RADAR: A Risk-Aware Dynamic Multi-Agent Framework for LLM Safety Evaluation via Role-Specialized Collaboration
作者: Xiuyuan Chen, Jian Zhao, Yuchen Yuan, Tianle Zhang, Huilin Zhou, Zheng Zhu, Ping Hu, Linghe Kong, Chi Zhang, Weiran Huang, Xuelong Li
分类: cs.AI, cs.CV, cs.LG, cs.MA
发布日期: 2025-09-28 (更新: 2025-10-23)
💡 一句话要点
RADAR:基于角色 специализирана协作的风险感知动态多智能体框架,用于LLM安全评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型安全 风险评估 多智能体系统 角色 специализирана协作 动态更新机制
📋 核心要点
- 现有LLM安全评估方法受评估者偏差和模型同质性影响,导致风险评估鲁棒性不足。
- RADAR框架通过角色 специализирана协作和动态更新机制,实现风险概念分布的自我进化。
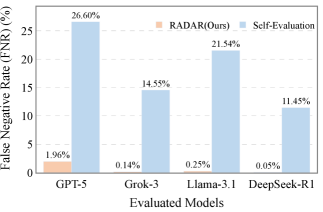
- 实验结果表明,RADAR在风险识别准确率上显著优于基线方法,提升达28.87%。
📝 摘要(中文)
现有的大语言模型(LLM)安全评估方法存在固有局限性,包括评估者偏差和模型同质性导致的检测失败,这些问题共同削弱了风险评估过程的鲁棒性。本文旨在通过引入一个理论框架来重构潜在的风险概念空间,从而重新审视风险评估范式。具体而言,我们将潜在的风险概念空间分解为三个互斥的子空间:显式风险子空间(包含直接违反安全准则的行为)、隐式风险子空间(捕捉需要上下文推理才能识别的潜在恶意内容)和非风险子空间。此外,我们提出了RADAR,一个多智能体协作评估框架,该框架利用通过四个专业互补角色进行的多轮辩论机制,并采用动态更新机制来实现风险概念分布的自我进化。这种方法能够全面覆盖显式和隐式风险,同时减轻评估者偏差。为了验证我们框架的有效性,我们构建了一个包含800个具有挑战性案例的评估数据集。在我们具有挑战性的测试集和公共基准上的大量实验表明,RADAR在准确性、稳定性和自我评估风险敏感性等多个维度上显著优于基线评估方法。值得注意的是,与最强的基线评估方法相比,RADAR在风险识别准确率方面提高了28.87%。
🔬 方法详解
问题定义:论文旨在解决现有大语言模型安全评估方法中存在的评估者偏差和模型同质性问题,这些问题导致风险评估的准确性和鲁棒性不足。现有方法难以有效识别隐式风险,并且容易受到评估者主观判断的影响。
核心思路:论文的核心思路是将风险概念空间分解为显式风险、隐式风险和非风险三个互斥的子空间,并设计一个多智能体协作框架,通过不同角色的智能体进行多轮辩论,从而更全面地覆盖风险空间,减轻评估者偏差。
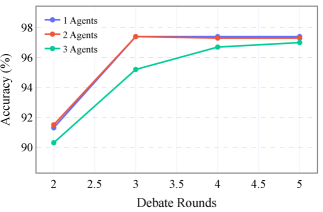
技术框架:RADAR框架包含四个主要角色:风险识别者、风险验证者、风险辩护者和风险仲裁者。风险识别者负责提出潜在的风险;风险验证者负责验证风险的真实性;风险辩护者尝试为模型行为辩护,挑战风险的有效性;风险仲裁者根据辩论结果做出最终判断。框架采用多轮辩论机制,每一轮中各个角色相互交互,动态更新风险概念分布。
关键创新:RADAR的关键创新在于其多智能体协作和角色 специализирана设计。通过不同角色的智能体相互制衡,可以有效减轻评估者偏差,提高风险识别的准确性和全面性。动态更新机制使得框架能够不断学习和适应新的风险模式。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。框架的核心在于角色之间的交互逻辑和辩论机制的设计,以及如何根据辩论结果更新风险概念分布。具体的实现细节可能依赖于所使用的大语言模型和评估数据集。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RADAR框架在风险识别准确率方面显著优于基线评估方法,提升高达28.87%。此外,RADAR在稳定性和自我评估风险敏感性方面也表现出优越性。这些结果验证了RADAR框架在LLM安全评估方面的有效性和优越性。
🎯 应用场景
RADAR框架可应用于大语言模型的安全评估和风险控制,帮助开发者更全面地了解模型的潜在风险,并采取相应的措施进行改进。该框架还可以用于构建更安全的AI系统,减少恶意利用和潜在危害。未来,该方法可以扩展到其他类型的AI模型,提高整体的AI安全性。
📄 摘要(原文)
Existing safety evaluation methods for large language models (LLMs) suffer from inherent limitations, including evaluator bias and detection failures arising from model homogeneity, which collectively undermine the robustness of risk evaluation processes. This paper seeks to re-examine the risk evaluation paradigm by introducing a theoretical framework that reconstructs the underlying risk concept space. Specifically, we decompose the latent risk concept space into three mutually exclusive subspaces: the explicit risk subspace (encompassing direct violations of safety guidelines), the implicit risk subspace (capturing potential malicious content that requires contextual reasoning for identification), and the non-risk subspace. Furthermore, we propose RADAR, a multi-agent collaborative evaluation framework that leverages multi-round debate mechanisms through four specialized complementary roles and employs dynamic update mechanisms to achieve self-evolution of risk concept distributions. This approach enables comprehensive coverage of both explicit and implicit risks while mitigating evaluator bias. To validate the effectiveness of our framework, we construct an evaluation dataset comprising 800 challenging cases. Extensive experiments on our challenging testset and public benchmarks demonstrate that RADAR significantly outperforms baseline evaluation methods across multiple dimensions, including accuracy, stability, and self-evaluation risk sensitivity. Notably, RADAR achieves a 28.87% improvement in risk identification accuracy compared to the strongest baseline evaluation method.