AutoCode: LLMs as Problem Setters for Competitive Programming
作者: Shang Zhou, Zihan Zheng, Kaiyuan Liu, Zeyu Shen, Zerui Cheng, Zexing Chen, Hansen He, Jianzhu Yao, Huanzhi Mao, Qiuyang Mang, Tianfu Fu, Beichen Li, Dongruixuan Li, Wenhao Chai, Zhuang Liu, Aleksandra Korolova, Peter Henderson, Natasha Jaques, Pramod Viswanath, Saining Xie, Jingbo Shang
分类: cs.SE, cs.AI, cs.CL, cs.PL
发布日期: 2025-09-29
备注: Project page: https://livecodebenchpro.com/projects/autocode/overview
💡 一句话要点
AutoCode:利用大语言模型自动生成高质量的竞赛编程题目
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 竞赛编程 自动题目生成 测试用例生成 多轮验证
📋 核心要点
- 现有竞赛编程题目生成方法难以保证题目质量,尤其是在约束条件、边界情况和难度校准方面存在挑战。
- AutoCode利用大语言模型,通过多轮验证和交叉验证,自动生成高质量的题目描述和测试用例,并过滤掉错误题目。
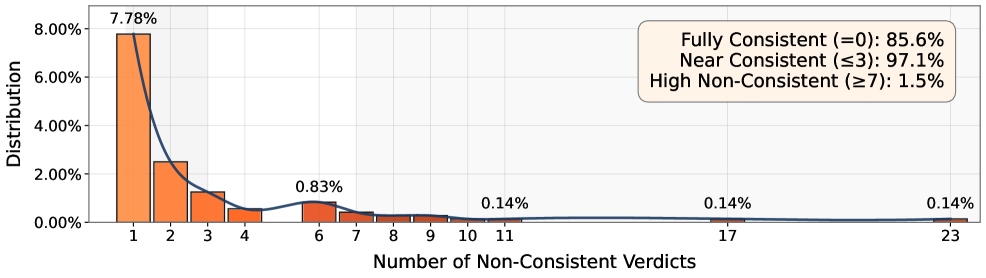
- 实验表明,AutoCode生成的测试套件与官方判定的结果一致性接近99%,显著优于现有方法,并能生成高质量的新题目。
📝 摘要(中文)
编写竞赛编程题目极具挑战性。出题者必须设定约束条件、输入分布和排除作弊的边界情况;针对特定的算法(例如,最大流、动态规划、数据结构);并校准难度,使其超出大多数参赛者的能力范围。我们认为这非常适合测试通用大语言模型的能力,并研究它们是否能够可靠地完成这项任务。我们提出了AutoCode,它使用多轮验证来生成竞赛级别的题目描述和测试用例。在保留的问题上,AutoCode测试套件与官方判定的结果一致性接近99%,与当前最先进的方法(如HardTests,一致性低于81%)相比,有了显著的提高。此外,从一个随机种子问题开始,AutoCode可以创建具有参考解决方案和暴力破解解决方案的新变体。通过交叉验证这些生成的解决方案与测试用例,我们可以进一步过滤掉格式错误的题目。我们的系统确保了高正确性,并经过了人类专家的验证。AutoCode成功地生成了由Grandmaster级别(前0.3%)的竞赛程序员判断为具有竞赛质量的新题目。
🔬 方法详解
问题定义:论文旨在解决自动生成高质量竞赛编程题目的问题。现有方法,如HardTests,在生成测试用例时,与官方判定的结果一致性较低,难以保证题目的正确性和难度。人工编写题目成本高昂,且难以覆盖各种算法和难度级别。
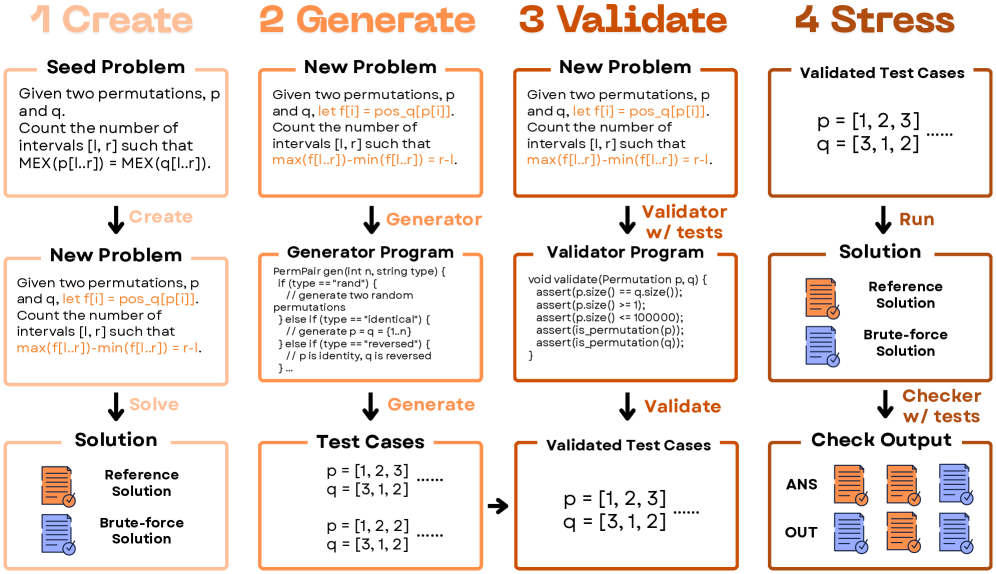
核心思路:论文的核心思路是利用大语言模型(LLMs)的强大生成能力和理解能力,将其作为问题生成器。通过多轮验证和交叉验证机制,确保生成题目的质量和正确性。同时,利用LLMs生成参考解决方案和暴力破解解决方案,进一步验证题目的合理性。
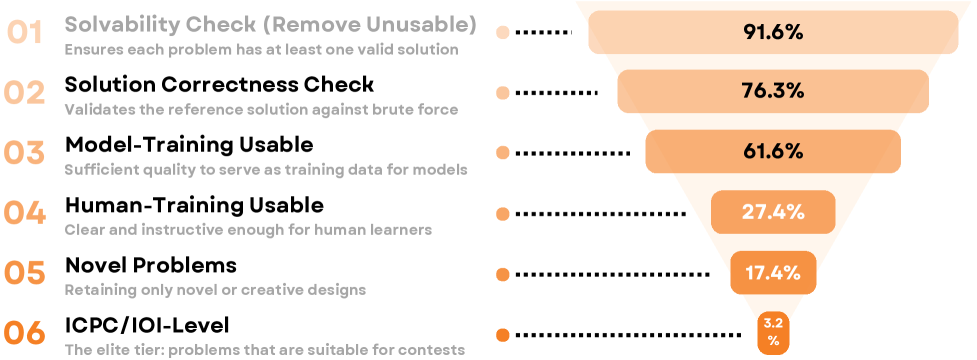
技术框架:AutoCode系统主要包含以下几个阶段:1) 题目生成:利用LLMs生成初始的题目描述;2) 测试用例生成:利用LLMs生成测试用例,包括正常情况和边界情况;3) 解决方案生成:利用LLMs生成参考解决方案和暴力破解解决方案;4) 验证:通过交叉验证测试用例和解决方案,过滤掉不一致的题目;5) 人工验证:由人类专家对生成的题目进行最终验证。
