Pushing LLMs to Their Logical Reasoning Bound: The Role of Data Reasoning Intensity
作者: Zhen Bi, Zhenlin Hu, Jinnan Yang, Mingyang Chen, Cheng Deng, Yida Xue, Zeyu Yang, Qing Shen, Zhenfang Liu, Kang Zhao, Ningyu Zhang, Jungang Lou
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-09-29 (更新: 2025-10-04)
💡 一句话要点
提出数据推理强度(DRI)指标,优化训练数据以提升LLM逻辑推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 逻辑推理 数据优化 数据推理强度 训练数据 认知能力 强化学习
📋 核心要点
- 现有方法侧重于数据格式转换,忽略了训练样本内部的推理复杂性,导致LLM的推理潜力未被充分利用。
- 论文提出数据推理强度(DRI)指标,量化样本的逻辑推理复杂性,并基于此优化训练数据。
- 实验表明,该方法显著提高了LLM的性能和泛化能力,优于传统的数据中心策略。
📝 摘要(中文)
大型语言模型(LLM)的最新进展表明,训练数据的结构和质量对塑造推理行为至关重要。然而,现有方法大多侧重于转换数据格式,而忽略了训练样本内部的推理复杂性,导致数据的推理潜力未被充分挖掘和利用。本文认为,LLM的逻辑推理性能受到训练数据的潜力和模型的认知能力的共同约束。为了使这种关系可衡量,我们引入了数据推理强度(DRI),这是一种通过分解和聚合样本的逻辑结构来量化其潜在逻辑推理复杂性的新指标。这使我们能够分析当前LLM对逻辑推理信号的利用程度,并识别相对于数据潜力的性能差距。基于此,我们提出了一种重认知优化策略,系统地增强训练数据的逻辑推理强度。我们的方法不是增加数据量,而是重新优化现有样本,以更好地与LLM的逻辑推理边界对齐。大量实验表明,我们的方法在数据中心策略上显著提高了性能和泛化能力。我们进一步在强化学习框架下验证了我们的方法。结果表明,在数据中优先考虑推理复杂性,而不是单纯的规模或表面形式,对于充分发挥LLM的认知潜力至关重要。
🔬 方法详解
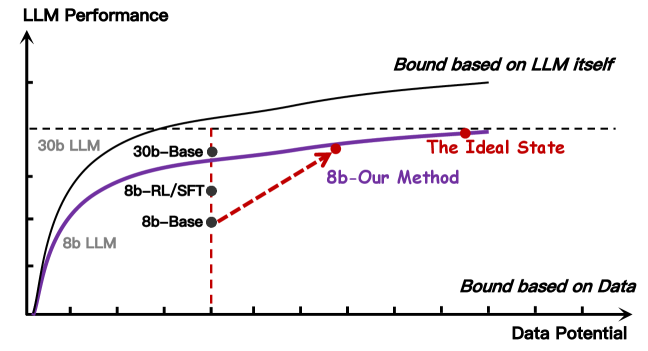
问题定义:现有方法在提升LLM逻辑推理能力时,主要关注数据格式的转换,而忽略了训练数据本身所蕴含的逻辑推理复杂性。这种忽略导致LLM的推理能力受到数据质量的限制,无法充分发挥其潜力。因此,需要一种方法来量化和优化训练数据的逻辑推理强度,从而提升LLM的逻辑推理性能。
核心思路:论文的核心思路是引入“数据推理强度”(Data Reasoning Intensity, DRI)这一概念,用于量化训练样本中蕴含的逻辑推理复杂程度。通过分析DRI,可以了解LLM对不同推理复杂度的样本的学习情况,并针对性地优化训练数据,使之更好地与LLM的推理能力相匹配。这种方法不是简单地增加数据量,而是提升数据的质量,从而更有效地提升LLM的推理能力。
技术框架:该方法主要包含以下几个阶段:1. DRI计算:使用特定的算法分解训练样本的逻辑结构,并计算其DRI值。DRI值越高,表示样本的逻辑推理复杂度越高。2. 性能分析:分析LLM在不同DRI值的样本上的表现,找出LLM的推理瓶颈。3. 数据优化:根据性能分析的结果,对训练数据进行优化,例如,增加高DRI值的样本,或者调整现有样本的逻辑结构,使其DRI值更高。4. 模型训练:使用优化后的训练数据训练LLM。5. 评估:评估训练后的LLM的逻辑推理性能。
关键创新:该论文的关键创新在于提出了DRI这一概念,并将其应用于训练数据的优化。与以往侧重于数据格式转换的方法不同,该方法直接关注数据的逻辑推理复杂性,从而更有效地提升LLM的推理能力。此外,该方法还提出了一种“重认知优化策略”,通过分析LLM在不同DRI值的样本上的表现,有针对性地优化训练数据,从而更好地与LLM的推理能力相匹配。
关键设计:DRI的计算方法是关键设计之一,具体算法未知,但应包含对逻辑结构的分解和聚合。数据优化策略也至关重要,可能涉及对现有样本的逻辑结构进行调整,或者生成新的高DRI值的样本。损失函数的设计也可能需要考虑DRI值,例如,对高DRI值的样本赋予更高的权重。具体的参数设置和网络结构未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在逻辑推理任务上取得了显著的性能提升。与传统的数据中心策略相比,该方法能够更好地利用训练数据的潜力,提升LLM的泛化能力。具体性能数据未知,但论文强调了该方法在性能和泛化能力上的显著优势。
🎯 应用场景
该研究成果可应用于各种需要逻辑推理能力的LLM应用场景,例如问答系统、知识图谱推理、代码生成等。通过优化训练数据,可以提升LLM在这些场景下的性能和可靠性,使其能够更好地理解和解决复杂问题。未来,该方法还可以扩展到其他类型的推理任务,例如常识推理和数学推理。
📄 摘要(原文)
Recent advances in large language models (LLMs) highlight the importance of training data structure and quality in shaping reasoning behavior. However, most existing approaches focus on transforming data formats while neglecting the internal reasoning complexity of training samples, leaving the reasoning potential of data under-explored and underutilized. In this work, we posit that LLM logical reasoning performance is jointly constrained by the potential of the training data and the cognitive capacity of the model. To make this relationship measurable, we introduce Data Reasoning Intensity (DRI), a novel metric that quantifies the latent logical reasoning complexity of samples by decomposing and aggregating their logical structures. This allows us to analyze how well current LLMs utilize logical reasoning signals and identify performance gaps relative to data potential. Based on this insight, we introduce a re-cognizing optimization strategy that systematically enhances the logical reasoning intensity of training data. Rather than increasing data volume, our method re-optimizes existing samples to better align with the LLM's logical reasoning boundary. Extensive experiments show that our approach significantly improves performance and generalization over data-centric strategies. We further validate our method under a reinforcement learning framework. Our results indicate that prioritizing reasoning complexity in data rather than sheer scale or superficial form is essential to realizing LLMs' full cognitive potential.