Vision-and-Language Navigation with Analogical Textual Descriptions in LLMs
作者: Yue Zhang, Tianyi Ma, Zun Wang, Yanyuan Qiao, Parisa Kordjamshidi
分类: cs.AI, cs.CV, cs.MM
发布日期: 2025-09-29
💡 一句话要点
提出基于LLM和类比文本描述的视觉-语言导航方法,提升场景理解和空间推理能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 大型语言模型 类比推理 场景理解 空间推理
📋 核心要点
- 现有基于LLM的VLN Agent在处理视觉信息时存在局限,要么损失细节,要么缺乏高层语义理解。
- 该方法通过引入多视角的文本描述,利用LLM进行类比推理,从而提升Agent的场景理解能力。
- 在R2R数据集上的实验表明,该方法显著提升了导航性能,验证了类比推理的有效性。
📝 摘要(中文)
本文提出了一种改进的基于大型语言模型(LLM)的视觉-语言导航(VLN)Agent,旨在提升其上下文理解能力。现有基于LLM的VLN Agent要么将图像编码为文本场景描述,可能过度简化视觉细节,要么直接处理原始图像输入,无法捕捉高层次推理所需的抽象语义。本文通过整合来自多个视角的文本描述,促进图像间的类比推理,从而增强导航Agent的上下文理解。通过利用基于文本的类比推理,Agent能够提升其全局场景理解和空间推理能力,从而做出更准确的动作决策。在R2R数据集上的实验结果表明,该方法在导航性能方面取得了显著提升。
🔬 方法详解
问题定义:视觉-语言导航(VLN)任务旨在让Agent根据自然语言指令在真实环境中导航。现有方法要么直接使用原始图像,忽略了高层语义信息;要么将图像转换为文本描述,损失了视觉细节。这两种方式都限制了Agent对环境的理解和推理能力,尤其是在复杂场景中。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大推理能力,结合多视角的文本描述,促进图像之间的类比推理。通过类比推理,Agent可以更好地理解场景之间的关系,从而做出更准确的导航决策。这种方法旨在弥补现有方法在视觉信息处理方面的不足,提升Agent的全局场景理解和空间推理能力。
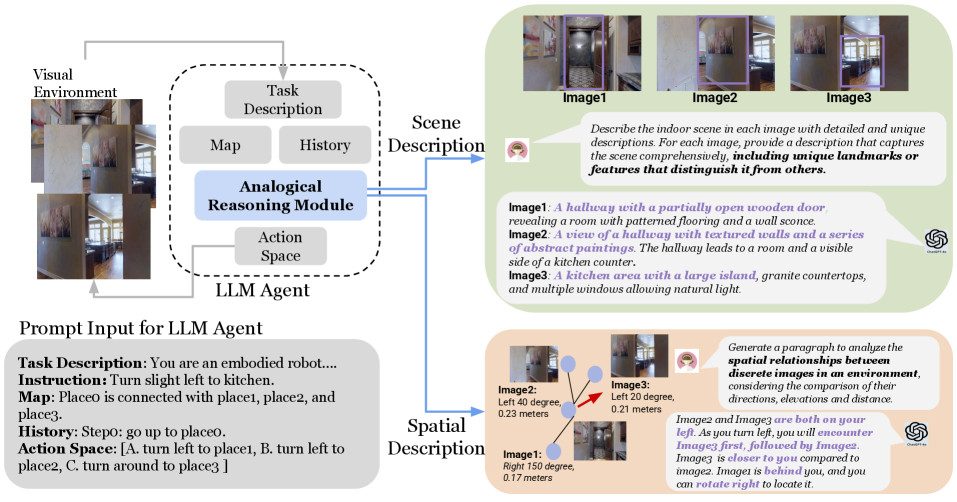
技术框架:整体框架包含以下几个主要模块:1) 图像特征提取模块:用于提取图像的视觉特征。2) 文本描述生成模块:从多个视角生成场景的文本描述。3) 类比推理模块:利用LLM对不同视角的文本描述进行类比推理,提取场景之间的关系。4) 决策模块:根据类比推理的结果和导航指令,做出下一步的动作决策。整个流程是,首先输入图像和导航指令,然后提取图像特征并生成文本描述,接着进行类比推理,最后做出动作决策。
关键创新:最重要的创新点在于引入了基于文本的类比推理机制。与直接使用图像特征或文本描述不同,该方法通过类比推理,挖掘场景之间的深层关系,从而提升Agent的场景理解能力。这种方法能够更好地利用LLM的推理能力,克服了现有方法在视觉信息处理方面的局限性。
关键设计:论文中可能涉及的关键设计包括:1) 如何选择合适的文本描述视角,以最大程度地促进类比推理。2) 如何设计类比推理的prompt,以引导LLM进行有效的推理。3) 如何将类比推理的结果融入到决策模块中,以指导Agent的导航行为。具体的参数设置、损失函数和网络结构等细节,需要参考论文原文。
🖼️ 关键图片


📊 实验亮点
该论文在R2R数据集上进行了实验,结果表明,提出的方法显著提升了导航性能。具体的性能数据和提升幅度需要在论文原文中查找。通过与其他基线方法进行对比,验证了基于类比推理的VLN Agent的有效性。实验结果表明,该方法能够更好地理解场景之间的关系,从而做出更准确的导航决策。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。通过提升Agent的场景理解和推理能力,可以使其在复杂环境中更有效地完成导航任务。例如,在智能家居中,机器人可以根据用户的语音指令,准确地到达指定位置。在自动驾驶领域,车辆可以更好地理解交通场景,做出更安全的驾驶决策。此外,该方法还可以应用于虚拟现实游戏中,提升游戏角色的智能性和交互性。
📄 摘要(原文)
Integrating large language models (LLMs) into embodied AI models is becoming increasingly prevalent. However, existing zero-shot LLM-based Vision-and-Language Navigation (VLN) agents either encode images as textual scene descriptions, potentially oversimplifying visual details, or process raw image inputs, which can fail to capture abstract semantics required for high-level reasoning. In this paper, we improve the navigation agent's contextual understanding by incorporating textual descriptions from multiple perspectives that facilitate analogical reasoning across images. By leveraging text-based analogical reasoning, the agent enhances its global scene understanding and spatial reasoning, leading to more accurate action decisions. We evaluate our approach on the R2R dataset, where our experiments demonstrate significant improvements in navigation performance.