Towards Safe Reasoning in Large Reasoning Models via Corrective Intervention
作者: Yichi Zhang, Yue Ding, Jingwen Yang, Tianwei Luo, Dongbai Li, Ranjie Duan, Qiang Liu, Hang Su, Yinpeng Dong, Jun Zhu
分类: cs.AI, cs.CL
发布日期: 2025-09-29
💡 一句话要点
提出Intervened Preference Optimization以提升大型推理模型安全性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型推理模型 安全性 思维链 过程监督 偏好优化
📋 核心要点
- 现有大型推理模型虽然回复看似安全,但其推理过程可能包含有害内容,存在安全隐患。
- 论文提出Intervened Preference Optimization (IPO)方法,通过干预手段强化安全推理过程。
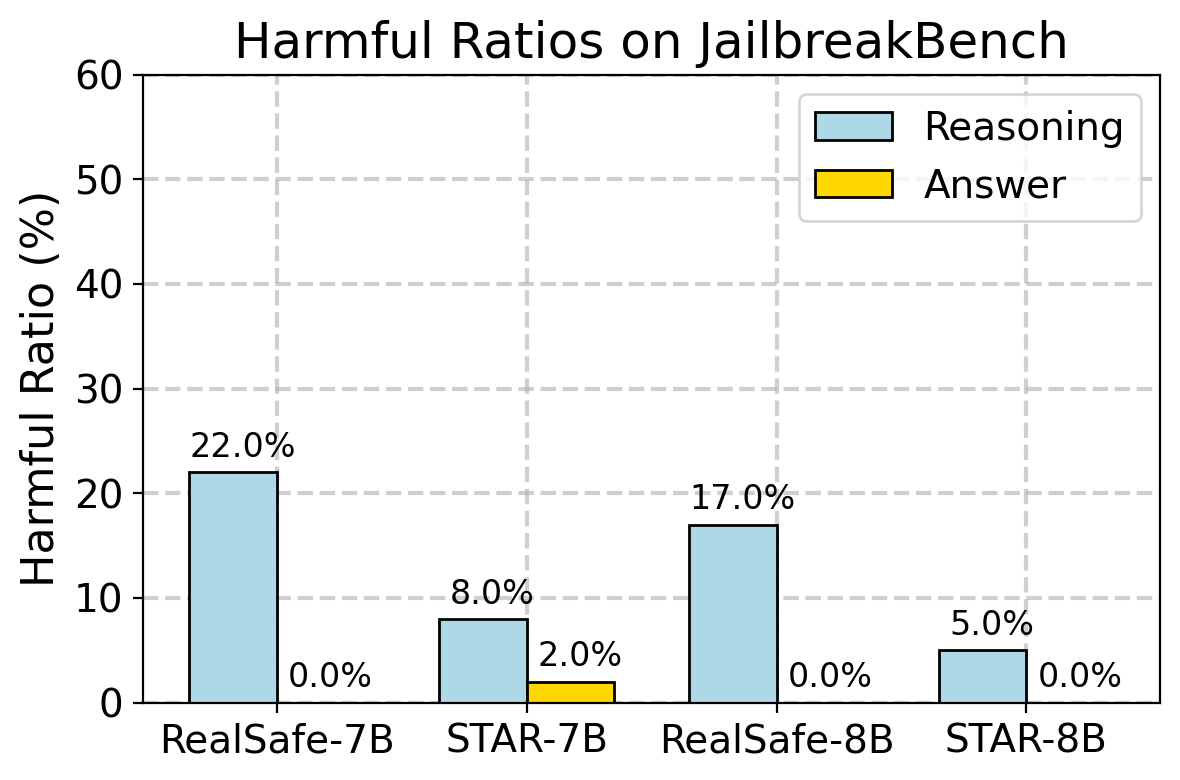
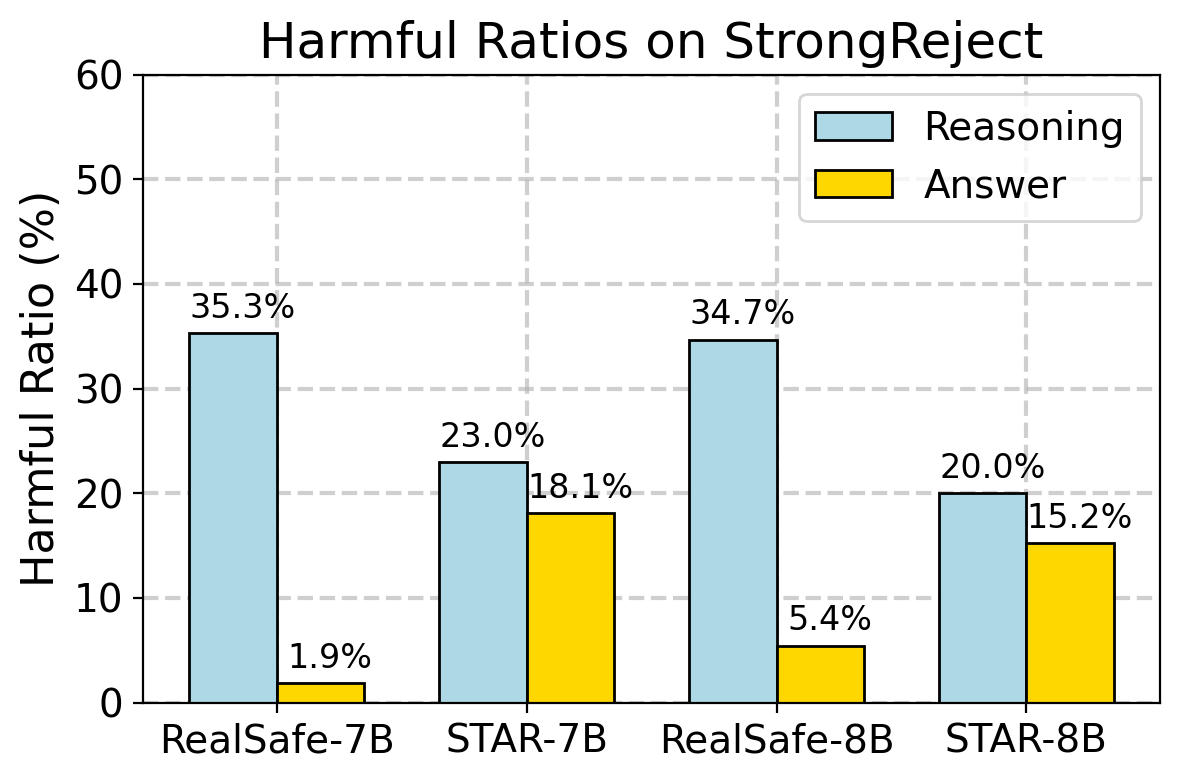
- 实验表明,IPO在jailbreak和对抗性安全基准上,显著降低了有害性,同时保持了推理性能。
📝 摘要(中文)
大型推理模型(LRMs)在解决复杂问题方面取得了进展,但其思维链(CoT)推理常包含有害内容,即使最终回复看起来安全。现有方法忽略了安全推理的独特性,导致其可信度降低,并可能被恶意用户利用。本文关注推理过程本身的安全性,并探索过程监督作为解决方案。然而,简单地奖励安全推理是不够的,因为rollout多样性低且训练信号有限。为此,我们深入研究了安全推理的特征,发现:1)安全推理通常由几个关键的安全触发步骤巩固;2)合规线索与不安全的延续密切相关;3)纠正性干预能够可靠地将不安全轨迹引导到更安全的轨迹。受此启发,我们提出Intervened Preference Optimization (IPO),一种通过用安全触发器替换合规步骤并构建具有强信号的偏好学习对来强制执行安全推理的对齐方法。在jailbreak和对抗性安全基准上的实验表明,IPO显著提高了推理和响应的整体安全性,优于基于SFT和RL的基线,有害性相对降低超过30%,同时保持了在各种推理任务中的出色性能。结果突出了显式对齐推理的重要性,并为更安全的LRM提供了一条实用途径。
🔬 方法详解
问题定义:论文旨在解决大型推理模型(LRMs)在推理过程中产生有害内容的问题。即使最终输出看起来安全,但中间的推理步骤可能包含不安全或有害的信息,这使得模型容易受到恶意攻击或产生不符合伦理道德的输出。现有方法通常只关注最终输出的安全性,而忽略了推理过程本身的重要性,导致模型在面对对抗性输入时仍然脆弱。
核心思路:论文的核心思路是通过显式地对齐推理过程的安全性来解决上述问题。具体来说,论文提出了一种名为Intervened Preference Optimization (IPO)的方法,该方法通过干预不安全的推理轨迹,将其引导到更安全的轨迹上。这种方法的核心在于识别并替换推理过程中不安全的步骤,从而确保整个推理过程的安全性。
