Better with Less: Small Proprietary Models Surpass Large Language Models in Financial Transaction Understanding
作者: Wanying Ding, Savinay Narendra, Xiran Shi, Adwait Ratnaparkhi, Chengrui Yang, Nikoo Sabzevar, Ziyan Yin
分类: cs.IR, cs.AI, cs.CE, cs.LG
发布日期: 2025-09-30
备注: 9 pages, 5 figures
💡 一句话要点
小规模私有模型在金融交易理解任务上超越大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金融交易理解 小规模模型 私有模型 Transformer模型 领域自适应 成本效益 解码器模型
📋 核心要点
- 现有大型语言模型(LLM)在金融交易理解等特定领域表现不佳,成本高昂且效率低下。
- 论文提出针对金融交易数据定制的小规模私有模型,旨在提升性能并降低成本。
- 实验表明,私有模型在速度和成本效益方面优于LLM,并成功提升了交易覆盖率和降低了年度成本。
📝 摘要(中文)
分析金融交易对于确保合规性、检测欺诈和支持决策至关重要。金融交易数据的复杂性需要先进的技术来提取有意义的见解并确保准确的分析。由于基于Transformer的模型在多个领域表现出色,本文旨在探索它们在理解金融交易方面的潜力。本文进行了广泛的实验,以评估三种类型的Transformer模型:仅编码器、仅解码器和编码器-解码器模型。对于每种类型,我们探索了三种选择:预训练的LLM、微调的LLM和从头开始开发的小型私有模型。我们的分析表明,虽然LLM(如LLaMA3-8b、Flan-T5和SBERT)在各种自然语言处理任务中表现出令人印象深刻的能力,但在金融交易理解的特定背景下,它们并没有明显优于小型私有模型。这种现象在速度和成本效率方面尤为明显。专为交易数据的独特需求量身定制的私有模型表现出更快的处理速度和更低的运营成本,使其更适合金融领域的实时应用。我们的研究结果强调了基于领域特定需求选择模型的重要性,并强调了定制私有模型在专门应用中相对于通用LLM的潜在优势。最终,我们选择实施一个私有的仅解码器模型来处理我们之前无法管理的复杂交易。该模型可以帮助我们提高14%的交易覆盖率,并节省超过1300万美元的年度成本。
🔬 方法详解
问题定义:论文旨在解决金融交易理解任务中,通用大型语言模型(LLM)在特定领域表现不佳、成本高昂且效率低下的问题。现有方法依赖于通用LLM,未能充分利用金融交易数据的独特性,导致性能瓶颈和资源浪费。
核心思路:论文的核心思路是针对金融交易数据的特点,设计和训练小规模的私有模型。通过定制化模型结构和训练数据,使模型能够更好地理解和处理金融交易信息,从而在性能、速度和成本效益方面超越通用LLM。
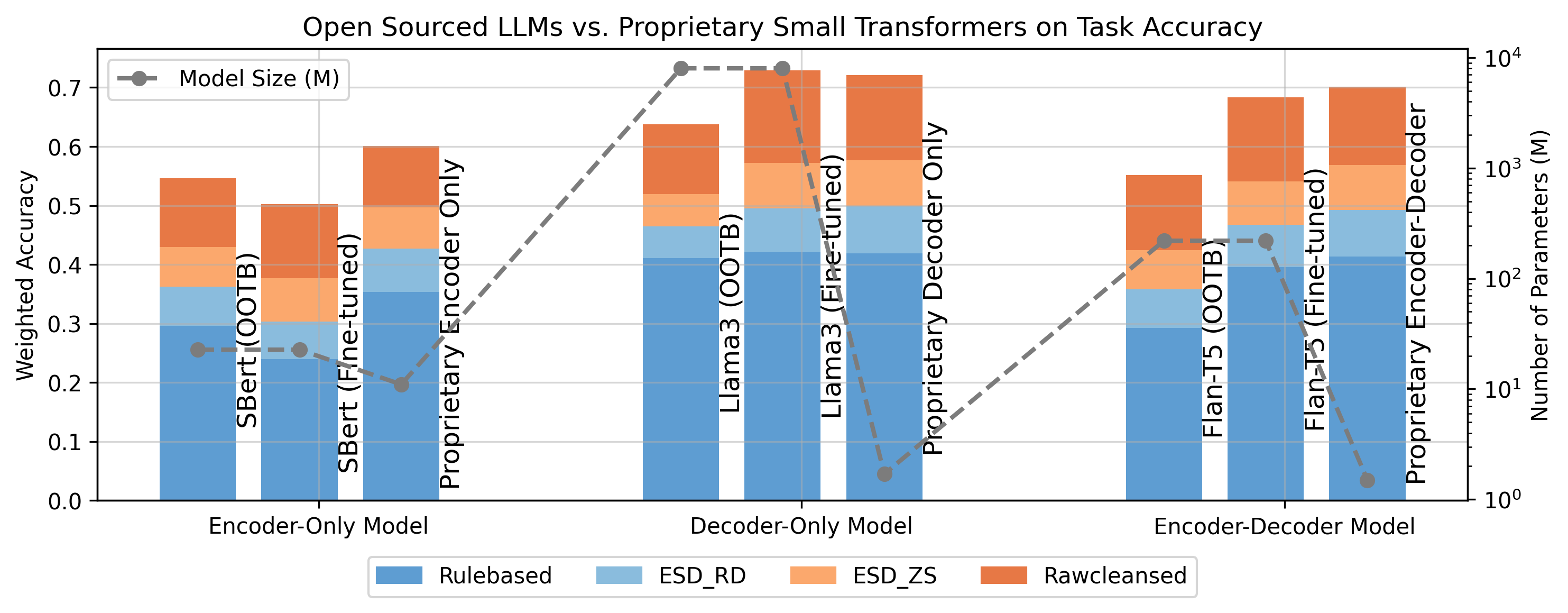
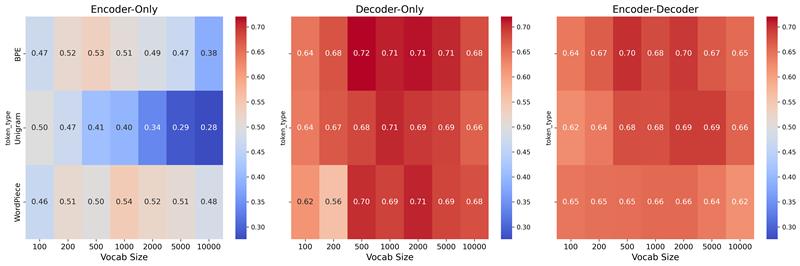
技术框架:论文评估了三种类型的Transformer模型:Encoder-Only、Decoder-Only和Encoder-Decoder模型。对于每种类型,都探索了三种选择:预训练的LLM、微调的LLM和从头开始开发的小型私有模型。最终选择并实现了一个私有的仅解码器模型。整体流程包括数据预处理、模型选择与设计、模型训练与调优、以及模型评估与部署。
关键创新:最重要的技术创新点在于针对金融交易理解任务,定制化设计和训练小规模私有模型。与现有方法依赖通用LLM不同,该方法充分利用了金融交易数据的领域知识,通过定制化模型结构和训练数据,实现了更高的性能和效率。
关键设计:论文中关键的设计细节包括:选择Decoder-Only架构,可能更适合生成式任务;从头开始训练模型,避免了预训练模型可能存在的领域知识偏差;针对金融交易数据特点,设计了特定的数据预处理和增强方法;以及针对模型性能,设计了特定的评估指标。
🖼️ 关键图片
📊 实验亮点
实验结果表明,定制的小规模私有模型在金融交易理解任务中优于大型语言模型(如LLaMA3-8b、Flan-T5和SBERT)。具体而言,该私有模型能够提高14%的交易覆盖率,并节省超过1300万美元的年度成本。这些数据表明,在特定领域,定制化模型具有显著的优势。
