Model Merging Scaling Laws in Large Language Models
作者: Yuanyi Wang, Yanggan Gu, Yiming Zhang, Qi Zhou, Zhaoyi Yan, Congkai Xie, Xinyao Wang, Jianbo Yuan, Hongxia Yang
分类: cs.AI
发布日期: 2025-09-29 (更新: 2025-10-01)
备注: 30 pages
💡 一句话要点
提出语言模型融合的规模法则,实现专家模型高效组合与性能预测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型融合 规模法则 语言模型 专家模型 分布式AI
📋 核心要点
- 现有模型融合方法缺乏量化规则,难以预测增加专家模型或扩大模型规模带来的收益。
- 论文提出一个幂律,关联模型大小和专家数量,揭示了模型融合的规模效应和收益递减规律。
- 实验验证了该定律在不同架构和方法上的有效性,并基于此提出了模型融合的预测性规划。
📝 摘要(中文)
本文研究了语言模型融合的经验规模法则,以交叉熵作为衡量标准。尽管模型融合在实践中应用广泛,但缺乏量化规则来预测随着专家数量增加或模型规模扩大带来的收益。我们发现了一个紧凑的幂律,它将模型大小和专家数量联系起来:依赖于模型大小的下限随着模型容量的增加而降低,而融合尾部则表现出明显的专家数量递减效应。该定律在领域内和跨领域都成立,紧密拟合了各种架构和方法(Average, TA, TIES, DARE)的测量曲线,并解释了两个稳健的规律:大部分收益出现在早期,并且随着包含的专家数量的增加,可变性会缩小。在此基础上,我们提出了一个简单的理论,解释了为什么收益大致以 1/k 的速度下降,并将下限和尾部与基础模型的属性和跨领域的多样性联系起来。该定律支持预测性规划:估计达到目标损失所需的专家数量,决定何时停止添加专家,并在固定预算下权衡缩放基础模型与添加专家——将融合从启发式实践转变为计算高效、可规划的替代多任务训练方案。这表明了分布式生成式人工智能的规模化原则:通过组合专家可以实现可预测的收益,从而为实现 AGI 级别的系统提供了一条互补的道路。