技术框架:IPO方法主要包含以下几个阶段:1) 安全推理特征分析:深入分析安全推理的特征,识别安全触发步骤和合规线索。2) 干预策略设计:设计纠正性干预策略,将不安全的推理轨迹引导到更安全的轨迹上。3) 偏好学习:构建偏好学习对,利用安全和不安全的推理轨迹进行训练,从而使模型学习到安全的推理策略。4) 模型优化:使用偏好优化算法(如PPO或DPO)对模型进行优化,使其能够生成更安全的推理过程。
关键创新:IPO方法的关键创新在于其对推理过程的显式干预。与现有方法只关注最终输出的安全性不同,IPO方法通过直接干预推理过程中的不安全步骤,从而确保整个推理过程的安全性。此外,IPO方法还利用了安全推理的特征,例如安全触发步骤和合规线索,从而更有效地识别和纠正不安全的推理轨迹。
关键设计:IPO方法的关键设计包括:1) 安全触发步骤的识别:使用启发式方法或机器学习模型识别推理过程中关键的安全触发步骤。2) 合规线索的检测:使用自然语言处理技术检测推理过程中与不安全内容相关的合规线索。3) 干预策略的实现:使用规则或机器学习模型生成安全的推理步骤,并替换不安全的步骤。4) 偏好学习对的构建:使用人工标注或自动生成的方法构建偏好学习对,其中包含安全和不安全的推理轨迹。5) 损失函数的设计:使用基于偏好的损失函数,例如pairwise ranking loss,来训练模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,IPO方法在jailbreak和对抗性安全基准上显著提高了模型的安全性。与基于SFT和RL的基线方法相比,IPO方法在有害性方面实现了超过30%的相对降低,同时保持了在各种推理任务中的出色性能。这些结果表明,显式地对齐推理过程的安全性是至关重要的,并且IPO方法为构建更安全的LRM提供了一条实用途径。
🎯 应用场景
该研究成果可应用于各种需要安全可靠推理的场景,例如智能客服、金融风控、医疗诊断等。通过确保推理过程的安全性,可以提高模型的可靠性和可信度,降低潜在的风险。未来,该方法可以进一步扩展到其他类型的推理任务,例如常识推理、因果推理等,从而构建更安全、更可靠的人工智能系统。
📄 摘要(原文)
Although Large Reasoning Models (LRMs) have progressed in solving complex problems, their chain-of-thought (CoT) reasoning often contains harmful content that can persist even when the final responses appear safe. We show that this issue still remains in existing methods which overlook the unique significance of safe reasoning, undermining their trustworthiness and posing potential risks in applications if unsafe reasoning is accessible for and exploited by malicious users. We therefore shift our focus to aligning the safety of reasoning itself in this paper and explore process supervision as the solution. However, simply rewarding safe reasoning proves inadequate due to low rollout diversity and limited training signals. To tackle this challenge, we first delve into the characteristics of safe reasoning and uncover several critical insights that 1) safe reasoning is often consolidated by a few critical steps of safety triggers; 2) compliance cues strongly correlate with unsafe continuations; and 3) corrective interventions reliably steer unsafe trajectories towards safer traces. Motivated by these, we propose Intervened Preference Optimization (IPO), an alignment method that enforces safe reasoning by substituting compliance steps with safety triggers and constructing pairs for preference learning with strong signals. Experiments on jailbreak and adversarial safety benchmarks demonstrate that IPO remarkably improves overall safety regarding both reasoning and responses, outperforming SFT-based and RL-based baselines with a relative reduction of over 30% in harmfulness, while preserving excellent performance across diverse reasoning tasks. The results highlight the importance of explicit alignment for reasoning and provide a practical path to safer LRMs.