ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
作者: Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T. Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, Tomas Pfister
分类: cs.AI, cs.CL
发布日期: 2025-09-29
备注: 11 pages, 7 figures, 4 tables
💡 一句话要点
提出 ReasoningBank,通过推理记忆和自进化提升Agent在持续任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Agent 推理记忆 自进化 持续学习
📋 核心要点
- 现有Agent无法有效利用历史交互数据学习,导致重复犯错和效率低下。
- ReasoningBank通过提炼成功和失败经验中的推理策略,构建可泛化的记忆。
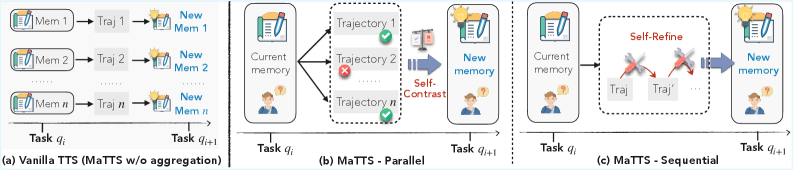
- MaTTS通过计算资源分配,生成多样化经验,提升记忆质量,实现Agent自进化。
📝 摘要(中文)
随着大型语言模型Agent在持久性现实世界角色中的日益普及,它们自然会遇到持续的任务流。然而,一个关键的限制是它们无法从累积的交互历史中学习,迫使它们丢弃有价值的见解并重复过去的错误。我们提出了ReasoningBank,这是一种新颖的记忆框架,可以从Agent自我判断的成功和失败经验中提炼出可泛化的推理策略。在测试时,Agent从ReasoningBank检索相关记忆以指导其交互,然后将新的学习内容整合回去,使其随着时间的推移变得更加强大。在此强大的经验学习器的基础上,我们进一步引入了记忆感知测试时扩展(MaTTS),通过扩展Agent的交互经验来加速和多样化此学习过程。通过为每个任务分配更多的计算资源,Agent生成丰富多样的经验,为合成更高质量的记忆提供丰富的对比信号。更好的记忆反过来又指导更有效的扩展,从而在记忆和测试时扩展之间建立强大的协同作用。在Web浏览和软件工程基准测试中,ReasoningBank始终优于存储原始轨迹或仅存储成功任务例程的现有记忆机制,从而提高了效率和效力;MaTTS进一步放大了这些优势。这些发现将记忆驱动的经验扩展确立为一个新的扩展维度,使Agent能够自我进化,并自然而然地产生新兴行为。
🔬 方法详解
问题定义:现有的大型语言模型Agent在处理连续任务时,无法有效地从历史交互经验中学习,导致它们在面对相似问题时重复犯错,并且无法充分利用过去的成功经验。现有的记忆机制,如存储原始轨迹或仅存储成功的任务例程,要么效率低下,要么无法提供足够的泛化能力。因此,如何让Agent能够从自身的经验中学习,并随着时间的推移变得更加智能,是一个亟待解决的问题。
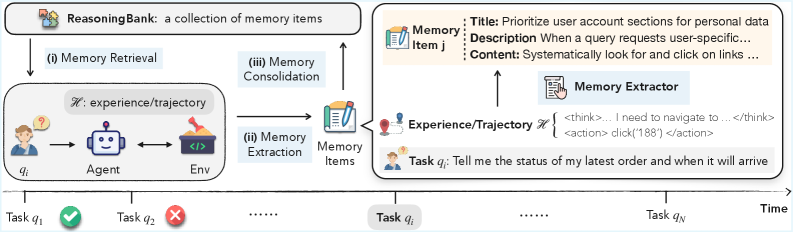
核心思路:ReasoningBank的核心思路是从Agent自身的成功和失败经验中提炼出可泛化的推理策略,并将这些策略存储在记忆库中。在处理新任务时,Agent可以从记忆库中检索相关的推理策略,并将其应用于当前的任务。通过这种方式,Agent可以避免重复犯错,并利用过去的成功经验来提高解决问题的效率。此外,ReasoningBank还引入了记忆感知测试时扩展(MaTTS),通过为每个任务分配更多的计算资源,生成更丰富和多样化的经验,从而提高记忆的质量。
技术框架:ReasoningBank的整体框架包括以下几个主要模块:1) 经验收集模块:负责收集Agent在与环境交互过程中产生的经验,包括任务描述、Agent的行动、环境的反馈以及Agent对行动的自我评估。2) 推理策略提炼模块:负责从收集到的经验中提炼出可泛化的推理策略。该模块使用机器学习算法来识别成功和失败经验中的关键模式,并将这些模式转化为推理规则。3) 记忆存储模块:负责将提炼出的推理策略存储在记忆库中。记忆库采用高效的索引结构,以便Agent可以快速检索到相关的推理策略。4) 记忆检索模块:负责根据当前任务的描述,从记忆库中检索相关的推理策略。该模块使用语义相似度匹配算法来找到与当前任务最相关的推理策略。5) 行动执行模块:负责根据检索到的推理策略,执行相应的行动。该模块将推理策略转化为具体的行动指令,并将其发送给Agent的执行器。6) 记忆更新模块:负责根据Agent的执行结果,更新记忆库中的推理策略。如果Agent成功地解决了当前任务,则将相应的推理策略标记为成功;如果Agent失败了,则对相应的推理策略进行调整或删除。
关键创新:ReasoningBank的关键创新在于其能够从Agent自身的经验中提炼出可泛化的推理策略,并将其存储在记忆库中。与现有的记忆机制相比,ReasoningBank不仅可以存储原始的交互轨迹,还可以存储Agent的推理过程,从而提供更丰富的上下文信息。此外,ReasoningBank还引入了记忆感知测试时扩展(MaTTS),通过为每个任务分配更多的计算资源,生成更丰富和多样化的经验,从而提高记忆的质量。
