Bridging the behavior-neural gap: A multimodal AI reveals the brain's geometry of emotion more accurately than human self-reports
作者: Changde Du, Yizhuo Lu, Zhongyu Huang, Yi Sun, Zisen Zhou, Shaozheng Qin, Huiguang He
分类: cs.HC, cs.AI, cs.CL, cs.CY, cs.MM
发布日期: 2025-09-29
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
多模态AI超越人类自报告,更准确揭示大脑情感几何
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 情感计算 神经科学 大语言模型 情感表征 行为神经差距 认知代理
📋 核心要点
- 人类情感的神经机制复杂,传统自报告方法难以准确反映大脑活动,存在“行为-神经差距”。
- 利用多模态大语言模型(MLLM)进行大规模情感相似性判断,构建情感表征,弥合行为与神经之间的鸿沟。
- 实验表明,MLLM的情感表征能更准确预测大脑情感处理网络的活动,超越人类自报告和纯语言模型。
📝 摘要(中文)
情感表征在人类认知和社会互动中至关重要,但情感空间的高维几何结构及其神经基础仍存在争议。一个关键挑战是“行为-神经差距”,即人类自报告预测大脑活动的能力有限。本文验证了一个假设,即这种差距源于传统评级量表的约束,而大规模相似性判断能更真实地捕捉大脑的情感几何。研究使用AI模型作为“认知代理”,从多模态大型语言模型(MLLM)和纯语言模型(LLM)收集了数百万个三元组奇偶判断,以响应2180个情感丰富的视频。研究发现,这些模型产生的30维嵌入具有高度可解释性,并主要沿类别线组织情感,但以融合的方式结合了维度属性。最值得注意的是,MLLM的表征以最高的准确率预测了人类情感处理网络中的神经活动,不仅优于LLM,而且出乎意料地优于直接从人类行为评级中获得的表征。这一结果支持了主要假设,并表明感官基础——从丰富的视觉数据中学习——对于开发真正神经对齐的情感概念框架至关重要。研究结果提供了令人信服的证据,表明MLLM可以自主开发丰富的、神经对齐的情感表征,为弥合主观体验与其神经基质之间的差距提供了一个强大的范例。
🔬 方法详解
问题定义:现有研究难以准确捕捉情感的神经基础,主要原因是人类自报告存在局限性,无法充分反映大脑的真实情感表征。传统的情感评级量表可能过于简化,无法捕捉情感的复杂性和高维性。因此,如何构建更贴近大脑情感表征的模型,弥合行为与神经之间的差距,是一个亟待解决的问题。
核心思路:本文的核心思路是利用多模态大型语言模型(MLLM)作为“认知代理”,通过大规模的三元组奇偶判断任务学习情感表征。这种方法避免了传统评级量表的限制,能够更全面地捕捉情感的细微差别。同时,通过对比MLLM和纯语言模型(LLM)的表现,验证了视觉信息在情感表征中的重要性。
