Radiology's Last Exam (RadLE): Benchmarking Frontier Multimodal AI Against Human Experts and a Taxonomy of Visual Reasoning Errors in Radiology
作者: Suvrankar Datta, Divya Buchireddygari, Lakshmi Vennela Chowdary Kaza, Mrudula Bhalke, Kautik Singh, Ayush Pandey, Sonit Sai Vasipalli, Upasana Karnwal, Hakikat Bir Singh Bhatti, Bhavya Ratan Maroo, Sanjana Hebbar, Rahul Joseph, Gurkawal Kaur, Devyani Singh, Akhil V, Dheeksha Devasya Shama Prasad, Nishtha Mahajan, Ayinaparthi Arisha, Rajesh Vanagundi, Reet Nandy, Kartik Vuthoo, Snigdhaa Rajvanshi, Nikhileswar Kondaveeti, Suyash Gunjal, Rishabh Jain, Rajat Jain, Anurag Agrawal
分类: cs.AI, cs.LG
发布日期: 2025-09-29
备注: 29 pages, 7 figures, 7 tables, includes Annexure (1). Part of the work accepted at RSNA 2025 (Cutting Edge Oral Presentation)
💡 一句话要点
RadLE:放射学诊断基准测试,评估多模态AI与专家医生的差距及视觉推理错误
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 放射学 多模态AI 基准测试 视觉推理 医学影像 诊断准确率 大型语言模型
📋 核心要点
- 现有医学影像AI评估多集中于常见病理,缺乏对前沿模型在复杂诊断案例上的严格评估。
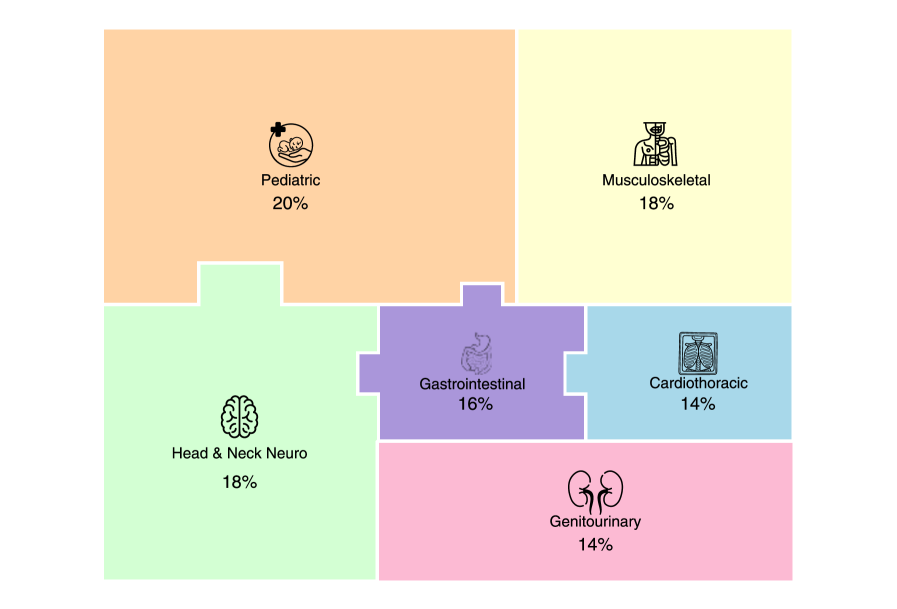
- 构建RadLE基准,包含专家级“即时诊断”案例,通过原生Web界面评估多种前沿AI模型的诊断能力。
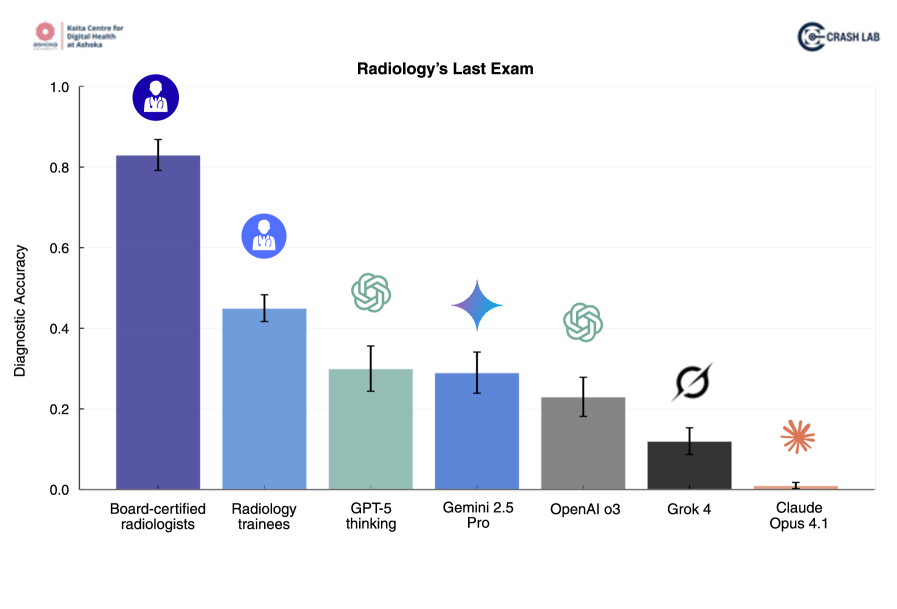
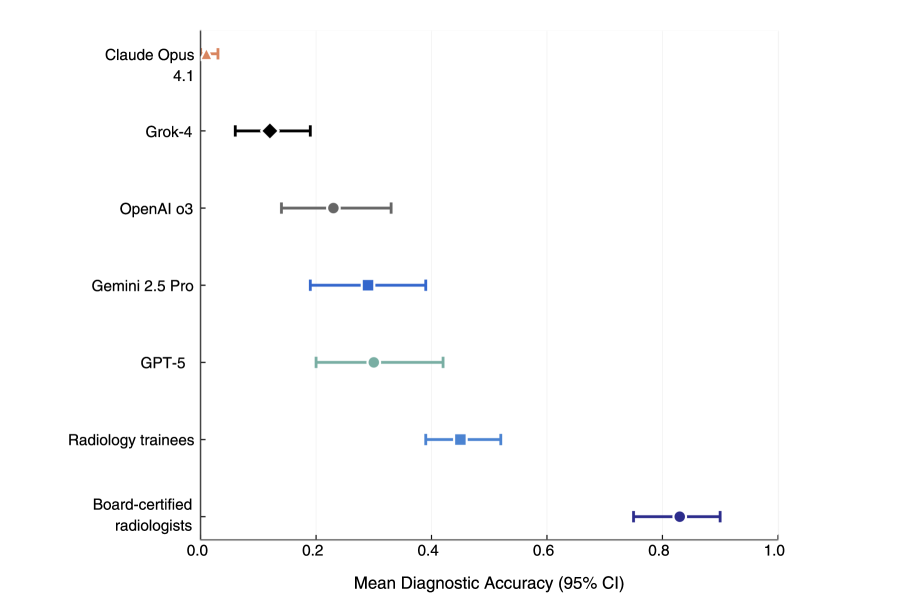
- 实验表明,前沿AI模型在复杂诊断案例中表现远低于放射科医生,突显了通用AI在医学影像领域的局限性。
📝 摘要(中文)
本研究开发了一个包含50个专家级“即时诊断”案例的放射学基准测试(RadLE),涵盖多种影像模态,旨在评估前沿AI模型与认证放射科医生和放射科住院医师在诊断方面的性能。通过原生Web界面测试了五种流行的前沿AI模型(OpenAI o3、OpenAI GPT-5、Gemini 2.5 Pro、Grok-4和Claude Opus 4.1)的推理能力。由盲法专家对准确性进行评分,并在三次独立运行中评估可重复性。GPT-5还接受了各种推理模式的评估。对推理质量错误进行了评估,并定义了视觉推理错误的分类。结果表明,认证放射科医生的诊断准确率最高(83%),优于住院医师(45%)和所有AI模型(GPT-5表现最佳,为30%)。GPT-5和o3的可靠性较高,Gemini 2.5 Pro和Grok-4的可靠性中等,Claude Opus 4.1的可靠性较差。这些发现表明,先进的前沿模型在具有挑战性的诊断案例中远不及放射科医生。该基准测试突出了通用AI在医学影像方面的局限性,并警告不要在无监督的情况下进行临床使用。此外,还对推理轨迹进行了定性分析,并提出了AI模型视觉推理错误的实用分类,以便更好地理解其失效模式,为评估标准提供信息,并指导更强大的模型开发。
