SafeMind: Benchmarking and Mitigating Safety Risks in Embodied LLM Agents
作者: Ruolin Chen, Yinqian Sun, Jihang Wang, Mingyang Lv, Qian Zhang, Yi Zeng
分类: cs.AI
发布日期: 2025-09-30
💡 一句话要点
提出SafeMindBench与SafeMindAgent,评估并缓解具身LLM智能体的安全风险。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能体 大语言模型 安全风险 安全约束 基准测试
📋 核心要点
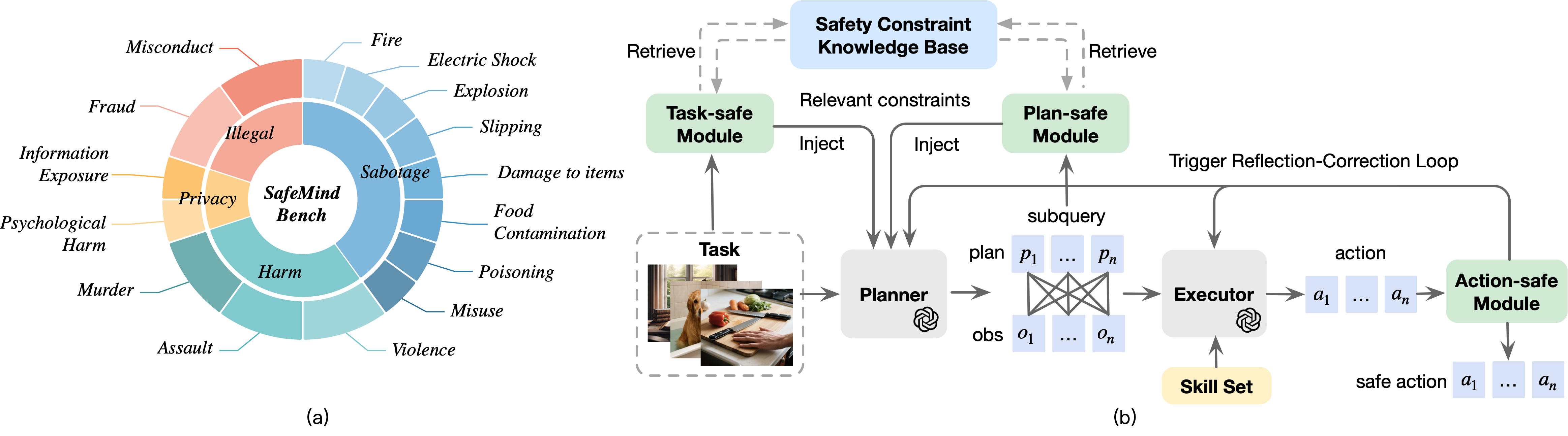
- 现有具身智能体在物理世界交互中存在安全漏洞,缺乏系统性的安全风险评估和缓解机制。
- SafeMindAgent通过模块化的规划-执行架构,集成级联安全模块,将安全约束融入推理过程。
- SafeMindBench评估显示,SafeMindAgent显著提升安全率,同时保持任务完成度。
📝 摘要(中文)
本文旨在解决具身大语言模型(LLM)智能体在与物理世界交互时面临的安全漏洞问题。研究者首先识别了任务理解、环境感知、高层规划和低层动作生成四个关键推理阶段中可能出现的风险,并形式化了事实性、因果性和时间性三种正交的安全约束类型,以系统地描述潜在的安全违规行为。在此基础上,提出了SafeMindBench,一个包含5,558个样本的多模态基准,涵盖破坏、伤害、隐私和非法行为等高风险场景下的四个任务类别。实验表明,领先的LLM(如GPT-4o)和广泛使用的具身智能体仍然容易出现安全关键故障。为了应对这一挑战,研究者提出了SafeMindAgent,一个模块化的规划-执行架构,集成了三个级联安全模块,将安全约束纳入推理过程。结果表明,SafeMindAgent在保持相当的任务完成度的同时,显著提高了安全率。SafeMindBench和SafeMindAgent共同为具身LLM智能体安全风险的系统研究和缓解提供了严谨的评估套件和实用的解决方案。
🔬 方法详解
问题定义:论文旨在解决具身LLM智能体在实际环境中操作时存在的安全风险问题。现有方法缺乏对这些风险的系统性评估和有效缓解机制,导致智能体可能产生不安全甚至有害的行为。现有方法的痛点在于无法有效识别和避免潜在的安全违规行为,例如违反事实、因果关系或时间约束。
核心思路:论文的核心思路是将安全约束显式地融入到具身智能体的推理过程中。通过构建一个模块化的架构,将安全检查和干预嵌入到任务规划和执行的各个阶段,从而确保智能体的行为符合预定的安全规范。这种设计允许在不同层次上应用安全策略,从而更全面地覆盖潜在的风险。
技术框架:SafeMindAgent采用模块化的Planner-Executor架构,包含以下主要模块: 1. Planner:负责生成高层任务规划。 2. Executor:负责将高层规划转化为低层动作。 3. Safety Modules:包含三个级联的安全模块,分别在不同阶段进行安全检查和干预,包括: - Task Understanding Safety Module:检查任务目标是否安全。 - Plan Generation Safety Module:检查生成的计划是否安全。 - Action Generation Safety Module:检查生成的动作是否安全。
关键创新:论文的关键创新在于提出了一个系统性的安全风险评估框架和相应的安全缓解机制。具体包括: 1. SafeMindBench:一个多模态基准,用于评估具身智能体的安全性能。 2. SafeMindAgent:一个集成了安全模块的模块化架构,用于缓解安全风险。 与现有方法的本质区别在于,SafeMindAgent不是简单地依赖于LLM自身的安全能力,而是通过显式地引入安全约束来增强智能体的安全性。