🔬 方法详解
问题定义:论文旨在解决语言模型融合过程中缺乏量化指导的问题。现有方法依赖启发式实践,难以预测融合带来的性能提升,也无法有效指导如何选择专家模型数量和基础模型大小,从而限制了模型融合的效率和可扩展性。
核心思路:论文的核心思路是发现并建立模型融合性能与模型规模、专家数量之间的定量关系,即规模法则。通过分析大量实验数据,揭示了模型融合收益随专家数量增加而递减的规律,并将其与模型规模联系起来,从而实现对融合过程的预测和优化。
技术框架:论文的技术框架主要包括以下几个部分:1) 大量实验数据的收集,涵盖不同架构、不同融合方法和不同领域的数据;2) 对实验数据进行分析,寻找模型融合性能与模型规模、专家数量之间的关系;3) 提出一个紧凑的幂律来描述这种关系,并验证其在不同场景下的有效性;4) 基于该幂律,提出模型融合的预测性规划方法,指导专家模型数量的选择和基础模型大小的调整。
关键创新:论文最重要的技术创新点在于发现了模型融合的规模法则,即模型融合性能与模型规模、专家数量之间的定量关系。该法则能够预测模型融合的收益,指导专家模型数量的选择和基础模型大小的调整,从而将模型融合从启发式实践转变为可规划的优化过程。
关键设计:论文的关键设计包括:1) 使用交叉熵作为衡量模型融合性能的指标;2) 采用幂律来描述模型融合性能与模型规模、专家数量之间的关系;3) 通过实验验证该幂律在不同架构、不同融合方法和不同领域下的有效性;4) 基于该幂律,提出模型融合的预测性规划方法,包括估计达到目标损失所需的专家数量、决定何时停止添加专家等。
🖼️ 关键图片
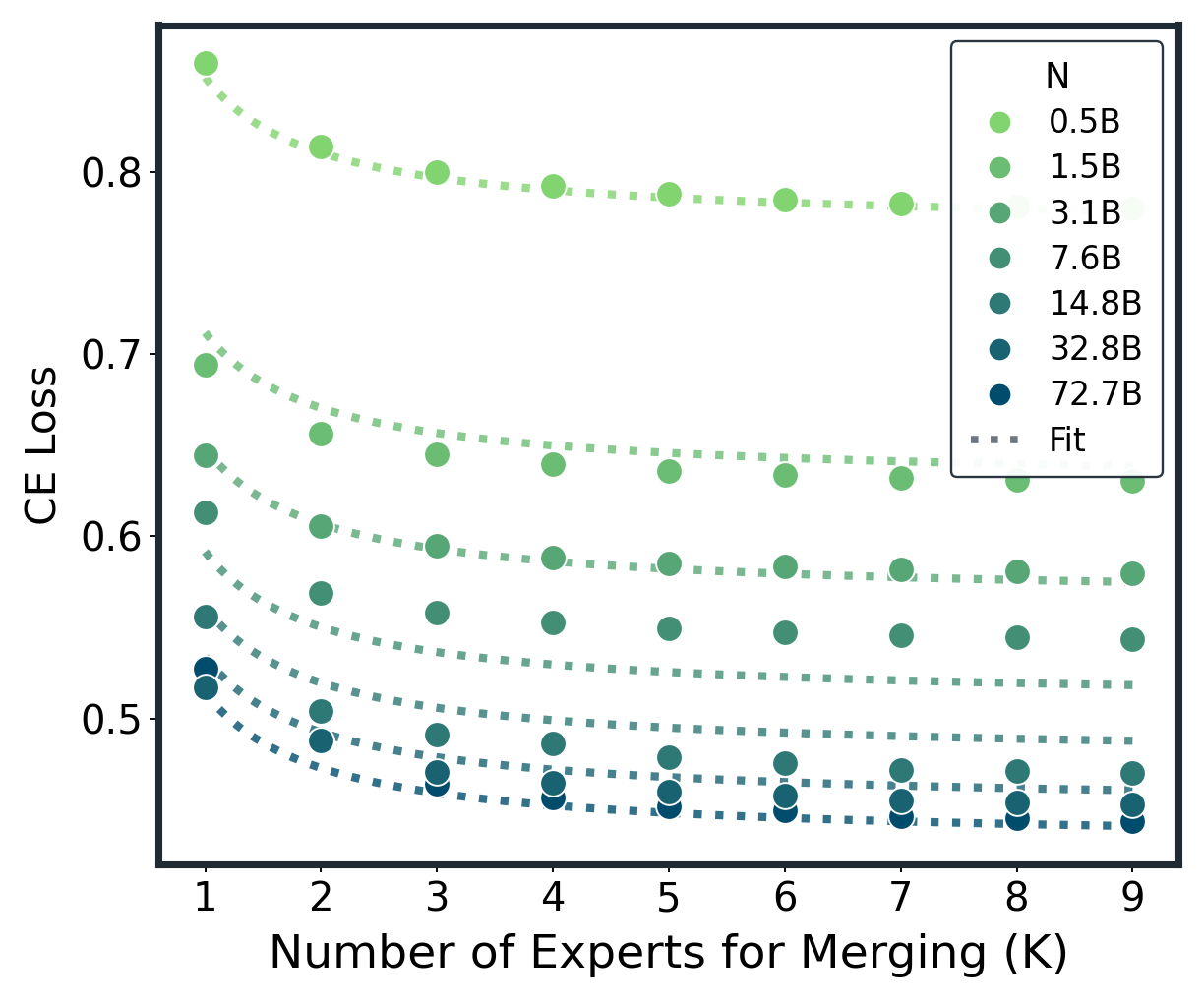
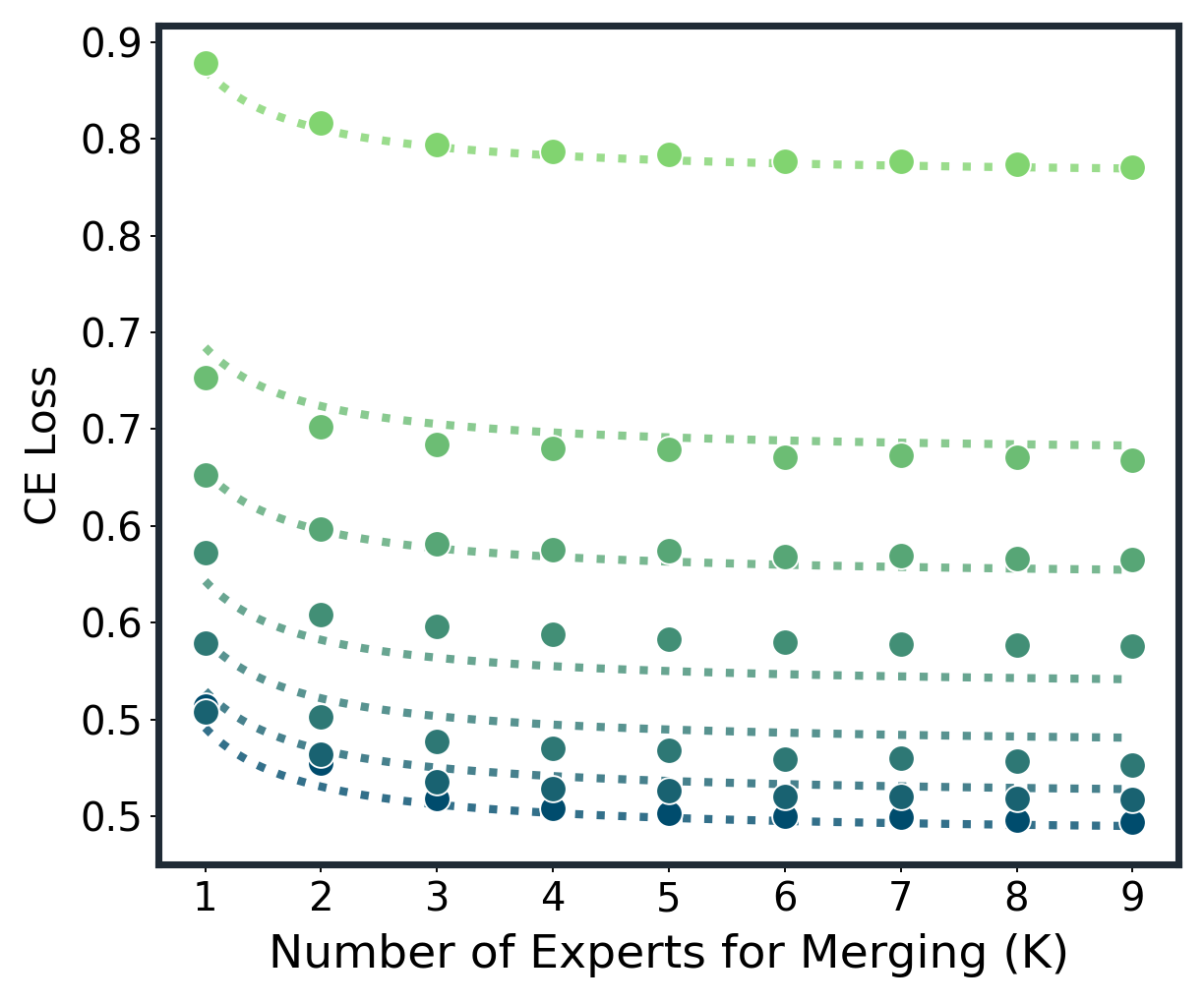