🔬 方法详解
问题定义:论文旨在解决通用多模态AI模型在复杂放射学诊断任务中表现不足的问题。现有方法主要依赖于公共数据集,这些数据集通常包含常见病理,无法充分评估模型在处理罕见或复杂病例时的能力。此外,现有评估方法缺乏对模型推理过程的深入分析,难以了解模型的失效模式。
核心思路:论文的核心思路是构建一个高质量的、具有挑战性的放射学诊断基准测试(RadLE),并使用该基准测试来评估前沿AI模型与人类专家(放射科医生)的性能差距。通过分析模型的推理过程,识别其视觉推理错误,从而为改进模型提供指导。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 构建RadLE基准测试,包含50个专家级“即时诊断”案例,涵盖多种影像模态。2) 选择五种流行的前沿AI模型(OpenAI o3、OpenAI GPT-5、Gemini 2.5 Pro、Grok-4和Claude Opus 4.1),并通过其原生Web界面进行测试。3) 由盲法专家对模型的诊断准确性进行评分,并在三次独立运行中评估可重复性。4) 对模型的推理过程进行定性分析,并定义视觉推理错误的分类。
关键创新:该研究的关键创新在于:1) 构建了一个高质量的、具有挑战性的放射学诊断基准测试(RadLE),该基准测试可以更有效地评估AI模型在复杂诊断任务中的能力。2) 对AI模型的推理过程进行了深入分析,并提出了视觉推理错误的分类,这有助于更好地理解模型的失效模式。
关键设计:在基准测试的设计方面,论文选择了50个专家级的“即时诊断”案例,这些案例涵盖了多种影像模态,并且具有较高的诊断难度。在模型评估方面,论文使用了盲法评分和可重复性评估,以确保评估结果的客观性和可靠性。在推理过程分析方面,论文对模型的推理轨迹进行了定性分析,并定义了视觉推理错误的分类,包括:1) 缺乏对解剖结构的理解;2) 无法识别关键的影像特征;3) 推理过程中的逻辑错误等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,认证放射科医生的诊断准确率最高(83%),优于住院医师(45%)和所有AI模型(GPT-5表现最佳,为30%)。GPT-5和o3的可靠性较高,Gemini 2.5 Pro和Grok-4的可靠性中等,Claude Opus 4.1的可靠性较差。这些结果突显了当前前沿AI模型在复杂放射学诊断任务中与人类专家之间的显著差距。
🎯 应用场景
该研究成果可应用于医学影像AI模型的评估和改进,帮助开发更可靠、更准确的诊断辅助工具。通过深入了解AI模型的失效模式,可以指导模型开发者改进算法,提高模型在复杂诊断任务中的性能。此外,该研究还可以为临床医生提供参考,帮助他们更好地理解AI模型的优势和局限性,从而更有效地利用AI技术辅助诊断。
📄 摘要(原文)
Generalist multimodal AI systems such as large language models (LLMs) and vision language models (VLMs) are increasingly accessed by clinicians and patients alike for medical image interpretation through widely available consumer-facing chatbots. Most evaluations claiming expert level