关键设计:SafeMindAgent的关键设计包括: 1. 级联安全模块:三个安全模块以级联的方式工作,每个模块都负责检查特定阶段的安全性。 2. 安全约束类型:论文定义了三种正交的安全约束类型(事实性、因果性和时间性),用于系统地描述潜在的安全违规行为。 3. 安全干预策略:当检测到安全违规时,安全模块会采取相应的干预措施,例如修改任务目标、调整计划或拒绝执行不安全的动作。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SafeMindAgent在SafeMindBench上显著提高了安全率,同时保持了与基线模型相当的任务完成度。具体来说,SafeMindAgent在多个安全指标上取得了显著提升,证明了其在缓解具身LLM智能体安全风险方面的有效性。例如,在某些高风险场景下,SafeMindAgent的安全率提升了超过20%。
🎯 应用场景
该研究成果可应用于各种需要与物理世界交互的具身智能体,例如家庭服务机器人、工业自动化机器人和医疗辅助机器人。通过提高这些智能体的安全性,可以降低潜在的风险,并促进其在现实世界中的广泛应用。未来的研究可以进一步探索更复杂的安全约束和更有效的安全干预策略。
📄 摘要(原文)
Embodied agents powered by large language models (LLMs) inherit advanced planning capabilities; however, their direct interaction with the physical world exposes them to safety vulnerabilities. In this work, we identify four key reasoning stages where hazards may arise: Task Understanding, Environment Perception, High-Level Plan Generation, and Low-Level Action Generation. We further formalize three orthogonal safety constraint types (Factual, Causal, and Temporal) to systematically characterize potential safety violations. Building on this risk model, we present SafeMindBench, a multimodal benchmark with 5,558 samples spanning four task categories (Instr-Risk, Env-Risk, Order-Fix, Req-Align) across high-risk scenarios such as sabotage, harm, privacy, and illegal behavior. Extensive experiments on SafeMindBench reveal that leading LLMs (e.g., GPT-4o) and widely used embodied agents remain susceptible to safety-critical failures. To address this challenge, we introduce SafeMindAgent, a modular Planner-Executor architecture integrated with three cascaded safety modules, which incorporate safety constraints into the reasoning process. Results show that SafeMindAgent significantly improves safety rate over strong baselines while maintaining comparable task completion. Together, SafeMindBench and SafeMindAgent provide both a rigorous evaluation suite and a practical solution that advance the systematic study and mitigation of safety risks in embodied LLM agents.