RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment
作者: Xiaoyang Cao, Zelai Xu, Mo Guang, Kaiwen Long, Michiel A. Bakker, Yu Wang, Chao Yu
分类: cs.AI
发布日期: 2025-09-29 (更新: 2025-12-05)
💡 一句话要点
RE-PO:一种通用的LLM对齐框架,通过鲁棒增强策略优化解决标签噪声问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM对齐 标签噪声 鲁棒学习 策略优化 期望最大化
📋 核心要点
- 现有基于人类反馈的强化学习(RLHF)等对齐方法易受偏好数据集中标签噪声的影响,导致模型性能下降。
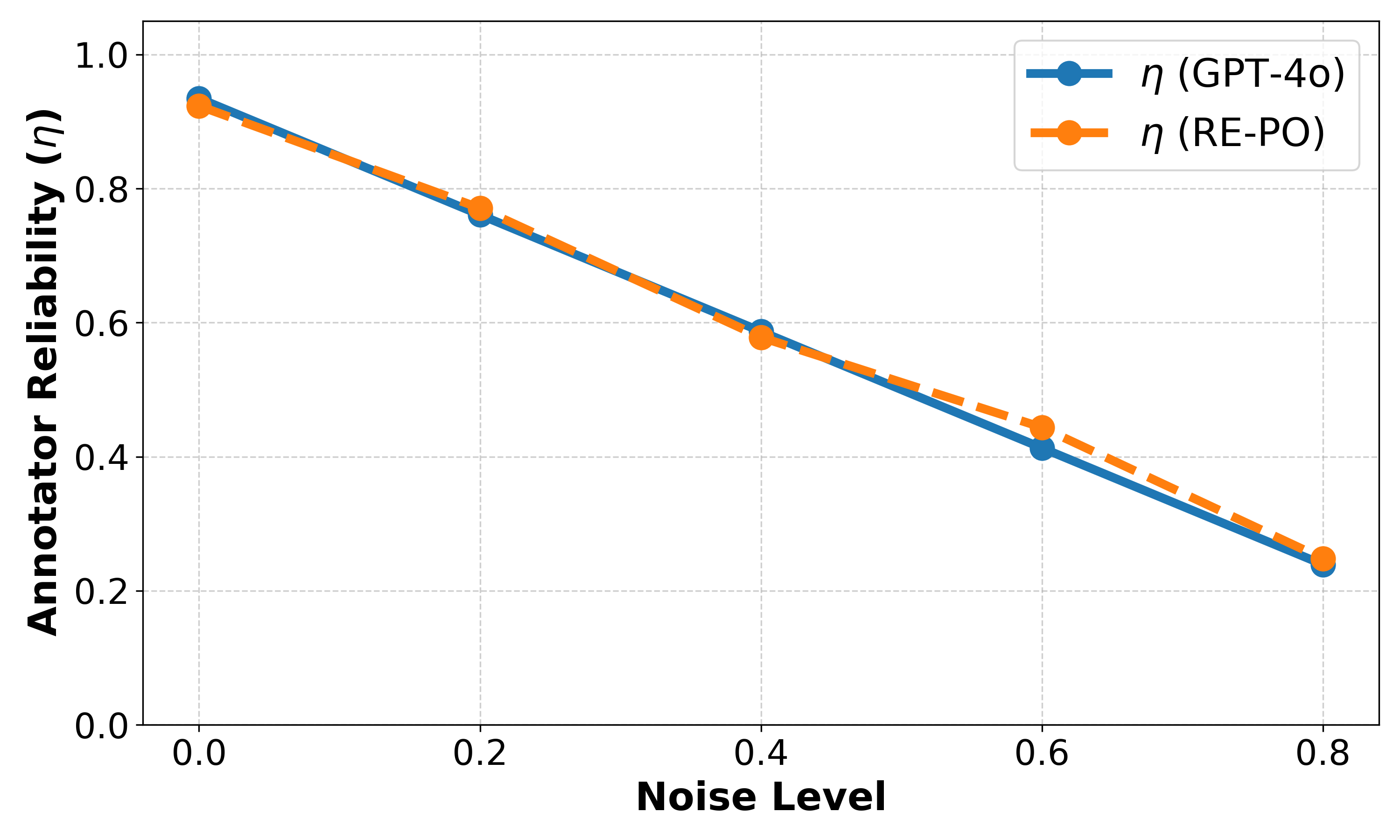
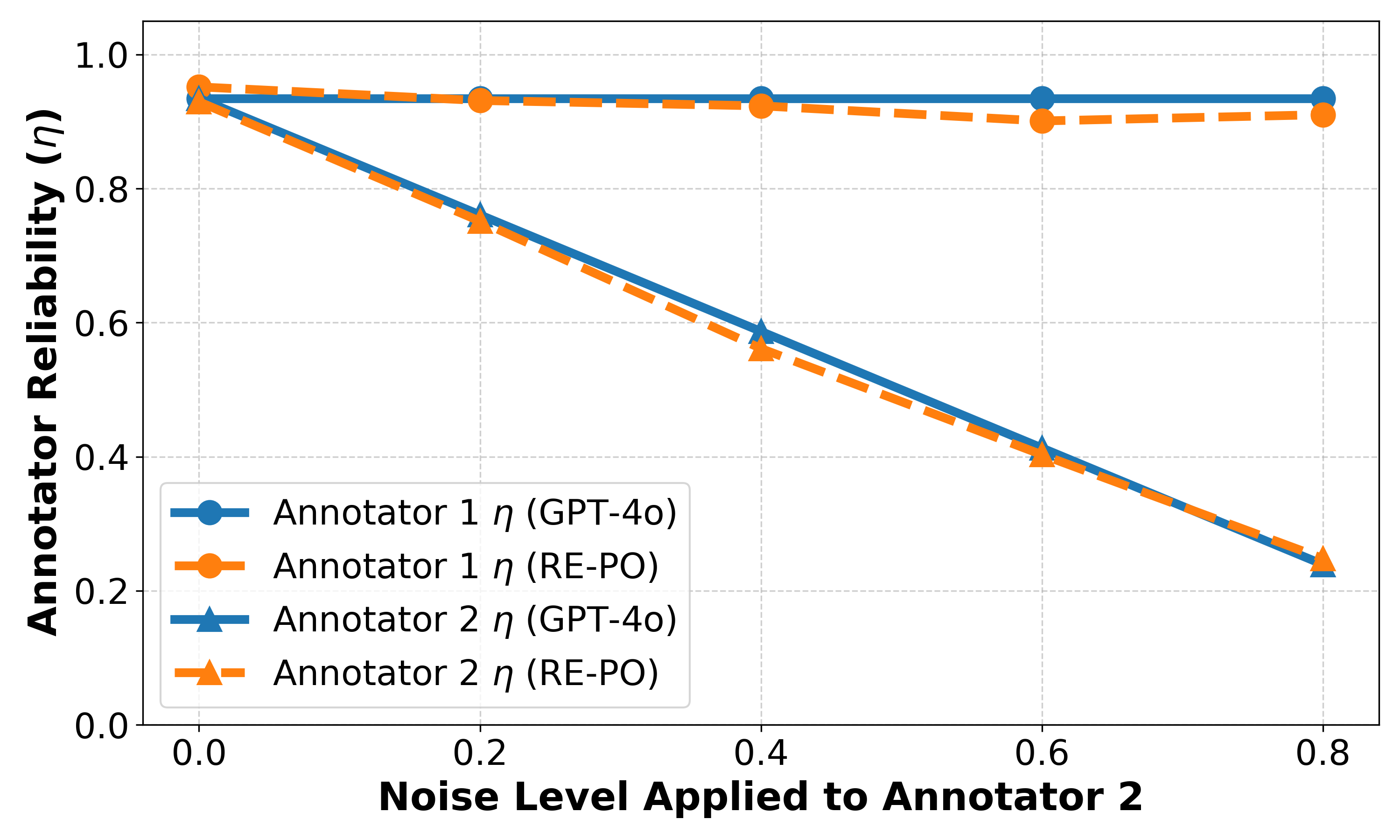
- RE-PO通过EM算法推断标签的后验正确性,并自适应地调整数据点权重,从而减轻标签噪声的影响。
- 实验表明,RE-PO能有效提升DPO、IPO等多种对齐算法的性能,在AlpacaEval 2上胜率提升高达7.0%。
📝 摘要(中文)
本文提出了一种鲁棒增强策略优化(RE-PO)方法,用于解决大规模语言模型(LLM)对齐中人类偏好数据集中存在的标签噪声问题。现有方法通常假设偏好数据是干净的,但实际情况并非如此。RE-PO利用期望最大化(EM)过程推断每个标签的后验正确性,并自适应地重新加权训练损失中的数据点,从而减轻标签噪声的影响。此外,本文还将这一思想推广,建立了任意偏好损失与其底层概率模型之间的理论联系,使现有的对齐算法能够系统地转化为鲁棒版本,并将RE-PO从单一方法提升为通用的鲁棒偏好对齐框架。理论上,证明了在完美校准的模型下,RE-PO可以恢复数据集的真实噪声水平。实验结果表明,RE-PO能够持续改进四种最先进的对齐方法(DPO、IPO、SimPO和CPO),应用于Mistral和Llama 3模型时,RE-PO增强的变体在AlpacaEval 2上的胜率比各自的基线提高了高达7.0%。
