SlimPack: Fine-Grained Asymmetric Packing for Balanced and Efficient Variable-Length LLM Training
作者: Yuliang Liu, Guohao Wu, Shenglong Zhang, Wei Zhang, Qianchao Zhu, Zhouyang Li, Chenyu Wang
分类: cs.AI
发布日期: 2025-09-30
💡 一句话要点
SlimPack:用于平衡高效变长LLM训练的细粒度非对称数据打包框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模语言模型 分布式训练 数据并行 负载均衡 变长文本
📋 核心要点
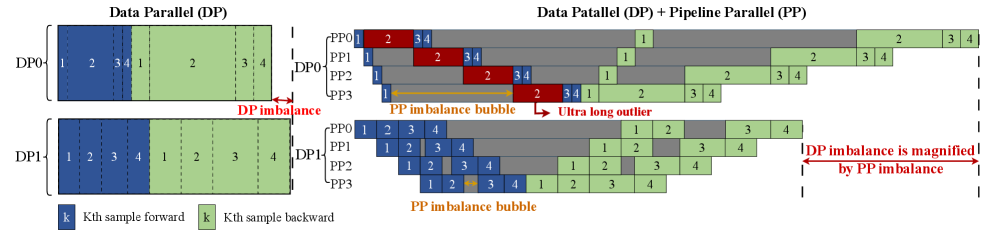
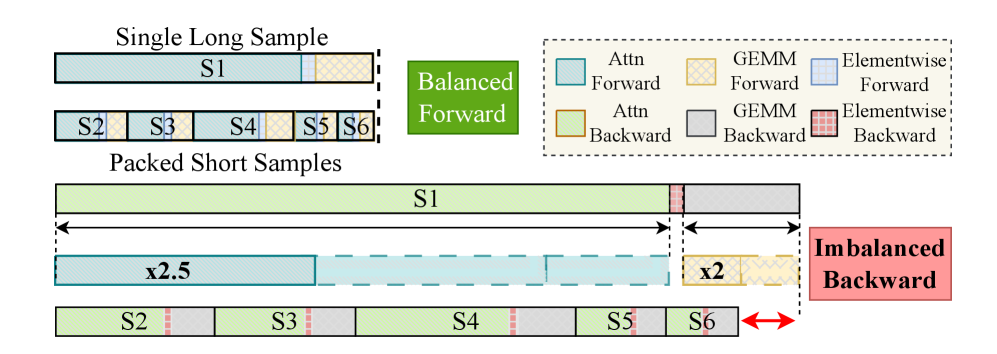
- 现有LLM训练方法在处理变长文本时,由于数据异构性导致负载不平衡和硬件利用率低。
- SlimPack将样本分解为细粒度切片,并采用非对称分区策略,优化前向和后向传递的负载平衡。
- 实验表明,SlimPack相比现有方法,训练吞吐量提升高达2.8倍,兼顾了平衡性和资源效率。
📝 摘要(中文)
大规模语言模型(LLM)的高效分布式训练受到上下文长度极端差异的严重阻碍。这种数据异构性,被传统打包策略和非对称前向-后向成本放大,导致了严重的低效率,例如级联式工作负载不平衡和严重的硬件利用率不足。现有的解决方案试图缓解这些挑战,但往往以牺牲内存或通信效率为代价。为了解决这些挑战,我们引入了SlimPack,一个通过将样本分解为细粒度切片来从根本上重新思考数据打包和调度的框架。这种切片级别的分解立即缓解了关键的内存和通信瓶颈,通过将大型、易变的工作负载转换为更小、可管理的单元流。这种灵活性被用于我们的核心创新,即非对称分区,它组装了专门为前向和后向传递的不同需求而优化的平衡调度单元。在两阶段求解器和高保真模拟器的协调下,SlimPack全面解决了所有并行维度上的不平衡问题。大量的实验表明,SlimPack实现了高达2.8倍于基线的训练吞吐量提升,打破了传统的权衡,实现了卓越的平衡和高资源效率。
🔬 方法详解
问题定义:大规模语言模型训练中,由于输入文本长度差异巨大,导致数据并行训练时各设备负载不均衡,降低了整体训练效率。传统的数据打包策略和前向-后向计算成本的不对称性进一步加剧了这个问题。现有方法通常以牺牲内存或通信效率为代价来缓解负载不平衡。
核心思路:SlimPack的核心思想是将输入样本分解为细粒度的切片,然后根据前向和后向计算的不同需求,采用非对称分区策略,将这些切片打包成平衡的调度单元。通过这种方式,SlimPack能够更灵活地分配工作负载,从而提高训练效率。
技术框架:SlimPack框架主要包含以下几个阶段:1) 切片分解:将输入样本分解为细粒度的切片。2) 非对称分区:根据前向和后向计算的不同需求,将切片打包成平衡的调度单元。3) 两阶段求解器:使用两阶段求解器来优化切片打包方案,以实现最佳的负载平衡。4) 高保真模拟器:使用高保真模拟器来评估切片打包方案的性能。
关键创新:SlimPack的关键创新在于其细粒度的切片分解和非对称分区策略。与传统的打包策略相比,SlimPack能够更灵活地分配工作负载,从而更好地平衡前向和后向计算的负载。此外,SlimPack的两阶段求解器和高保真模拟器能够有效地优化切片打包方案,进一步提高训练效率。
关键设计:SlimPack的关键设计包括:1) 切片大小的选择:切片大小的选择会影响负载平衡的粒度和通信开销。2) 非对称分区策略的设计:需要根据前向和后向计算的不同需求,设计不同的分区策略。3) 两阶段求解器的优化目标:需要设计合适的优化目标,以实现最佳的负载平衡。4) 高保真模拟器的精度:需要保证模拟器的精度,以便准确评估切片打包方案的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SlimPack在LLM训练中实现了高达2.8倍的吞吐量提升,优于现有的数据打包和调度策略。SlimPack在提高训练效率的同时,还保持了较高的资源利用率,打破了传统方法在平衡性和资源效率之间的权衡。
🎯 应用场景
SlimPack适用于大规模语言模型的分布式训练,尤其是在处理变长文本数据时。它可以显著提高训练效率,降低训练成本,并加速LLM的开发和部署。该技术也可应用于其他具有类似负载不平衡问题的机器学习任务,例如语音识别、机器翻译等。
📄 摘要(原文)
The efficient distributed training of Large Language Models (LLMs) is severely hampered by the extreme variance in context lengths. This data heterogeneity, amplified by conventional packing strategies and asymmetric forward-backward costs, leads to critical inefficiencies such as cascading workload imbalances and severe hardware underutilization. Existing solutions attempt to mitigate these challenges, but often at the expense of memory or communication efficiency. To address these challenges, we introduce SlimPack, a framework that fundamentally rethinks data packing and scheduling by decomposing samples into fine-grained slices. This slice-level decomposition immediately mitigates critical memory and communication bottlenecks by transforming large, volatile workloads into a stream of smaller, manageable units. This flexibility is then harnessed for our core innovation, Asymmetric Partitioning, which assembles balanced scheduling units uniquely optimized for the different demands of the forward and backward passes. Orchestrated by a two-phase solver and a high-fidelity simulator, SlimPack holistically resolves imbalances across all parallel dimensions. Extensive experiments demonstrate that SlimPack achieves up to a $2.8\times$ training throughput improvement over baselines, breaking the conventional trade-off by delivering both superior balance and high resource efficiency.