RL in the Wild: Characterizing RLVR Training in LLM Deployment
作者: Jiecheng Zhou, Qinghao Hu, Yuyang Jin, Zerui Wang, Peng Sun, Yuzhe Gu, Wenwei Zhang, Mingshu Zhai, Xingcheng Zhang, Weiming Zhang
分类: cs.AI, cs.DC, cs.LG
发布日期: 2025-09-29 (更新: 2025-10-13)
备注: 20 pages, 28 figures
💡 一句话要点
针对LLM部署中RLVR训练的系统挑战,提出PolyTrace基准测试套件。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 系统优化 基准测试 RLVR 性能分析 工作负载特征
📋 核心要点
- 现有RLVR在LLM部署中面临数据流复杂、任务多样等挑战,缺乏系统层面的理解和优化。
- 论文通过对RLVR任务的特征分析,揭示了GPU空闲、并行策略低效、数据管理不足等问题。
- 提出了PolyTrace基准测试套件,用于评估真实工作负载下的RLVR系统性能,并验证了其高准确性。
📝 摘要(中文)
大型语言模型(LLM)现已广泛应用于各个领域。随着LLM的快速发展,基于可验证奖励的强化学习(RLVR)在近几个月内迅速兴起,以增强LLM的推理和理解能力。然而,其复杂的数据流和多样化的任务给RL训练系统带来了巨大的挑战,并且从系统角度对RLVR的理解仍然有限。为了深入了解RLVR引入的系统挑战,我们对LLM部署中的RLVR任务进行了特征分析研究。具体而言,我们研究了不同训练步骤中不同RL任务的工作负载分布和变化趋势。我们发现了诸如由倾斜的序列长度分布导致的GPU空闲、动态变化的工作负载中低效的并行策略、低效的数据管理机制以及负载不平衡等问题。我们描述了我们的观察结果,并呼吁进一步研究剩余的开放挑战。此外,我们提出了PolyTrace基准测试套件,以使用真实的工作负载进行评估,并且一个实际用例验证了PolyTrace基准测试套件表现出94.7%的准确率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)部署中,基于可验证奖励的强化学习(RLVR)训练所面临的系统挑战。现有方法缺乏对RLVR任务的系统性理解,导致GPU资源利用率低、并行策略效率低下、数据管理不善以及负载不均衡等问题,严重影响了训练效率和模型性能。
核心思路:论文的核心思路是通过对实际LLM部署中的RLVR任务进行深入的特征分析,识别出影响系统性能的关键瓶颈。然后,基于这些分析结果,设计一个能够模拟真实工作负载的基准测试套件(PolyTrace),以便更准确地评估和优化RLVR训练系统。
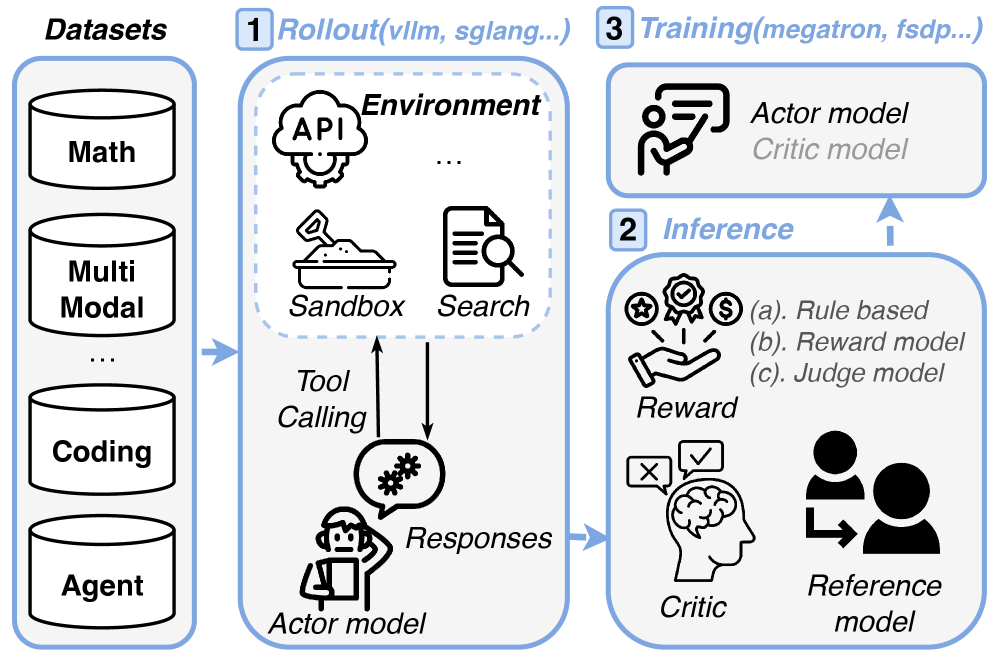
技术框架:论文的技术框架主要包括两个部分:一是RLVR任务的特征分析,二是PolyTrace基准测试套件的构建。特征分析涉及对不同RL任务在不同训练步骤中的工作负载分布和变化趋势进行研究,识别出GPU空闲、并行策略低效、数据管理不足等问题。PolyTrace基准测试套件则旨在模拟真实RLVR任务的工作负载,用于评估不同系统配置和优化策略的性能。
关键创新:论文的关键创新在于提出了PolyTrace基准测试套件,该套件能够模拟真实RLVR任务的工作负载,从而更准确地评估和优化RLVR训练系统。与传统的基准测试方法相比,PolyTrace能够更好地反映实际应用场景中的系统性能,为RLVR训练系统的优化提供更可靠的依据。
关键设计:PolyTrace基准测试套件的关键设计在于其能够模拟真实RLVR任务的工作负载。具体来说,它需要考虑不同RL任务的特点、不同训练步骤的工作负载分布以及数据管理机制等因素。论文中提到,一个实际用例验证了PolyTrace基准测试套件表现出94.7%的准确率,表明其能够有效地模拟真实工作负载。
🖼️ 关键图片


📊 实验亮点
论文提出了PolyTrace基准测试套件,并通过实际用例验证了其94.7%的准确率。该套件能够模拟真实RLVR任务的工作负载,为评估和优化LLM部署中的RLVR训练系统提供了有效工具。
🎯 应用场景
该研究成果可应用于大型语言模型的训练和部署优化,提升RLVR训练效率,降低计算资源消耗。通过PolyTrace基准测试套件,可以更准确地评估和优化RLVR训练系统,加速LLM在各个领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) are now widely used across many domains. With their rapid development, Reinforcement Learning with Verifiable Rewards (RLVR) has surged in recent months to enhance their reasoning and understanding abilities. However, its complex data flows and diverse tasks pose substantial challenges to RL training systems, and there is limited understanding of RLVR from a system perspective. To thoroughly understand the system challenges introduced by RLVR, we present a characterization study of RLVR tasks in our LLM deployment. Specifically, we investigate the distribution and variation trends of workloads across different RL tasks across training steps. We identify issues such as GPU idling caused by skewed sequence length distribution, inefficient parallel strategies in dynamically varying workloads, inefficient data management mechanisms, and load imbalance. We describe our observations and call for further investigation into the remaining open challenges. Furthermore, we propose PolyTrace benchmark suite to conduct evaluation with realistic workloads, and a practical use case validates that PolyTrace benchmark suite exhibits 94.7% accuracy.