🔬 方法详解
问题定义:现有基于人类偏好的LLM对齐方法,如RLHF,对数据质量要求高,容易受到大规模偏好数据集中存在的标签噪声的影响。这些噪声来源于标注错误、指令不一致、专业知识差异,甚至对抗性或低质量的反馈。这种标签与真实偏好之间的不匹配会导致训练偏差,降低模型性能。
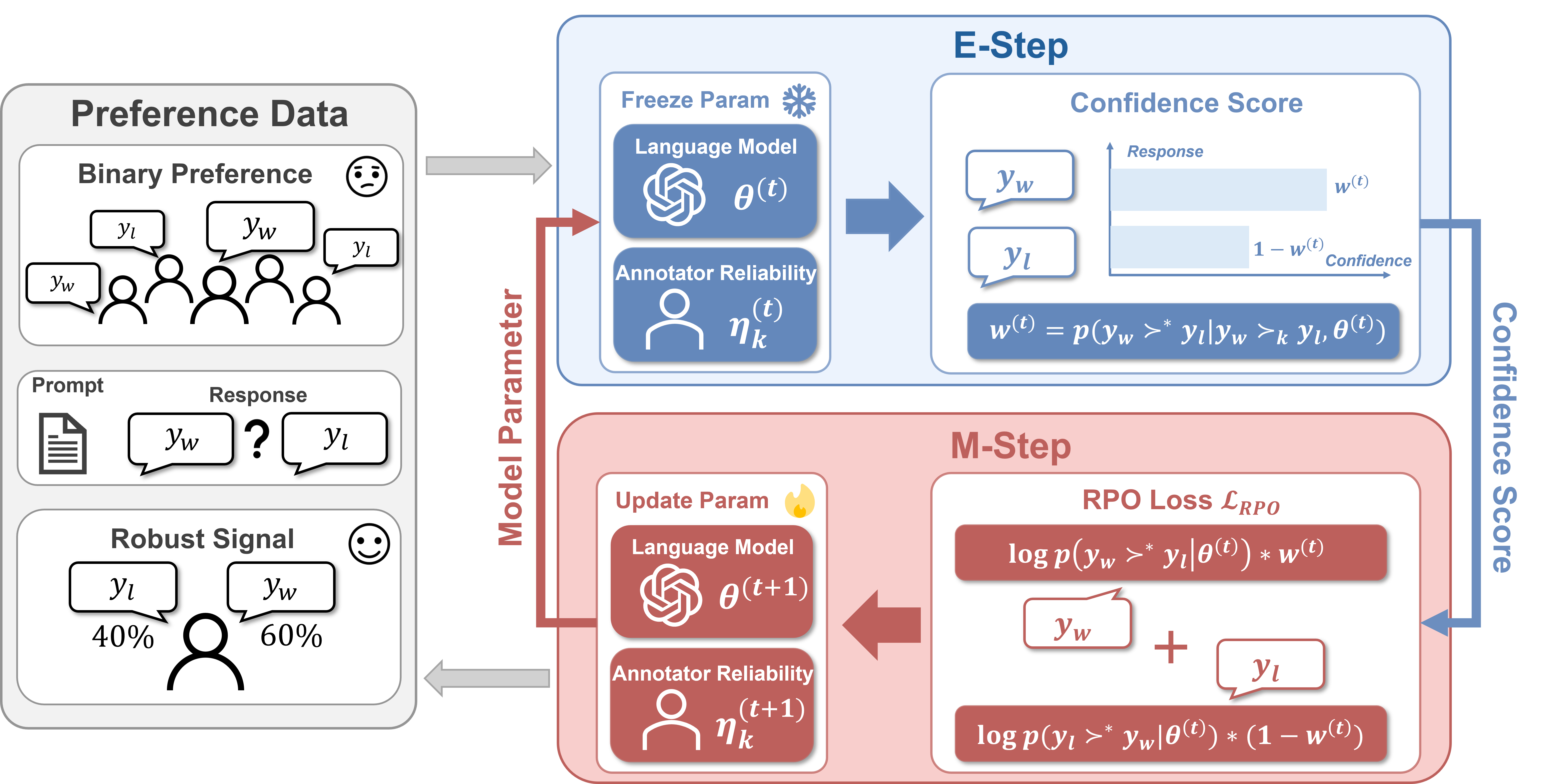
核心思路:RE-PO的核心思路是通过概率模型来估计每个标签的可靠性,并根据可靠性对数据点进行加权。具体来说,使用期望最大化(EM)算法来迭代地估计每个标签的后验正确概率,并利用这些概率来调整训练损失函数中每个数据点的权重。这样,噪声标签对训练的影响就会降低,从而提高模型的鲁棒性。
技术框架:RE-PO的整体框架包含以下几个主要步骤:1) 使用初始模型计算每个数据点的偏好概率;2) 使用EM算法,基于偏好概率估计每个标签的后验正确概率;3) 根据后验概率,重新加权训练损失函数中的数据点;4) 使用加权后的损失函数更新模型参数;5) 重复步骤1-4,直到模型收敛。这个框架可以应用于各种基于偏好学习的对齐算法。
关键创新:RE-PO的关键创新在于它将标签噪声建模为一个概率问题,并使用EM算法来估计标签的可靠性。与传统的直接使用所有标签的方法不同,RE-PO能够自适应地识别和降低噪声标签的影响。此外,RE-PO还提供了一个通用的框架,可以将现有的偏好学习算法转化为鲁棒版本。
关键设计:RE-PO的关键设计包括:1) 使用sigmoid函数将模型输出转换为偏好概率;2) 使用伯努利分布对标签的正确性进行建模;3) 使用EM算法迭代地更新标签的后验概率和模型参数;4) 使用加权交叉熵损失函数进行训练。具体来说,损失函数的形式为:L = - Σ p(correctness | label, model) * log(p(model)),其中p(correctness | label, model)是标签后验正确概率,p(model)是模型预测的偏好概率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RE-PO能够显著提升现有对齐算法的性能。例如,在AlpacaEval 2基准测试中,将RE-PO应用于Mistral和Llama 3模型,可以使DPO、IPO、SimPO和CPO等算法的胜率分别提高高达7.0%。这些结果证明了RE-PO在处理标签噪声方面的有效性,以及其作为通用对齐框架的潜力。