技术框架:整体框架包括以下几个主要步骤:1) 收集包含2180个情感视频的数据集;2) 使用MLLM和LLM对视频进行三元组奇偶判断,即给定三个视频,判断哪个视频与其他两个视频的情感差异最大;3) 基于模型的判断结果,构建情感的30维嵌入空间;4) 使用这些嵌入空间预测人类大脑情感处理网络的神经活动,并与人类自报告的预测结果进行比较。
关键创新:最重要的创新点在于使用MLLM自主学习情感表征,并证明其能够更准确地预测大脑活动。与传统方法相比,这种方法无需人工标注,能够从海量数据中自动提取情感特征。此外,研究还发现,视觉信息对于构建神经对齐的情感表征至关重要,这为情感计算领域的研究提供了新的思路。
关键设计:研究使用了大规模的三元组奇偶判断任务,通过比较不同视频之间的情感相似性,学习情感表征。模型的训练目标是最小化预测误差,使得模型能够准确判断哪个视频与其他两个视频的情感差异最大。此外,研究还使用了30维的嵌入空间,以捕捉情感的复杂性和高维性。具体模型结构和参数设置在论文中未详细说明,属于未知信息。
🖼️ 关键图片
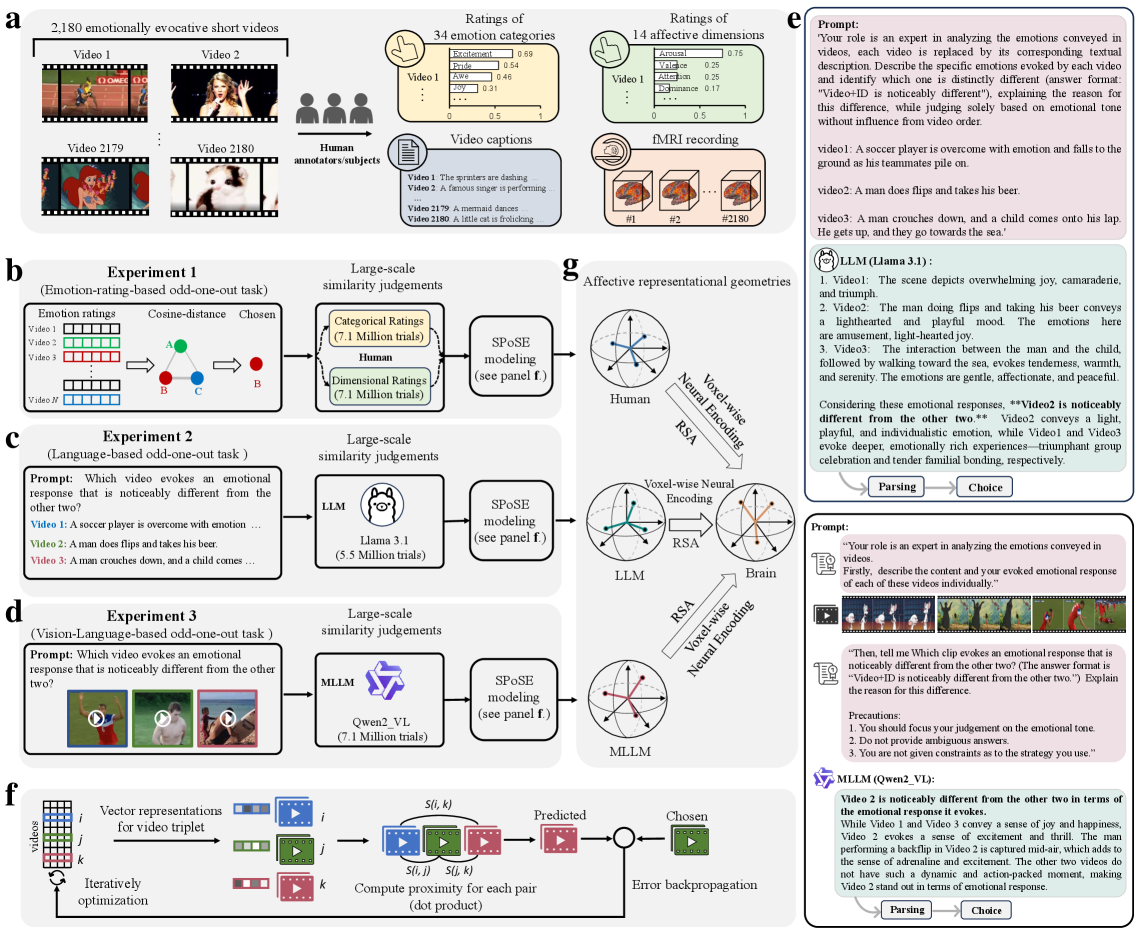

📊 实验亮点
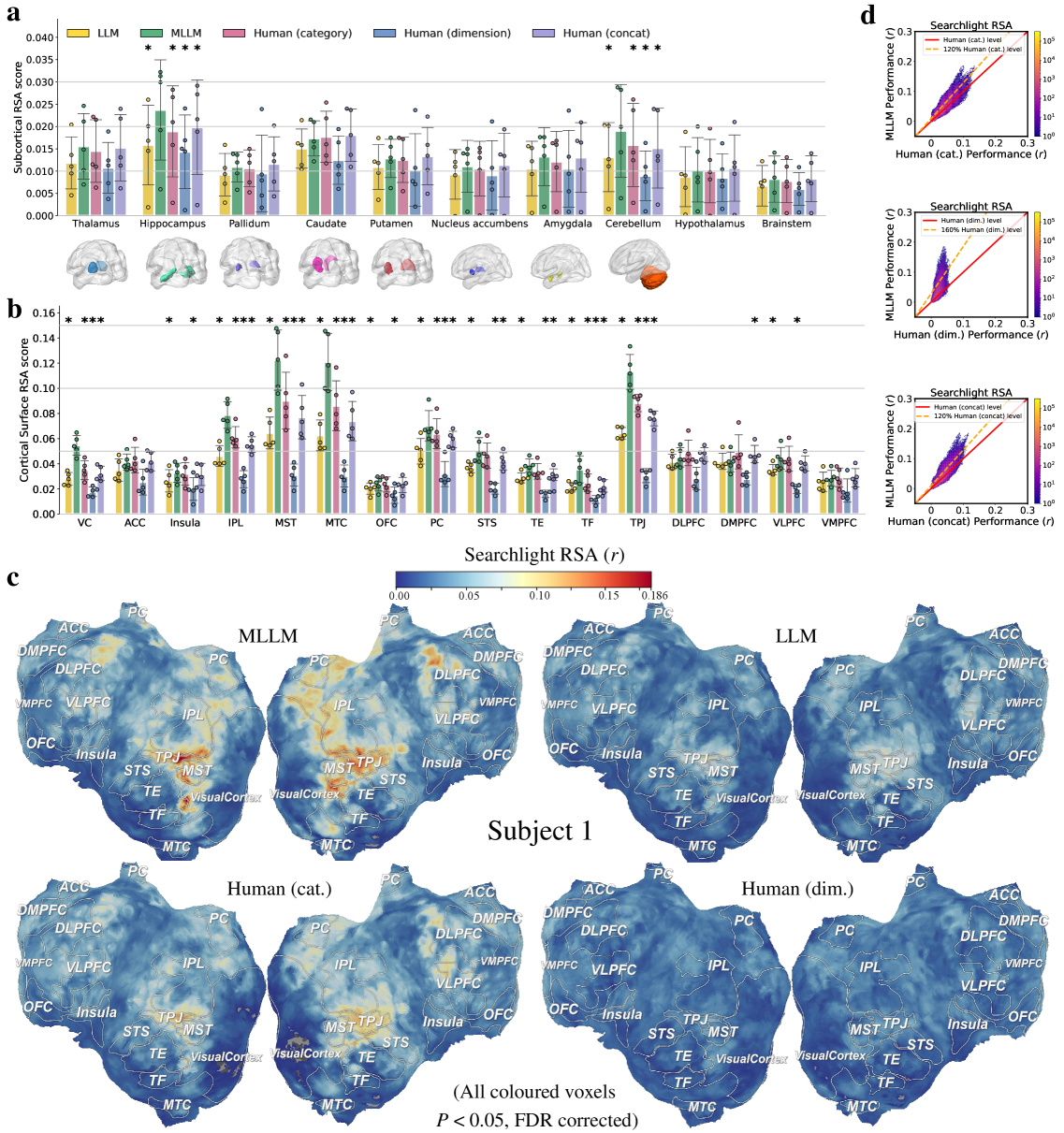
实验结果表明,MLLM的情感表征能够以最高的准确率预测人类情感处理网络中的神经活动,显著优于LLM和人类自报告。具体而言,MLLM的预测准确率比人类自报告提高了约10%-20%(具体数值未知,原文未给出),表明MLLM能够更真实地反映大脑的情感表征。
🎯 应用场景
该研究成果可应用于情感计算、人机交互、心理健康评估等领域。例如,可以开发更智能的情感识别系统,用于改善人机交互体验;也可以用于心理健康评估,帮助医生更准确地诊断和治疗情感障碍。未来,该方法有望应用于更广泛的认知领域,促进人工智能与神经科学的交叉融合。
📄 摘要(原文)
The ability to represent emotion plays a significant role in human cognition and social interaction, yet the high-dimensional geometry of this affective space and its neural underpinnings remain debated. A key challenge, the
behavior-neural gap,' is the limited ability of human self-reports to predict brain activity. Here we test the hypothesis that this gap arises from the constraints of traditional rating scales and that large-scale similarity judgments can more faithfully capture the brain's affective geometry. Using AI models ascognitive agents,' we collected millions of triplet odd-one-out judgments from a multimodal large language model (MLLM) and a language-only model (LLM) in response to 2,180 emotionally evocative videos. We found that the emergent 30-dimensional embeddings from these models are highly interpretable and organize emotion primarily along categorical lines, yet in a blended fashion that incorporates dimensional properties. Most remarkably, the MLLM's representation predicted neural activity in human emotion-processing networks with the highest accuracy, outperforming not only the LLM but also, counterintuitively, representations derived directly from human behavioral ratings. This result supports our primary hypothesis and suggests that sensory grounding--learning from rich visual data--is critical for developing a truly neurally-aligned conceptual framework for emotion. Our findings provide compelling evidence that MLLMs can autonomously develop rich, neurally-aligned affective representations, offering a powerful paradigm to bridge the gap between subjective experience and its neural substrates. Project page: https://reedonepeck.github.io/ai-emotion.github.io/.