Interactive Learning for LLM Reasoning
作者: Hehai Lin, Shilei Cao, Sudong Wang, Haotian Wu, Minzhi Li, Linyi Yang, Juepeng Zheng, Chengwei Qin
分类: cs.AI
发布日期: 2025-09-30 (更新: 2025-10-02)
备注: The code is available at https://github.com/linhh29/Interactive-Learning-for-LLM-Reasoning
💡 一句话要点
提出ILR框架,通过交互式学习提升LLM独立推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多智能体学习 交互式学习 推理能力 协同学习
📋 核心要点
- 现有方法需多次执行多智能体系统才能获得最终解,与人类通过交互提升推理能力后独立解决问题的认知方式不符。
- ILR框架通过动态交互和感知校准,使LLM在交互中学习,从而提升其独立的推理和问题解决能力。
- 实验结果表明,ILR在数学和代码基准测试中始终优于单智能体学习,最高提升达5%,并验证了Idea3和动态交互的有效性。
📝 摘要(中文)
本文提出了一种新颖的协同学习框架ILR,用于多智能体系统(MAS),旨在提升大型语言模型(LLM)的独立问题解决能力。ILR包含两个关键组件:动态交互和感知校准。动态交互根据问题难度和模型能力自适应地选择合作或竞争策略,并通过Idea3(思想分享、思想分析和思想融合)这种模仿人类讨论的创新交互模式进行信息交换,最终得出各自的答案。在感知校准中,ILR采用群体相对策略优化(GRPO)来训练LLM,将一个LLM的奖励分布特征融入到另一个LLM的奖励函数中,从而增强多智能体交互的凝聚力。在五个数学基准测试和一个代码基准测试中,对三个LLM进行了验证,结果表明ILR始终优于单智能体学习,并且比最强的基线提高了高达5%。此外,Idea3可以增强较强LLM在多智能体推理过程中的鲁棒性,并且动态交互类型可以促进多智能体学习,优于纯合作或竞争策略。
🔬 方法详解
问题定义:现有基于多智能体学习的方法通过交互式训练环境来促进多个大型语言模型(LLM)之间的协作,从而构建更强大的多智能体系统(MAS)。然而,在推理过程中,这些方法需要重新执行MAS才能获得最终解决方案,这与人类通过与他人互动来增强推理能力并在未来独立解决问题的认知方式不同。因此,如何通过多智能体交互来增强LLM的独立问题解决能力是一个关键问题。
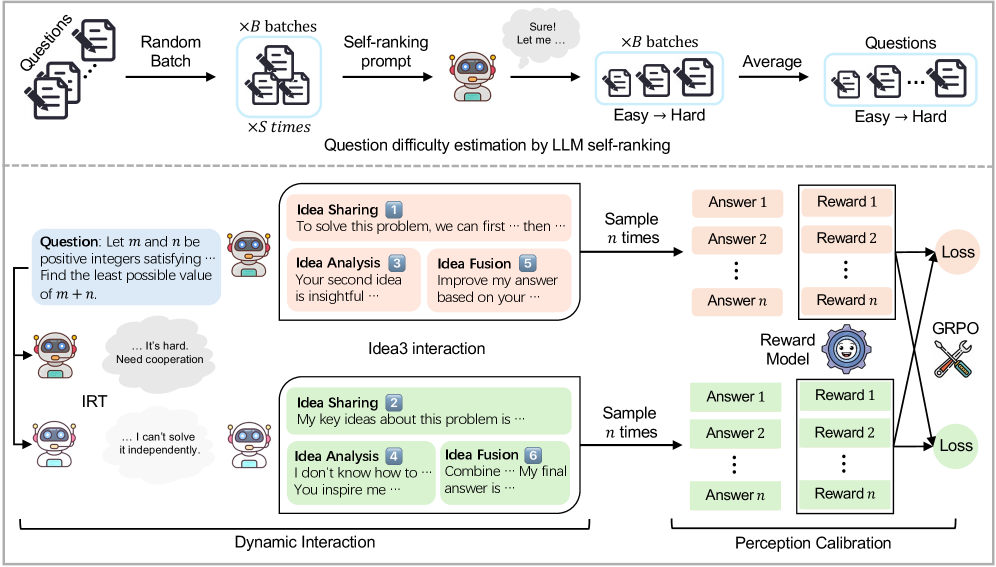
核心思路:ILR的核心思路是通过一个协同学习框架,使LLM在多智能体交互过程中学习,从而提升其独立的推理和问题解决能力。该框架包含动态交互和感知校准两个关键组件。动态交互模拟人类讨论,使LLM在合作和竞争中学习,而感知校准则增强了多智能体交互的凝聚力。
技术框架:ILR框架包含两个主要阶段:动态交互和感知校准。在动态交互阶段,首先根据问题难度和模型能力自适应地选择合作或竞争策略。然后,LLM通过Idea3(思想分享、思想分析和思想融合)这种创新交互模式进行信息交换,最后各自得出答案。在感知校准阶段,ILR采用群体相对策略优化(GRPO)来训练LLM,将一个LLM的奖励分布特征融入到另一个LLM的奖励函数中。
关键创新:ILR的关键创新在于以下几点:1) 提出了动态交互机制,能够根据问题难度和模型能力自适应地选择合作或竞争策略。2) 提出了Idea3交互模式,模拟人类讨论,促进LLM之间的信息交换和知识融合。3) 采用了GRPO进行感知校准,增强了多智能体交互的凝聚力。与现有方法相比,ILR更注重提升LLM的独立问题解决能力,而不是仅仅依赖多智能体协作。
关键设计:动态交互策略的选择基于问题难度和模型能力,具体实现细节未知。Idea3交互模式包含三个步骤:思想分享(LLM分享各自的想法)、思想分析(LLM分析其他LLM的想法)和思想融合(LLM融合其他LLM的想法)。GRPO的具体实现细节未知,但其核心思想是将一个LLM的奖励分布特征融入到另一个LLM的奖励函数中,从而使LLM之间的目标更加一致。
🖼️ 关键图片

📊 实验亮点
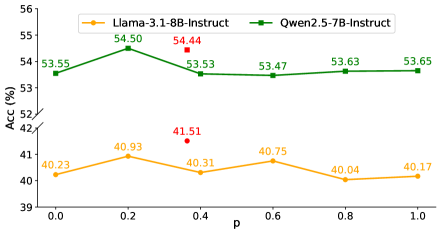
实验结果表明,ILR在五个数学基准测试和一个代码基准测试中始终优于单智能体学习,并且比最强的基线提高了高达5%。此外,实验还发现Idea3可以增强较强LLM在多智能体推理过程中的鲁棒性,并且动态交互类型可以促进多智能体学习,优于纯合作或竞争策略。这些结果验证了ILR框架的有效性和优越性。