🎯 应用场景
RE-PO作为一种通用的LLM对齐框架,可广泛应用于各种需要利用人类偏好数据训练LLM的场景,例如对话系统、文本生成、代码生成等。通过提高模型对噪声数据的鲁棒性,RE-PO可以降低对高质量标注数据的依赖,从而降低训练成本,并提升模型在实际应用中的性能和可靠性。未来,RE-PO可以进一步扩展到处理更复杂的噪声类型,例如对抗性攻击和分布偏移。
📄 摘要(原文)
Standard human preference-based alignment methods, such as Reinforcement Learning from Human Feedback (RLHF), are a cornerstone for aligning large language models (LLMs) with human values. However, these methods typically assume that preference data is clean and that all labels are equally reliable. In practice, large-scale preference datasets contain substantial noise due to annotator mistakes, inconsistent instructions, varying expertise, and even adversarial or low-effort feedback. This mismatch between recorded labels and ground-truth preferences can misguide training and degrade model performance. To address this issue, we introduce Robust Enhanced Policy Optimization (RE-PO), which uses an expectation-maximization procedure to infer the posterior correctness of each label and then adaptively reweight data points in the training loss to mitigate label noise. We further generalize this idea by establishing a theoretical link between arbitrary preference losses and their underlying probabilistic models, enabling a systematic transformation of existing alignment algorithms into robust counterparts and elevating RE-PO from a single method to a general framework for robust preference alignment. Theoretically, we prove that, under a perfectly calibrated model, RE-PO recovers the true noise level of the dataset. Empirically, we show that RE-PO consistently improves four state-of-the-art alignment methods (DPO, IPO, SimPO, and CPO); when applied to Mistral and Llama 3 models, the RE-PO-enhanced variants increase AlpacaEval 2 win rates by up to 7.0 percent over their respective baselines.