The Era of Real-World Human Interaction: RL from User Conversations
作者: Chuanyang Jin, Jing Xu, Bo Liu, Leitian Tao, Olga Golovneva, Tianmin Shu, Wenting Zhao, Xian Li, Jason Weston
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-09-29
💡 一句话要点
提出基于用户对话的强化学习(RLHI),实现持续模型改进和多方面对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机交互 强化学习 对话系统 个性化 用户建模
📋 核心要点
- 现有对话模型依赖专家标注数据对齐,成本高且难以持续改进。
- 提出RLHI框架,直接从真实用户对话中学习,实现个性化和指令遵循。
- 实验表明,RLHI在个性化和指令遵循方面优于基线,并提升了推理能力。
📝 摘要(中文)
为了实现持续的模型改进和多方面的对齐,未来的模型必须从自然的人机交互中学习。目前,对话模型主要依赖于预先标注的、专家生成的人工反馈进行对齐。本文提出了一种从人机交互中进行强化学习(RLHI)的范式,该范式直接从真实的、用户间的对话中学习。我们开发了两种互补的方法:(1)基于用户引导重写的RLHI,它根据用户自然语言的后续回复来修改不令人满意的模型输出;(2)基于用户奖励的RLHI,它通过一个奖励模型进行学习,该模型以用户的长期交互历史(称为角色Persona)为条件。这些方法共同通过角色条件偏好优化将长期用户角色与turn级别的偏好联系起来。在WildChat对话数据集上训练的RLHI变体在个性化和指令遵循方面优于强大的基线模型,并且类似的反馈也提高了在推理基准测试中的性能。这些结果表明,有机的人机交互为个性化对齐提供了可扩展的、有效的监督。
🔬 方法详解
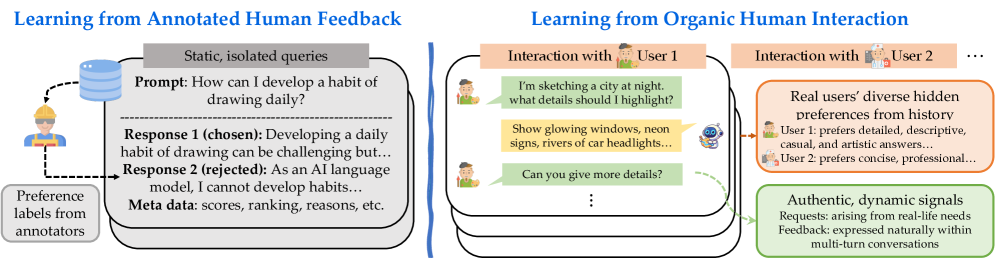
问题定义:现有对话模型依赖于预先标注的、专家生成的人工反馈进行对齐,这种方式成本高昂,难以扩展到大规模真实用户交互场景,并且难以捕捉用户个性化的偏好和长期交互历史。因此,如何利用真实用户对话数据,实现对话模型的持续改进和个性化对齐是一个关键问题。
核心思路:本文的核心思路是直接从真实的用户对话中学习,通过用户在对话中的自然反馈(例如后续回复)来指导模型的改进。具体来说,论文提出了两种互补的方法:一种是利用用户的自然语言回复来重写不令人满意的模型输出,另一种是利用用户的长期交互历史(角色Persona)来构建奖励模型,从而将长期用户角色与turn级别的偏好联系起来。
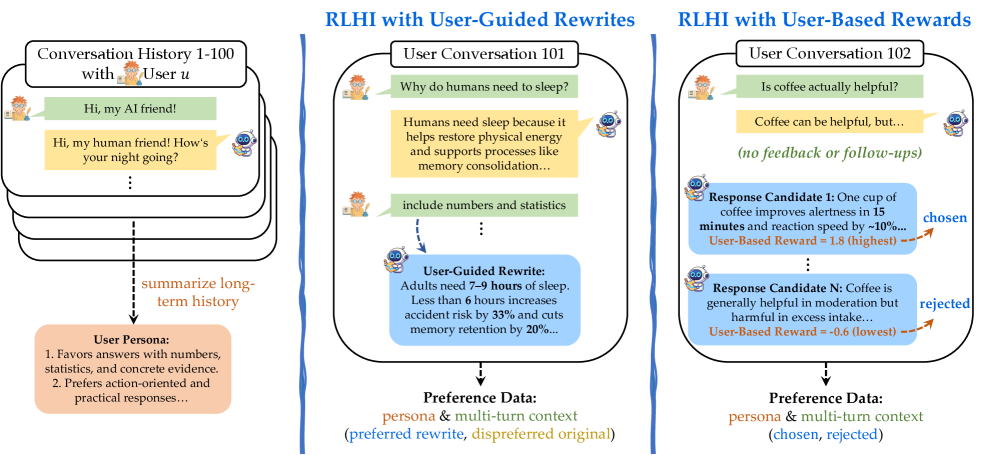
技术框架:RLHI框架包含两个主要变体:(1) RLHI with User-Guided Rewrites:模型生成回复后,如果用户不满意,会给出后续回复,该回复被用于指导模型重写原始回复。(2) RLHI with User-Based Rewards:利用用户的长期交互历史(Persona)训练一个奖励模型,该模型用于评估模型生成的回复的质量,并作为强化学习的奖励信号。整体流程是,模型与用户进行对话,根据用户反馈或奖励模型的评估结果,利用强化学习算法更新模型参数。
关键创新:RLHI框架的关键创新在于它直接从真实的用户对话中学习,避免了对大量人工标注数据的依赖。此外,通过引入用户角色Persona,RLHI能够更好地捕捉用户的个性化偏好和长期交互历史,从而实现更个性化的对话体验。与现有方法相比,RLHI更具可扩展性和适应性,能够更好地适应真实世界中的复杂对话场景。
