Humanline: Online Alignment as Perceptual Loss
作者: Sijia Liu, Niklas Muennighoff, Kawin Ethayarajh
分类: cs.AI
发布日期: 2025-09-29
💡 一句话要点
提出Humanline,通过感知损失在线对齐,提升模型与人类偏好一致性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 在线对齐 离线对齐 人类偏好 前景理论 感知损失 行为经济学 强化学习 语言模型
📋 核心要点
- 现有离线对齐方法在性能上不如在线对齐,缺乏对人类偏好背后深层原因的解释。
- 论文核心思想是利用前景理论,将人类对概率的感知偏差融入到模型训练中,模拟人类的感知过程。
- 实验结果表明,即使使用离线数据,Humanline变体也能达到与在线方法相当的性能,降低了训练成本。
📝 摘要(中文)
在线对齐(如GRPO)通常比离线对齐(如DPO)表现更好,但原因是什么?本文借鉴行为经济学中的前景理论,提出了以人为中心的解释。我们证明了在线on-policy采样能更好地近似模型可生成内容的“人类感知分布”,并且PPO/GRPO风格的裁剪(最初是为了稳定训练而引入的)恢复了人类感知概率时的感知偏差。从这个意义上说,PPO/GRPO已经充当了感知损失。我们的理论进一步表明,在线/离线二分法本身对于最大化人类效用来说是偶然的,因为我们可以通过以模仿人类感知的方式选择性地训练任何数据来实现相同的效果,而不是将自己限制于在线on-policy数据。这样做可以让我们更快、更便宜、更灵活地进行后训练,而不会牺牲性能。为此,我们提出了一种设计模式,将概率的感知失真显式地纳入DPO/KTO/GRPO等目标中,从而创建它们的humanline变体。令人惊讶的是,我们发现这些humanline变体,即使使用离线off-policy数据进行训练,也可以在可验证和不可验证的任务上与它们的在线对应物相媲美。
🔬 方法详解
问题定义:现有离线对齐方法(如DPO)在对齐模型与人类偏好方面不如在线方法(如GRPO)。现有方法缺乏对人类偏好背后认知机制的深入理解,导致训练效率和最终性能受限。如何利用离线数据达到甚至超越在线对齐的效果是一个关键问题。
核心思路:论文的核心思路是借鉴行为经济学中的前景理论,认为人类对概率的感知存在偏差。通过将这种感知偏差显式地纳入到模型的训练目标中,可以使模型更好地对齐人类偏好。具体来说,就是通过修改损失函数,使其能够反映人类对概率的主观感知,从而优化模型。
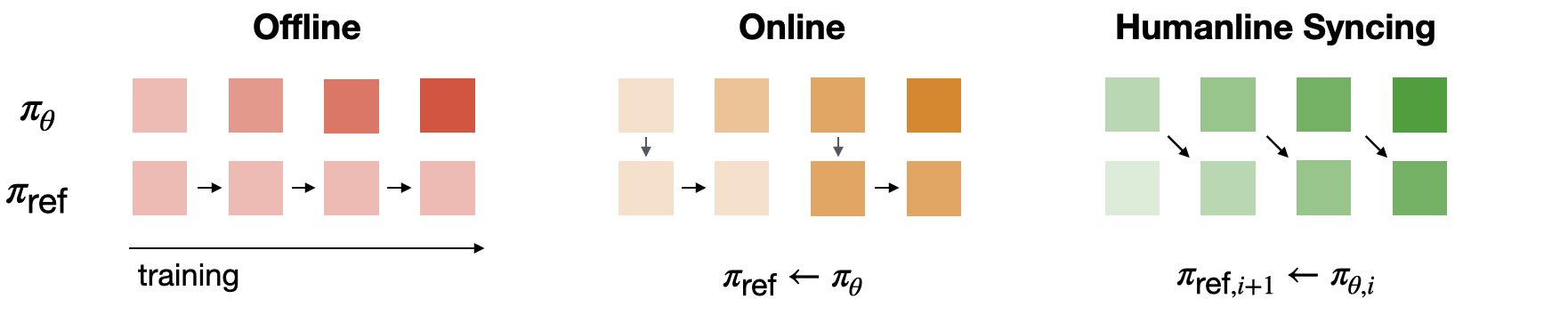
技术框架:论文提出了一个名为Humanline的设计模式,它可以应用于现有的对齐方法(如DPO、KTO、GRPO)。Humanline的核心在于引入一个感知失真函数,该函数模拟了人类在感知概率时的偏差。该函数被整合到原有的损失函数中,从而使模型在训练过程中考虑到人类的感知特性。整体流程包括:1)收集训练数据;2)使用感知失真函数对数据进行处理;3)使用修改后的损失函数训练模型。
关键创新:最重要的技术创新点在于将人类的感知偏差显式地建模到模型的训练过程中。与现有方法不同,Humanline不仅关注数据的分布,还关注人类如何感知这些数据。这种以人为中心的视角使得模型能够更好地理解和对齐人类的偏好。此外,该方法允许使用离线数据进行训练,大大提高了训练效率和灵活性。
关键设计:关键设计包括感知失真函数的选择和损失函数的修改。感知失真函数需要能够准确地模拟人类在感知概率时的偏差,例如,可以采用前景理论中的价值函数。损失函数的修改需要确保模型在优化过程中既能对齐数据分布,又能考虑到人类的感知特性。具体的参数设置和网络结构取决于具体的应用场景和所使用的基础模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Humanline变体即使使用离线off-policy数据进行训练,也能在可验证和不可验证的任务上达到与在线对应物相当的性能。这表明Humanline成功地将人类感知偏差融入到模型训练中,使得离线训练也能达到在线训练的效果,从而降低了训练成本和提高了训练效率。
🎯 应用场景
该研究成果可广泛应用于各种需要与人类偏好对齐的人工智能系统,例如对话系统、推荐系统、内容生成等。通过Humanline方法,可以更高效地训练出符合人类价值观和审美标准的AI模型,提升用户体验和满意度。此外,该方法还可以用于评估和改进现有AI系统的公平性和安全性。
📄 摘要(原文)
Online alignment (e.g., GRPO) is generally more performant than offline alignment (e.g., DPO) -- but why? Drawing on prospect theory from behavioral economics, we propose a human-centric explanation. We prove that online on-policy sampling better approximates the human-perceived distribution of what the model can produce, and PPO/GRPO-style clipping -- originally introduced to just stabilize training -- recovers a perceptual bias in how humans perceive probability. In this sense, PPO/GRPO act as perceptual losses already. Our theory further suggests that the online/offline dichotomy is itself incidental to maximizing human utility, since we can achieve the same effect by selectively training on any data in a manner that mimics human perception, rather than restricting ourselves to online on-policy data. Doing so would allow us to post-train more quickly, cheaply, and flexibly without sacrificing performance. To this end, we propose a design pattern that explicitly incorporates perceptual distortions of probability into objectives like DPO/KTO/GRPO, creating humanline variants of them. Surprisingly, we find that these humanline variants, even when trained with offline off-policy data, can match the performance of their online counterparts on both verifiable and unverifiable tasks.