🎯 应用场景
该研究成果可应用于金融行业的多个领域,包括反欺诈检测、合规性检查、交易风险评估和客户服务。通过更准确、高效地理解金融交易数据,可以帮助金融机构降低运营成本、提高风险管理能力,并为客户提供更优质的服务。未来,该方法有望推广到其他具有类似领域特征的专业领域。
📄 摘要(原文)
Analyzing financial transactions is crucial for ensuring regulatory compliance, detecting fraud, and supporting decisions. The complexity of financial transaction data necessitates advanced techniques to extract meaningful insights and ensure accurate analysis. Since Transformer-based models have shown outstanding performance across multiple domains, this paper seeks to explore their potential in understanding financial transactions. This paper conducts extensive experiments to evaluate three types of Transformer models: Encoder-Only, Decoder-Only, and Encoder-Decoder models. For each type, we explore three options: pretrained LLMs, fine-tuned LLMs, and small proprietary models developed from scratch. Our analysis reveals that while LLMs, such as LLaMA3-8b, Flan-T5, and SBERT, demonstrate impressive capabilities in various natural language processing tasks, they do not significantly outperform small proprietary models in the specific context of financial transaction understanding. This phenomenon is particularly evident in terms of speed and cost efficiency. Proprietary models, tailored to the unique requirements of transaction data, exhibit faster processing times and lower operational costs, making them more suitable for real-time applications in the financial sector. Our findings highlight the importance of model selection based on domain-specific needs and underscore the potential advantages of customized proprietary models over general-purpose LLMs in specialized applications. Ultimately, we chose to implement a proprietary decoder-only model to handle the complex transactions that we previously couldn't manage. This model can help us to improve 14% transaction coverage, and save more than \$13 million annual cost.