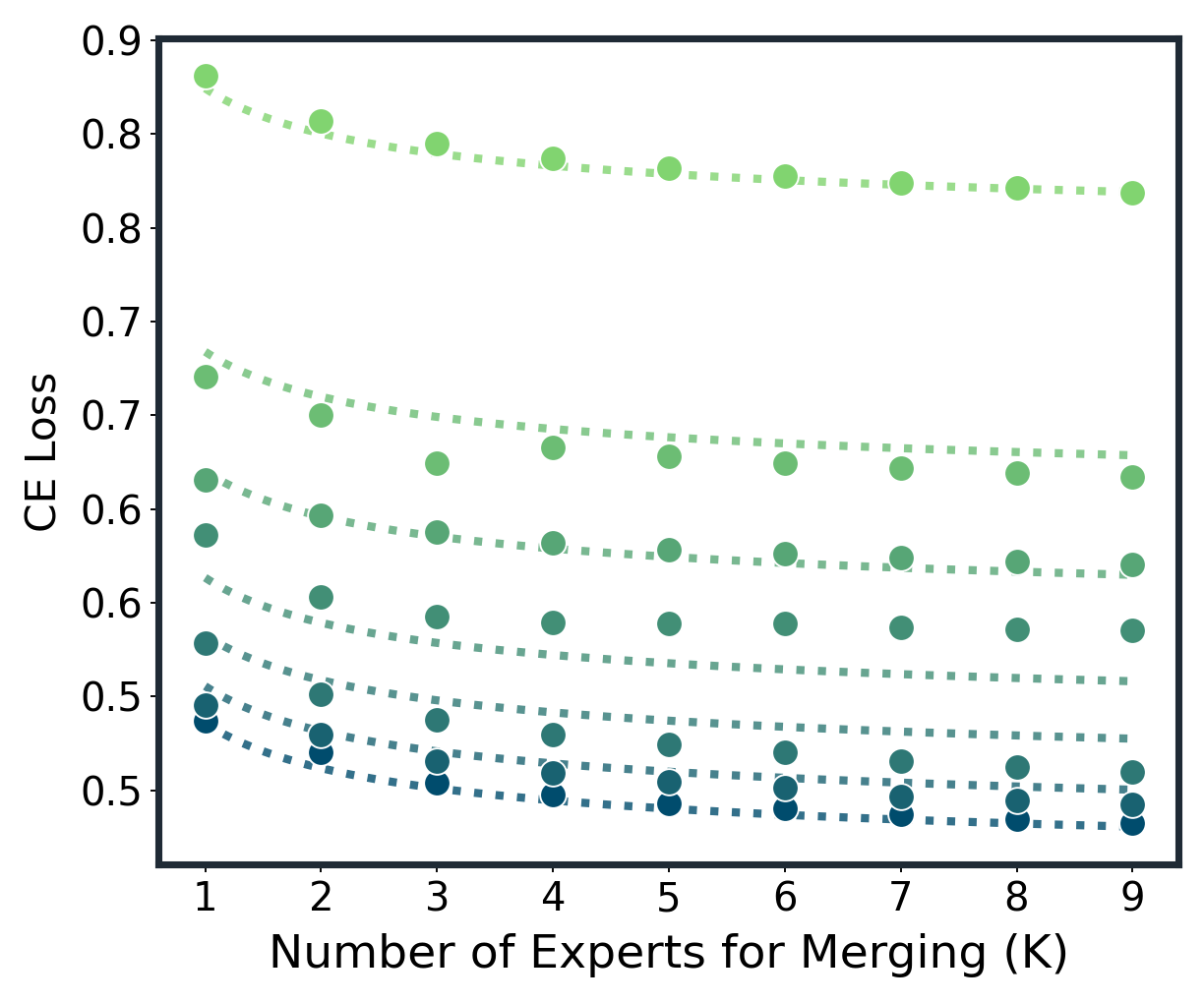
📊 实验亮点
论文通过大量实验验证了提出的规模法则的有效性,涵盖了多种模型架构(如Transformer)和融合方法(如Average, TA, TIES, DARE)。实验结果表明,该法则能够紧密拟合不同场景下的模型融合曲线,并准确预测模型融合的收益。此外,该研究还解释了模型融合中常见的两个现象:大部分收益出现在早期,以及随着专家数量的增加,可变性会缩小。
🎯 应用场景
该研究成果可应用于分布式生成式人工智能,通过组合专家模型实现可预测的性能提升。它能够指导模型融合的实践,优化资源分配,提高模型训练效率,并为构建AGI级别的系统提供一种可行的途径。例如,在资源有限的情况下,可以根据该法则权衡是扩大基础模型规模还是增加专家模型数量,以达到最佳性能。
📄 摘要(原文)
We study empirical scaling laws for language model merging measured by cross-entropy. Despite its wide practical use, merging lacks a quantitative rule that predicts returns as we add experts or scale the model size. We identify a compact power law that links model size and expert number: the size-dependent floor decreases with model capacity, while the merging tail exhibits clear diminishing returns in the number of experts. The law holds in-domain and cross-domain, tightly fits measured curves across diverse architectures and methods (Average, TA, TIES, DARE), and explains two robust regularities: most gains arrive early, and variability shrinks as more experts are included. Building on this, we present a simple theory that explains why gains fall roughly as 1/k and links the floor and tail to properties of the base model and the diversity across domains. This law enables predictive planning: estimate how many experts are needed to reach a target loss, decide when to stop adding experts, and trade off scaling the base model versus adding experts under a fixed budget--turning merging from heuristic practice into a computationally efficient, planable alternative to multitask training. This suggests a scaling principle for distributed generative AI: predictable gains can be achieved by composing specialists, offering a complementary path toward AGI-level systems.