关键设计:在RLHI with User-Guided Rewrites中,关键在于如何有效地利用用户的后续回复来指导模型重写。一种可能的实现方式是使用序列到序列模型,将原始回复和用户回复作为输入,生成修正后的回复。在RLHI with User-Based Rewards中,关键在于如何构建一个有效的奖励模型。该奖励模型可以是一个神经网络,输入是当前对话轮次的上下文和模型生成的回复,以及用户的角色Persona,输出是一个奖励值,表示回复的质量。奖励模型的训练可以使用对比学习或排序学习等方法。
🖼️ 关键图片
📊 实验亮点
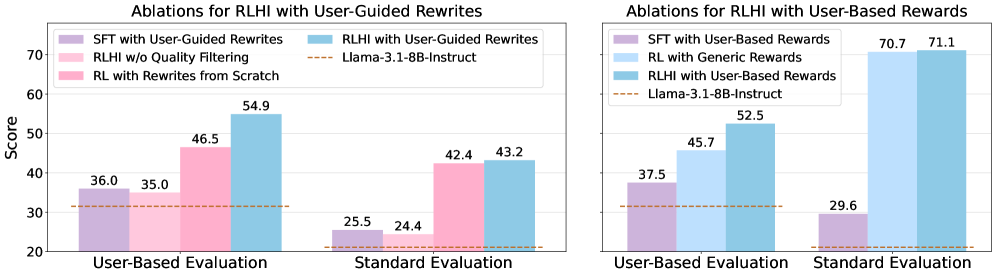
实验结果表明,在WildChat数据集上训练的RLHI变体在个性化和指令遵循方面优于强大的基线模型。此外,类似的反馈机制也提高了模型在推理基准测试中的性能。这些结果表明,有机的人机交互为个性化对齐提供了可扩展的、有效的监督。
🎯 应用场景
该研究成果可应用于各种对话系统,例如聊天机器人、智能客服、虚拟助手等。通过从真实用户交互中学习,这些系统可以更好地理解用户意图,提供更个性化、更符合用户需求的回复,从而提升用户体验。此外,该方法还可以用于改进模型的推理能力和指令遵循能力,使其能够更好地完成复杂任务。
📄 摘要(原文)
We posit that to achieve continual model improvement and multifaceted alignment, future models must learn from natural human interaction. Current conversational models are aligned using pre-annotated, expert-generated human feedback. In this work, we introduce Reinforcement Learning from Human Interaction (RLHI), a paradigm that learns directly from in-the-wild user conversations. We develop two complementary methods: (1) RLHI with User-Guided Rewrites, which revises unsatisfactory model outputs based on users' natural-language follow-up responses, (2) RLHI with User-Based Rewards, which learns via a reward model conditioned on knowledge of the user's long-term interaction history (termed persona). Together, these methods link long-term user personas to turn-level preferences via persona-conditioned preference optimization. Trained on conversations derived from WildChat, both RLHI variants outperform strong baselines in personalization and instruction-following, and similar feedback enhances performance on reasoning benchmarks. These results suggest organic human interaction offers scalable, effective supervision for personalized alignment.