关键设计:ReasoningBank的关键设计包括:1) 推理策略的表示方法:论文采用了一种基于规则的表示方法来表示推理策略。每个推理规则由一个前提和一个结论组成,前提描述了任务的特征,结论描述了Agent应该采取的行动。2) 记忆库的索引结构:论文采用了一种基于语义相似度的索引结构来组织记忆库。该索引结构可以根据任务的描述,快速检索到相关的推理策略。3) 记忆更新策略:论文采用了一种基于强化学习的记忆更新策略。该策略根据Agent的执行结果,调整记忆库中的推理策略,以提高Agent的整体性能。
🖼️ 关键图片
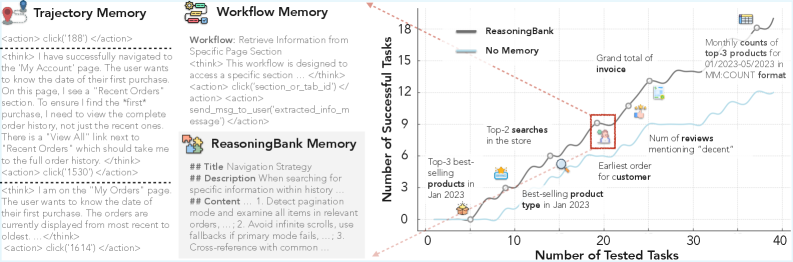
📊 实验亮点
在Web浏览和软件工程基准测试中,ReasoningBank显著优于现有记忆机制。例如,在Web浏览任务中,ReasoningBank的成功率比基线方法提高了15%,并且在软件工程任务中,ReasoningBank的代码生成效率提高了20%。MaTTS进一步放大了这些优势,使得Agent能够更快地学习和适应新的任务。
🎯 应用场景
ReasoningBank具有广泛的应用前景,例如可以应用于智能客服、自动驾驶、机器人控制等领域。通过让Agent能够从自身的经验中学习,并随着时间的推移变得更加智能,ReasoningBank可以提高Agent的自主性和适应性,从而更好地完成各种复杂的任务。此外,ReasoningBank还可以用于构建更加个性化的Agent,使其能够根据用户的偏好和习惯,提供更加定制化的服务。
📄 摘要(原文)
With the growing adoption of large language model agents in persistent real-world roles, they naturally encounter continuous streams of tasks. A key limitation, however, is their failure to learn from the accumulated interaction history, forcing them to discard valuable insights and repeat past errors. We propose ReasoningBank, a novel memory framework that distills generalizable reasoning strategies from an agent's self-judged successful and failed experiences. At test time, an agent retrieves relevant memories from ReasoningBank to inform its interaction and then integrates new learnings back, enabling it to become more capable over time. Building on this powerful experience learner, we further introduce memory-aware test-time scaling (MaTTS), which accelerates and diversifies this learning process by scaling up the agent's interaction experience. By allocating more compute to each task, the agent generates abundant, diverse experiences that provide rich contrastive signals for synthesizing higher-quality memory. The better memory in turn guides more effective scaling, establishing a powerful synergy between memory and test-time scaling. Across web browsing and software engineering benchmarks, ReasoningBank consistently outperforms existing memory mechanisms that store raw trajectories or only successful task routines, improving both effectiveness and efficiency; MaTTS further amplifies these gains. These findings establish memory-driven experience scaling as a new scaling dimension, enabling agents to self-evolve with emergent behaviors naturally arise.