SafeBehavior: Simulating Human-Like Multistage Reasoning to Mitigate Jailbreak Attacks in Large Language Models
作者: Qinjian Zhao, Jiaqi Wang, Zhiqiang Gao, Zhihao Dou, Belal Abuhaija, Kaizhu Huang
分类: cs.AI
发布日期: 2025-09-30
备注: 27 pages, 5 figure
💡 一句话要点
SafeBehavior:模拟人类多阶段推理以防御大语言模型的越狱攻击
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 安全防御 多阶段推理 意图推断 自我反省 自我修正
📋 核心要点
- 现有防御方法在计算成本、泛化能力和工作流程灵活性方面存在不足,难以有效应对复杂的越狱攻击。
- SafeBehavior模拟人类多阶段推理过程,通过意图推断、自我反省和自我修正三个阶段进行安全评估。
- 实验表明,SafeBehavior在多种越狱攻击场景下显著提升了鲁棒性和适应性,优于现有防御方法。
📝 摘要(中文)
大型语言模型(LLMs)在各种自然语言处理任务中取得了令人瞩目的性能,但其日益增长的能力也放大了潜在风险,例如绕过内置安全机制的越狱攻击。现有的防御措施,包括输入释义、多步评估和安全专家模型,通常面临计算成本高、泛化能力有限或工作流程僵化等问题,无法检测到嵌入在复杂上下文中的细微恶意意图。受人类决策认知科学研究的启发,我们提出SafeBehavior,一种新颖的分层越狱防御机制,模拟人类的自适应多阶段推理过程。SafeBehavior将安全评估分解为三个阶段:意图推断以检测明显的输入风险,自我反省以评估生成的响应并分配基于置信度的判断,以及自我修正以自适应地重写不确定的输出,同时保留用户意图并强制执行安全约束。我们针对五种具有代表性的越狱攻击类型(包括基于优化的攻击、上下文操纵和基于提示的攻击)广泛评估了SafeBehavior,并将其与七种最先进的防御基线进行了比较。实验结果表明,SafeBehavior显著提高了各种威胁场景中的鲁棒性和适应性,为保护LLM免受越狱尝试提供了一种高效且受人类启发的方法。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)容易受到越狱攻击的问题,即攻击者通过精心设计的输入绕过LLM的安全机制,使其生成有害或不当的内容。现有防御方法,如输入释义、多步评估和安全专家模型,存在计算成本高昂、泛化能力不足以及难以检测复杂上下文中的恶意意图等问题。
核心思路:SafeBehavior的核心思路是模拟人类在决策过程中的多阶段推理方式,将安全评估分解为多个步骤,逐步识别和消除潜在的风险。这种分层和自适应的方法旨在提高防御系统的鲁棒性和灵活性,使其能够应对各种类型的越狱攻击。
技术框架:SafeBehavior包含三个主要阶段: 1. 意图推断(Intention Inference):分析用户输入,检测其中可能存在的恶意意图或风险。 2. 自我反省(Self Introspection):评估LLM生成的响应,并根据置信度进行判断,识别潜在的安全问题。 3. 自我修正(Self Revision):对于不确定的输出,自适应地进行重写,以确保安全约束得到满足,同时尽可能保留用户的原始意图。
关键创新:SafeBehavior的关键创新在于其模拟人类认知过程的分层防御架构。与传统的单步或固定流程的防御方法不同,SafeBehavior能够根据输入和输出的特性,动态地调整安全评估的策略。此外,自我修正机制允许系统在不牺牲用户意图的前提下,主动消除潜在的安全风险。
关键设计:论文中可能涉及的关键设计细节包括: * 意图推断阶段使用的风险检测模型或规则。 * 自我反省阶段的置信度评估方法,例如基于LLM的概率输出或外部安全模型的评分。 * 自我修正阶段的重写策略,例如基于规则的修改、基于LLM的生成或二者结合。 * 各个阶段之间的信息传递和协调机制。 * 损失函数的设计,用于训练或微调各个模块。
🖼️ 关键图片
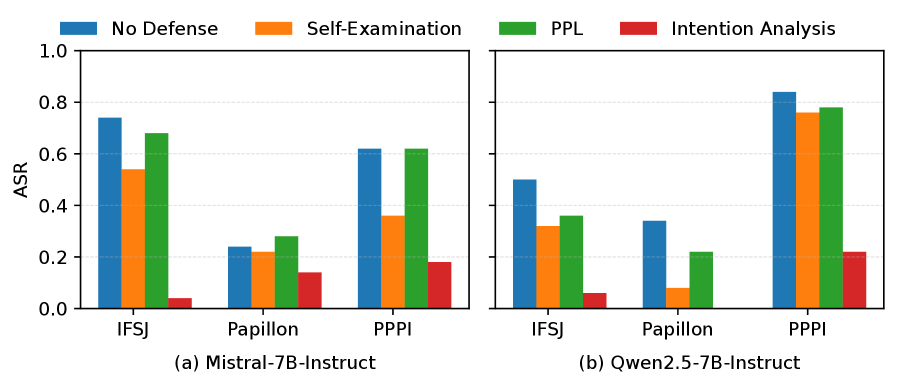

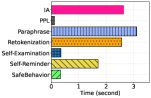
📊 实验亮点
实验结果表明,SafeBehavior在防御各种越狱攻击方面表现出色,显著优于七种最先进的防御基线。具体性能数据(例如攻击成功率降低百分比)和对比基线的详细信息需要在论文中查找。SafeBehavior在不同威胁场景下展现出更强的鲁棒性和适应性。
🎯 应用场景
SafeBehavior可应用于各种需要安全保障的大型语言模型应用场景,例如智能客服、内容生成、教育辅导等。通过提高LLM的安全性,可以减少有害信息传播的风险,提升用户信任度,并促进LLM在更广泛领域的应用。该研究为构建更安全、更可靠的人工智能系统提供了有价值的思路。
📄 摘要(原文)
Large Language Models (LLMs) have achieved impressive performance across diverse natural language processing tasks, but their growing power also amplifies potential risks such as jailbreak attacks that circumvent built-in safety mechanisms. Existing defenses including input paraphrasing, multi step evaluation, and safety expert models often suffer from high computational costs, limited generalization, or rigid workflows that fail to detect subtle malicious intent embedded in complex contexts. Inspired by cognitive science findings on human decision making, we propose SafeBehavior, a novel hierarchical jailbreak defense mechanism that simulates the adaptive multistage reasoning process of humans. SafeBehavior decomposes safety evaluation into three stages: intention inference to detect obvious input risks, self introspection to assess generated responses and assign confidence based judgments, and self revision to adaptively rewrite uncertain outputs while preserving user intent and enforcing safety constraints. We extensively evaluate SafeBehavior against five representative jailbreak attack types including optimization based, contextual manipulation, and prompt based attacks and compare it with seven state of the art defense baselines. Experimental results show that SafeBehavior significantly improves robustness and adaptability across diverse threat scenarios, offering an efficient and human inspired approach to safeguarding LLMs against jailbreak attempts.