OWL: Geometry-Aware Spatial Reasoning for Audio Large Language Models
作者: Subrata Biswas, Mohammad Nur Hossain Khan, Bashima Islam
分类: cs.SD, cs.AI
发布日期: 2025-09-30
💡 一句话要点
提出OWL模型,通过几何感知空间推理提升音频大语言模型对声源定位的精度和可解释性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频大语言模型 空间推理 几何感知 双耳音频 声源定位
📋 核心要点
- 现有音频大语言模型在空间推理上依赖粗糙的双耳线索和单步推理,缺乏几何感知能力,限制了定位精度和可解释性。
- 论文提出空间声学几何编码器(SAGE)和OWL模型,利用全景深度图像和房间脉冲响应进行训练,提升模型对声源方向和距离的感知能力。
- 实验结果表明,OWL模型在DoA估计和空间推理QA任务上显著优于现有方法,平均DoA误差降低11°,空间推理QA精度提升高达25%。
📝 摘要(中文)
当前音频大语言模型(ALLMs)主要依赖非结构化的双耳线索和单步推理,这限制了方向和距离估计的感知精度和可解释推理能力。本文提出了空间声学几何编码器(SAGE),它是一种几何感知的音频编码器,在训练时使用全景深度图像和房间脉冲响应将双耳声学特征与3D空间结构对齐,而在推理时仅需要音频。在此基础上,提出了OWL,一个ALLM,它将SAGE与空间接地的思维链相结合,以合理化到达方向(DoA)和距离估计。通过从感知QA到多步推理的课程学习,OWL支持时钟级别的方位角和DoA估计。为了实现大规模训练和评估,构建并发布了BiDepth数据集,该数据集包含超过一百万个QA对,结合了双耳音频与全景深度图像和室内外场景的房间脉冲响应。在两个基准数据集BiDepth和公开的SpatialSoundQA上,OWL通过SAGE将平均DoA误差降低了11°,并将空间推理QA精度提高了高达25%。
🔬 方法详解
问题定义:现有音频大语言模型在处理空间音频推理任务时,主要依赖于非结构化的双耳线索,并且通常采用单步推理的方式。这种方式的缺点在于,对声源方向和距离的估计精度较低,并且缺乏可解释性。此外,现有方法通常使用粗粒度的类别标签(如左、右、上、下)进行空间信息的表示,这进一步限制了模型的性能。
核心思路:论文的核心思路是引入几何感知能力,将双耳声学特征与3D空间结构对齐。具体来说,通过在训练阶段利用全景深度图像和房间脉冲响应,使模型能够学习到声源的空间几何信息。在推理阶段,模型仅需音频输入,即可进行精确的空间推理。
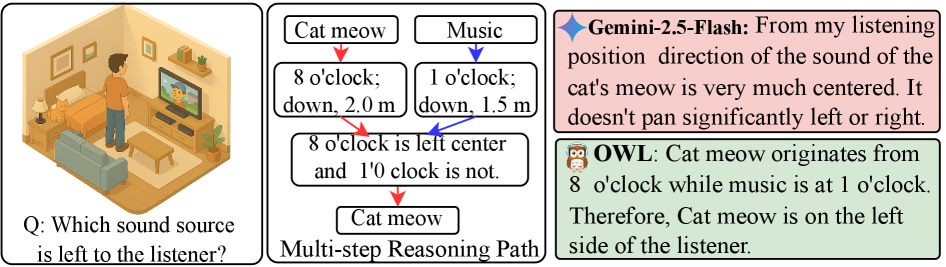
技术框架:OWL模型的整体框架包含两个主要组成部分:空间声学几何编码器(SAGE)和空间接地的思维链。SAGE负责将双耳音频特征编码为包含空间几何信息的表示。空间接地的思维链则利用SAGE的输出,进行多步推理,以估计声源的到达方向(DoA)和距离。整个训练过程采用课程学习策略,从简单的感知QA任务逐渐过渡到复杂的多步推理任务。
关键创新:论文的关键创新在于SAGE的设计,它通过将双耳声学特征与3D空间结构对齐,实现了几何感知的音频编码。与现有方法相比,SAGE能够更精确地捕捉声源的空间信息,从而提升模型的空间推理能力。此外,OWL模型采用空间接地的思维链,能够进行可解释的多步推理,这使得模型能够更好地理解声源的空间关系。
关键设计:SAGE的具体实现细节未知,论文中提到使用了全景深度图像和房间脉冲响应进行训练,但未详细说明具体的网络结构和损失函数。OWL模型采用课程学习策略,从简单的感知QA任务逐渐过渡到复杂的多步推理任务,这有助于模型更好地学习空间推理能力。BiDepth数据集的构建是另一个关键设计,它提供了大规模的训练数据,包含双耳音频、全景深度图像和房间脉冲响应,为模型的训练提供了充足的资源。
🖼️ 关键图片

📊 实验亮点
OWL模型在BiDepth和SpatialSoundQA两个数据集上进行了评估。实验结果表明,OWL模型显著优于现有方法,在DoA估计任务上,平均误差降低了11°。在空间推理QA任务上,精度提升高达25%。这些结果表明,SAGE和空间接地的思维链能够有效地提升音频大语言模型的空间推理能力。
🎯 应用场景
该研究成果可应用于智能家居、机器人导航、虚拟现实等领域。例如,在智能家居中,可以通过分析室内声音来定位声源,从而实现更智能的语音控制和环境感知。在机器人导航中,可以利用声源定位信息来辅助机器人进行自主导航和避障。在虚拟现实中,可以提供更逼真的空间音频体验,增强用户的沉浸感。
📄 摘要(原文)
Spatial reasoning is fundamental to auditory perception, yet current audio large language models (ALLMs) largely rely on unstructured binaural cues and single step inference. This limits both perceptual accuracy in direction and distance estimation and the capacity for interpretable reasoning. Recent work such as BAT demonstrates spatial QA with binaural audio, but its reliance on coarse categorical labels (left, right, up, down) and the absence of explicit geometric supervision constrain resolution and robustness. We introduce the $\textbf{Spatial-Acoustic Geometry Encoder (SAGE}$), a geometry-aware audio encoder that aligns binaural acoustic features with 3D spatial structure using panoramic depth images and room-impulse responses at training time, while requiring only audio at inference. Building on this representation, we present $\textbf{OWL}$, an ALLM that integrates $\textbf{SAGE}$ with a spatially grounded chain-of-thought to rationalize over direction-of-arrivals (DoA) and distance estimates. Through curriculum learning from perceptual QA to multi-step reasoning, $\textbf{OWL}$ supports o'clock-level azimuth and DoA estimation. To enable large-scale training and evaluation, we construct and release $\textbf{BiDepth}$, a dataset of over one million QA pairs combining binaural audio with panoramic depth images and room impulse responses across both in-room and out-of-room scenarios. Across two benchmark datasets, our new $\textbf{BiDepth}$ and the public SpatialSoundQA, $\textbf{OWL}$ reduces mean DoA error by $\textbf{11$^{\circ}$}$ through $\textbf{SAGE}$ and improves spatial reasoning QA accuracy by up to $\textbf{25}$\% over BAT.