🎯 应用场景
该研究成果可应用于需要LLM进行复杂推理和问题解决的各种场景,例如智能客服、自动化报告生成、代码生成、数学问题求解等。通过提升LLM的独立推理能力,可以减少对多智能体协作的依赖,提高系统的效率和鲁棒性。未来,该方法可以进一步扩展到其他类型的LLM和更复杂的任务中。
📄 摘要(原文)
Existing multi-agent learning approaches have developed interactive training environments to explicitly promote collaboration among multiple Large Language Models (LLMs), thereby constructing stronger multi-agent systems (MAS). However, during inference, they require re-executing the MAS to obtain final solutions, which diverges from human cognition that individuals can enhance their reasoning capabilities through interactions with others and resolve questions independently in the future. To investigate whether multi-agent interaction can enhance LLMs' independent problem-solving ability, we introduce ILR, a novel co-learning framework for MAS that integrates two key components: Dynamic Interaction and Perception Calibration. Specifically, Dynamic Interaction first adaptively selects either cooperative or competitive strategies depending on question difficulty and model ability. LLMs then exchange information through Idea3 (Idea Sharing, Idea Analysis, and Idea Fusion), an innovative interaction paradigm designed to mimic human discussion, before deriving their respective final answers. In Perception Calibration, ILR employs Group Relative Policy Optimization (GRPO) to train LLMs while integrating one LLM's reward distribution characteristics into another's reward function, thereby enhancing the cohesion of multi-agent interactions. We validate ILR on three LLMs across two model families of varying scales, evaluating performance on five mathematical benchmarks and one coding benchmark. Experimental results show that ILR consistently outperforms single-agent learning, yielding an improvement of up to 5% over the strongest baseline. We further discover that Idea3 can enhance the robustness of stronger LLMs during multi-agent inference, and dynamic interaction types can boost multi-agent learning compared to pure cooperative or competitive strategies.