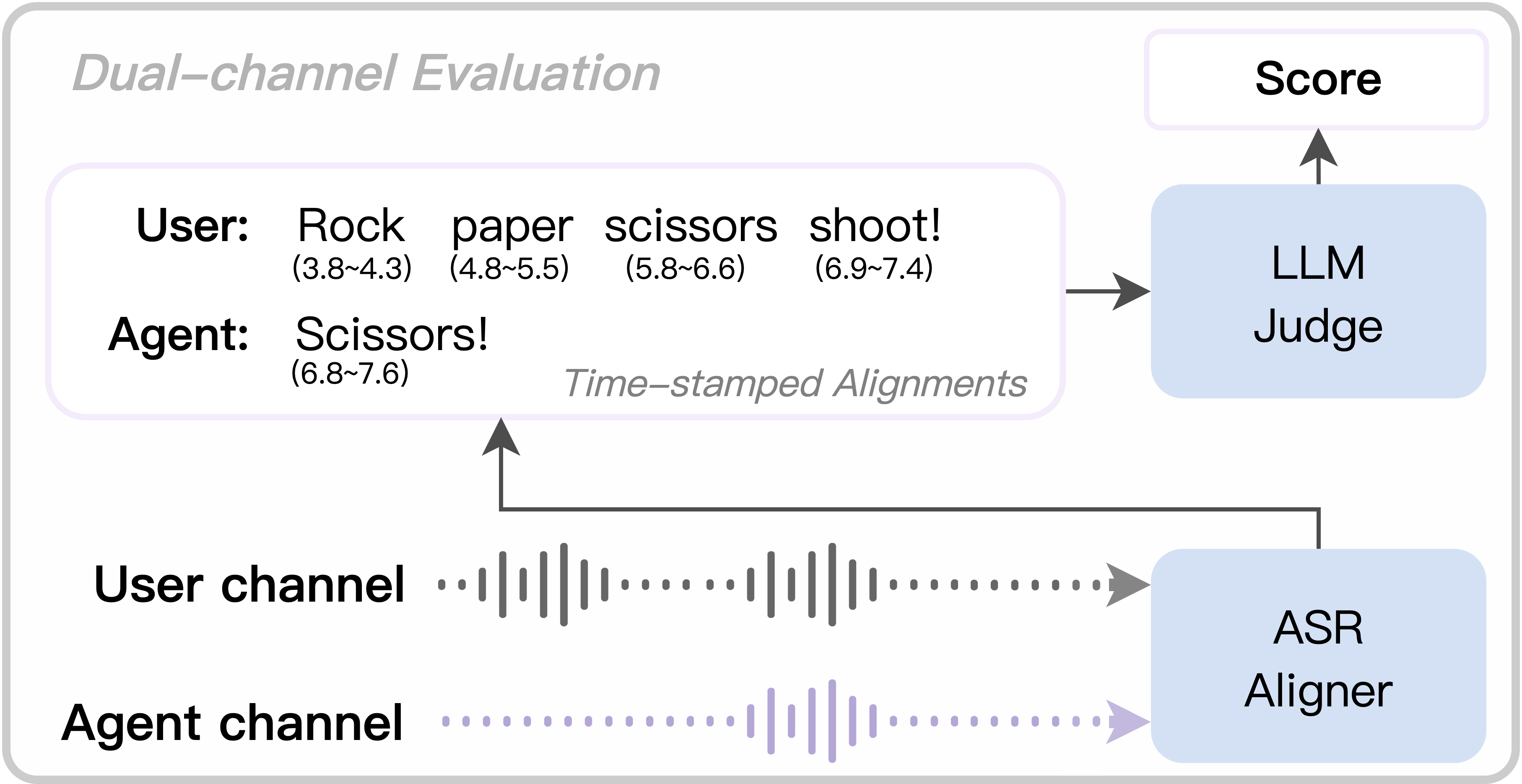

📊 实验亮点
实验结果表明,虽然最先进的SLM模型在基本指令跟随任务上表现良好,但在时间约束任务中性能显著下降。例如,模型在节奏遵守和同步响应任务中的准确率明显低于基本任务。这表明现有模型在时间感知和全双工交互方面仍存在较大提升空间,Game-Time基准能够有效揭示这些弱点。
🎯 应用场景
Game-Time基准的潜在应用领域包括开发更自然、更流畅的会话式AI系统,例如智能助手、聊天机器人和语音游戏。通过提高模型的时间感知能力,可以改善用户与AI的交互体验,使其更接近人与人之间的自然对话。该研究还有助于开发更具时间意识的机器人,使其能够更好地与人类协作。
📄 摘要(原文)
Conversational Spoken Language Models (SLMs) are emerging as a promising paradigm for real-time speech interaction. However, their capacity of temporal dynamics, including the ability to manage timing, tempo and simultaneous speaking, remains a critical and unevaluated challenge for conversational fluency. To address this gap, we introduce the Game-Time Benchmark, a framework to systematically assess these temporal capabilities. Inspired by how humans learn a language through language activities, Game-Time consists of basic instruction-following tasks and advanced tasks with temporal constraints, such as tempo adherence and synchronized responses. Our evaluation of diverse SLM architectures reveals a clear performance disparity: while state-of-the-art models handle basic tasks well, many contemporary systems still struggle with fundamental instruction-following. More critically, nearly all models degrade substantially under temporal constraints, exposing persistent weaknesses in time awareness and full-duplex interaction. The Game-Time Benchmark provides a foundation for guiding future research toward more temporally-aware conversational AI. Demos and datasets are available on our project website https://ga642381.github.io/Game-Time.