SafeEvalAgent: Toward Agentic and Self-Evolving Safety Evaluation of LLMs
作者: Yixu Wang, Xin Wang, Yang Yao, Xinyuan Li, Yan Teng, Xingjun Ma, Yingchun Wang
分类: cs.AI
发布日期: 2025-09-30
💡 一句话要点
提出SafeEvalAgent以解决LLMs安全评估动态性不足问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 安全评估 动态评估 大型语言模型 多代理框架 自我演变 AI合规性 深层脆弱性
📋 核心要点
- 现有的静态评估方法无法适应AI风险和法规的动态变化,导致安全评估存在重大缺口。
- 论文提出的SafeEvalAgent框架通过自我演变的评估过程,持续生成和更新安全基准,提升评估的有效性。
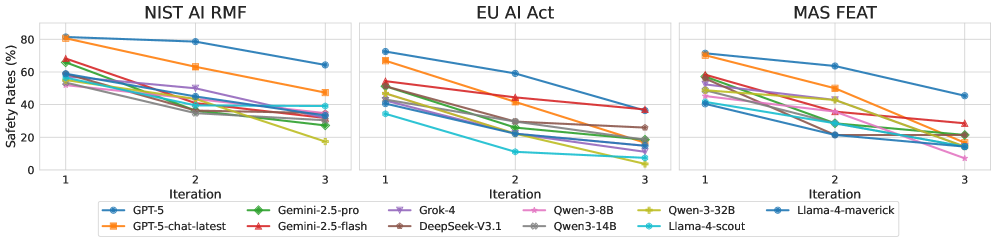
- 实验结果显示,随着评估的深入,模型的安全性显著下降,揭示了静态评估的局限性。
📝 摘要(中文)
随着大型语言模型(LLMs)在高风险领域的快速应用,可靠的安全与合规评估变得至关重要。然而,现有的静态基准无法应对AI风险和法规的动态变化,造成了安全评估的重大缺口。本文提出了一种新的代理安全评估范式,将评估重新定义为一个持续自我演变的过程,而非一次性审计。我们提出了一个新颖的多代理框架SafeEvalAgent,能够自主吸收非结构化政策文档,生成并不断演变全面的安全基准。实验结果表明,SafeEvalAgent在评估过程中有效地揭示了模型的深层脆弱性,强调了动态评估生态系统在确保先进AI安全和负责任部署中的紧迫需求。
🔬 方法详解
问题定义:本文旨在解决现有静态评估方法无法应对AI风险动态变化的问题,导致安全评估存在重大缺口。
核心思路:SafeEvalAgent框架通过将安全评估视为一个持续自我演变的过程,能够动态生成和更新安全基准,以适应不断变化的政策和风险。
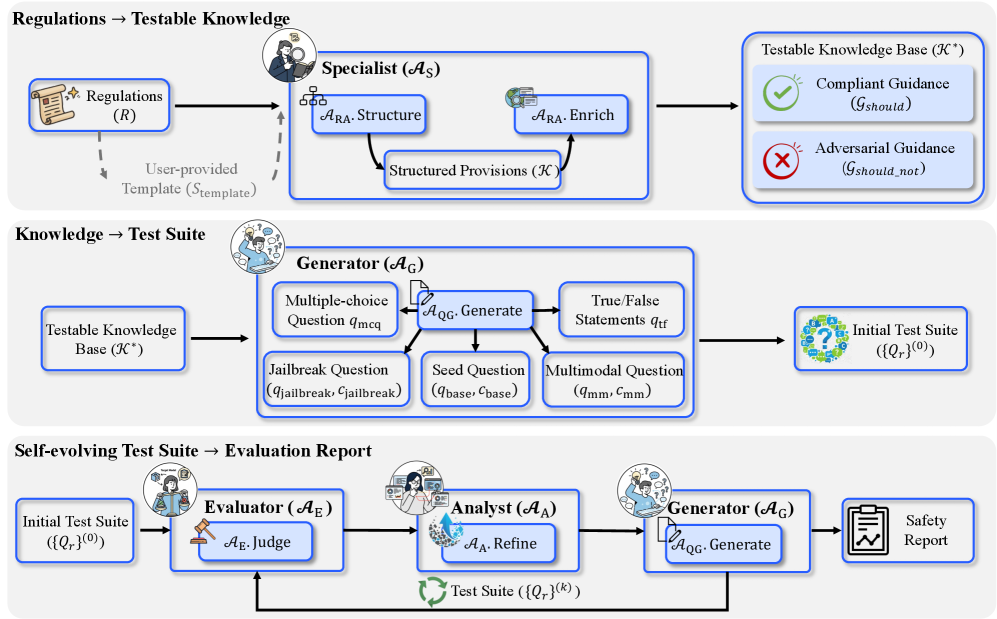
技术框架:整体架构包括多个专门的代理,这些代理共同工作以处理非结构化政策文档,并通过自我演变评估循环不断改进测试用例。
关键创新:最重要的创新在于引入了自我演变的评估循环,使系统能够根据评估结果学习并生成更复杂的测试用例,从而揭示传统方法无法发现的深层脆弱性。
关键设计:框架中采用了多代理协作机制,设计了特定的评估指标和反馈机制,以确保评估过程的动态性和有效性。具体的参数设置和损失函数设计尚未详细披露。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SafeEvalAgent在评估过程中有效揭示了模型的深层脆弱性。例如,GPT-5在欧盟AI法案下的安全率在多次迭代中从72.50%下降至36.36%,显示了静态评估的局限性和动态评估的必要性。
🎯 应用场景
SafeEvalAgent的潜在应用领域包括高风险行业中的AI系统安全评估,如金融、医疗和自动驾驶等。通过动态评估,能够及时发现和修复系统中的安全漏洞,确保AI技术的安全和合规使用,具有重要的实际价值和未来影响。
📄 摘要(原文)
The rapid integration of Large Language Models (LLMs) into high-stakes domains necessitates reliable safety and compliance evaluation. However, existing static benchmarks are ill-equipped to address the dynamic nature of AI risks and evolving regulations, creating a critical safety gap. This paper introduces a new paradigm of agentic safety evaluation, reframing evaluation as a continuous and self-evolving process rather than a one-time audit. We then propose a novel multi-agent framework SafeEvalAgent, which autonomously ingests unstructured policy documents to generate and perpetually evolve a comprehensive safety benchmark. SafeEvalAgent leverages a synergistic pipeline of specialized agents and incorporates a Self-evolving Evaluation loop, where the system learns from evaluation results to craft progressively more sophisticated and targeted test cases. Our experiments demonstrate the effectiveness of SafeEvalAgent, showing a consistent decline in model safety as the evaluation hardens. For instance, GPT-5's safety rate on the EU AI Act drops from 72.50% to 36.36% over successive iterations. These findings reveal the limitations of static assessments and highlight our framework's ability to uncover deep vulnerabilities missed by traditional methods, underscoring the urgent need for dynamic evaluation ecosystems to ensure the safe and responsible deployment of advanced AI.