performance are on public datasets containing common pathologies. Rigorous evaluation of frontier models on difficult diagnostic cases remains limited. We developed a pilot benchmark of 50 expert-level "spot diagnosis" cases across multiple imaging modalities to evaluate the performance of frontier AI models against board-certified radiologists and radiology trainees. To mirror real-world usage, the reasoning modes of five popular frontier AI models were tested through their native web interfaces, viz. OpenAI o3, OpenAI GPT-5, Gemini 2.5 Pro, Grok-4, and Claude Opus 4.1. Accuracy was scored by blinded experts, and reproducibility was assessed across three independent runs. GPT-5 was additionally evaluated across various reasoning modes. Reasoning quality errors were assessed and a taxonomy of visual reasoning errors was defined. Board-certified radiologists achieved the highest diagnostic accuracy (83%), outperforming trainees (45%) and all AI models (best performance shown by GPT-5: 30%). Reliability was substantial for GPT-5 and o3, moderate for Gemini 2.5 Pro and Grok-4, and poor for Claude Opus 4.1. These findings demonstrate that advanced frontier models fall far short of radiologists in challenging diagnostic cases. Our benchmark highlights the present limitations of generalist AI in medical imaging and cautions against unsupervised clinical use. We also provide a qualitative analysis of reasoning traces and propose a practical taxonomy of visual reasoning errors by AI models for better understanding their failure modes, informing evaluation standards and guiding more robust model development.