关键创新:AutoCode的关键创新在于将LLMs应用于竞赛编程题目的自动生成,并引入了多轮验证和交叉验证机制,显著提高了生成题目的质量和正确性。与现有方法相比,AutoCode能够生成更复杂、更具挑战性的题目,并能自动生成参考解决方案,降低了人工成本。
关键设计:AutoCode的关键设计包括:1) 使用高质量的编程题目数据集对LLMs进行微调,提高其生成题目的能力;2) 设计多轮验证机制,包括测试用例验证、解决方案验证和人工验证,确保题目的正确性;3) 设计交叉验证机制,通过比较不同解决方案的输出结果,发现潜在的错误;4) 使用合适的prompt engineering技术,引导LLMs生成符合要求的题目描述和测试用例。
🖼️ 关键图片
📊 实验亮点
AutoCode在生成竞赛编程题目方面取得了显著成果。实验结果表明,AutoCode生成的测试套件与官方判定的结果一致性接近99%,相比于HardTests的不到81%,有显著提升。此外,AutoCode成功生成了由Grandmaster级别(前0.3%)的竞赛程序员判断为具有竞赛质量的新题目,证明了其生成高质量题目的能力。
🎯 应用场景
AutoCode可应用于在线评测系统、编程竞赛平台和教育领域,降低题目编写成本,提高题目质量,并能根据需求自动生成各种难度和类型的题目。该研究有助于推动编程教育的普及和发展,并为大语言模型在软件工程领域的应用提供新的思路。
📄 摘要(原文)
Writing competitive programming problems is exacting. Authors must: set constraints, input distributions, and edge cases that rule out shortcuts; target specific algorithms (e.g., max-flow, dynamic programming, data structures); and calibrate complexity beyond the reach of most competitors. We argue that this makes for an ideal test of general large language model capabilities and study whether they can do this reliably. We introduce AutoCode, which uses multiple rounds of validation to yield competition-grade problem statements and test cases. On held-out problems, AutoCode test suites approach 99% consistency with official judgments, a significant improvement over current state-of-the-art methods like HardTests, which achieve less than 81%. Furthermore, starting with a random seed problem, AutoCode can create novel variants with reference and brute-force solutions. By cross-verifying these generated solutions against test cases, we can further filter out malformed problems. Our system ensures high correctness, as verified by human experts. AutoCode successfully produces novel problems judged by Grandmaster-level (top 0.3%) competitive programmers to be of contest quality.