Human-Centered Evaluation of RAG outputs: a framework and questionnaire for human-AI collaboration
作者: Aline Mangold, Kiran Hoffmann
分类: cs.AI
发布日期: 2025-09-30
💡 一句话要点
提出人本评估框架以优化RAG系统输出
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人本评估 RAG系统 用户意图 文本结构 信息可验证性 人机协作 大型语言模型
📋 核心要点
- 现有的RAG系统输出评估缺乏系统性的人本视角,导致评估结果的可靠性不足。
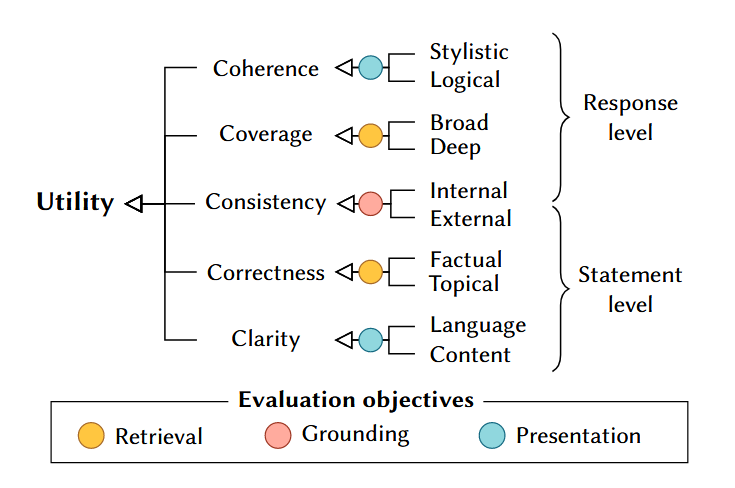
- 本文提出了一种基于Gienapp框架的人本问卷,涵盖12个评估维度,旨在提升RAG系统的输出质量。
- 实验结果显示,LLM在度量描述上表现良好,但在文本格式变化的检测上存在不足,且人类与LLM评分一致性较低。
📝 摘要(中文)
检索增强生成(RAG)系统在用户应用中的部署日益增多,但其输出的系统性人本评估仍未得到充分探索。基于Gienapp的效用维度框架,本文设计了一份人本问卷,评估RAG输出的12个维度。通过对一组查询-输出对的多轮评分和语义讨论,迭代完善了问卷。最终,结合了人类评分者和人类-大语言模型(LLM)对的反馈。结果表明,尽管大型语言模型(LLMs)在关注度量描述和规模标签方面表现可靠,但在检测文本格式变化方面存在不足。人类在严格关注度量描述和标签方面也面临挑战。LLM的评分和解释被视为有益的支持,但数值上的一致性不足。最终问卷通过关注用户意图、文本结构和信息可验证性扩展了初始框架。
🔬 方法详解
问题定义:本文旨在解决RAG系统输出评估中缺乏系统性人本视角的问题。现有方法未能充分考虑用户意图和信息可验证性,导致评估结果的有效性和可靠性不足。
核心思路:通过设计一份人本问卷,涵盖12个维度,评估RAG输出的质量,重点关注用户意图、文本结构和信息的可验证性,以提升评估的全面性和准确性。
技术框架:整体架构包括问卷设计、迭代评分和反馈整合三个主要阶段。首先设计问卷,随后进行多轮评分和讨论,最后整合人类评分者和LLM的反馈。
关键创新:最重要的创新点在于将用户意图和信息可验证性纳入评估框架,区别于传统方法仅关注输出的度量描述和格式。
关键设计:问卷设计中,设置了12个评估维度,涵盖了用户体验的多个方面,确保评估结果的多维度和全面性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在度量描述和规模标签方面表现良好,但在文本格式变化的检测上存在明显不足。人类评分者与LLM评分之间的一致性较低,显示出传统评估方法的局限性。
🎯 应用场景
该研究的潜在应用领域包括人机协作系统、智能客服、内容生成等。通过优化RAG系统的输出评估,可以提升用户体验和系统的实用性,推动人机协作的进一步发展。
📄 摘要(原文)
Retrieval-augmented generation (RAG) systems are increasingly deployed in user-facing applications, yet systematic, human-centered evaluation of their outputs remains underexplored. Building on Gienapp's utility-dimension framework, we designed a human-centred questionnaire that assesses RAG outputs across 12 dimensions. We iteratively refined the questionnaire through several rounds of ratings on a set of query-output pairs and semantic discussions. Ultimately, we incorporated feedback from both a human rater and a human-LLM pair. Results indicate that while large language models (LLMs) reliably focus on metric descriptions and scale labels, they exhibit weaknesses in detecting textual format variations. Humans struggled to focus strictly on metric descriptions and labels. LLM ratings and explanations were viewed as a helpful support, but numeric LLM and human ratings lacked agreement. The final questionnaire extends the initial framework by focusing on user intent, text structuring, and information verifiability.