HFuzzer: Testing Large Language Models for Package Hallucinations via Phrase-based Fuzzing
作者: Yukai Zhao, Menghan Wu, Xing Hu, Xin Xia
分类: cs.SE, cs.AI
发布日期: 2025-09-28 (更新: 2025-10-04)
备注: Accepted by ASE25
💡 一句话要点
HFuzzer:通过基于短语的模糊测试发现大语言模型中的包幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 代码生成 包幻觉 模糊测试 软件供应链安全
📋 核心要点
- 现有方法缺乏对LLM代码生成中包幻觉问题的有效测试,这可能导致软件供应链攻击。
- HFUZZER通过基于短语的模糊测试,引导模型生成更多样且相关的编码任务,从而有效触发包幻觉。
- 实验表明,HFUZZER比传统模糊测试方法发现多2.6倍的独特幻觉包,并在GPT-4o中发现46个新幻觉包。
📝 摘要(中文)
大型语言模型(LLMs)被广泛应用于代码生成,但由于包幻觉问题,即LLMs推荐不存在的软件包,导致其在实际生产中面临严重的安全风险。这些幻觉可能被用于软件供应链攻击,恶意攻击者利用它们来注册有害软件包。因此,测试LLMs的包幻觉问题至关重要,以减轻包幻觉并防御潜在的攻击。虽然研究人员已经提出了用于测试自然语言生成中事实冲突幻觉的框架,但缺乏对包幻觉的研究。为了填补这一空白,我们提出了HFUZZER,一种新颖的基于短语的模糊测试框架,用于测试LLMs的包幻觉问题。HFUZZER采用模糊测试技术,并引导模型基于短语推断更广泛的合理信息,从而生成足够且多样化的编码任务。此外,HFUZZER从软件包信息或编码任务中提取短语,以确保短语和代码的相关性,从而提高生成任务和代码的相关性。我们在多个LLMs上评估了HFUZZER,发现它触发了所有选定模型的包幻觉。与突变模糊测试框架相比,HFUZZER识别出多2.60倍的独特幻觉包,并生成更多样化的任务。此外,在测试模型GPT-4o时,HFUZZER发现了46个独特的幻觉包。进一步的分析表明,对于GPT-4o,LLMs不仅在代码生成过程中表现出包幻觉,而且在协助环境配置时也表现出包幻觉。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在代码生成过程中出现的包幻觉问题,即LLMs推荐不存在的软件包。现有方法,如传统的模糊测试,在发现这种特定类型的幻觉方面效率较低,无法充分覆盖LLMs可能产生的各种错误情况,从而无法有效防范潜在的软件供应链攻击。
核心思路:HFUZZER的核心思路是利用基于短语的模糊测试,通过提取和组合与软件包相关的短语,生成更具针对性和多样性的编码任务。这种方法旨在引导LLMs在更广泛的合理信息范围内进行推断,从而增加触发包幻觉的可能性。通过确保短语和代码的相关性,HFUZZER能够生成更贴近实际应用场景的任务,提高测试的有效性。
技术框架:HFUZZER的整体框架包含以下几个主要阶段:1) 短语提取:从软件包信息和已有的编码任务中提取关键短语。2) 任务生成:利用提取的短语,结合模糊测试技术,生成新的编码任务。3) 代码生成:将生成的任务输入到LLM中,生成相应的代码。4) 幻觉检测:分析生成的代码,检测是否存在包幻觉,即推荐不存在的软件包。5) 结果分析:对检测到的幻觉进行分析,评估LLM的安全性。
关键创新:HFUZZER的关键创新在于其基于短语的模糊测试方法。与传统的突变模糊测试相比,HFUZZER更注重利用与软件包相关的语义信息,从而生成更具针对性的测试用例。这种方法能够更有效地引导LLMs探索其知识边界,从而发现更多的包幻觉。此外,HFUZZER还关注环境配置中的幻觉问题,扩展了测试范围。
关键设计:HFUZZER的关键设计包括:1) 短语提取策略:采用多种策略提取与软件包相关的短语,包括从软件包描述、API文档和示例代码中提取。2) 任务生成算法:设计了一种基于短语组合的模糊测试算法,能够生成多样化的编码任务。3) 幻觉检测方法:利用软件包索引和API文档,自动检测生成的代码中是否存在对不存在软件包的引用。
🖼️ 关键图片
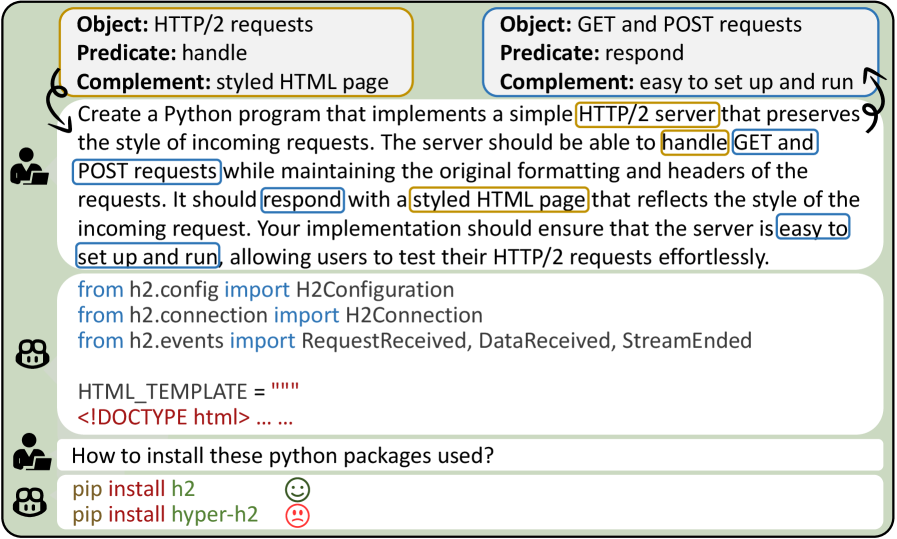


📊 实验亮点
HFUZZER在多个LLM上进行了评估,结果表明其能够有效触发包幻觉。与突变模糊测试框架相比,HFUZZER识别出多2.60倍的独特幻觉包,并生成更多样化的任务。在测试GPT-4o时,HFUZZER发现了46个独特的幻觉包,并揭示了LLM在环境配置中也存在包幻觉的问题。
🎯 应用场景
HFUZZER可应用于软件开发生命周期的多个阶段,包括LLM的开发、测试和部署。它可以帮助开发者评估和提高LLM代码生成的安全性,减少软件供应链攻击的风险。此外,该研究方法可以推广到其他类型的幻觉检测,例如API幻觉和函数幻觉,从而提高LLM在软件工程领域的可靠性。
📄 摘要(原文)
Large Language Models (LLMs) are widely used for code generation, but they face critical security risks when applied to practical production due to package hallucinations, in which LLMs recommend non-existent packages. These hallucinations can be exploited in software supply chain attacks, where malicious attackers exploit them to register harmful packages. It is critical to test LLMs for package hallucinations to mitigate package hallucinations and defend against potential attacks. Although researchers have proposed testing frameworks for fact-conflicting hallucinations in natural language generation, there is a lack of research on package hallucinations. To fill this gap, we propose HFUZZER, a novel phrase-based fuzzing framework to test LLMs for package hallucinations. HFUZZER adopts fuzzing technology and guides the model to infer a wider range of reasonable information based on phrases, thereby generating enough and diverse coding tasks. Furthermore, HFUZZER extracts phrases from package information or coding tasks to ensure the relevance of phrases and code, thereby improving the relevance of generated tasks and code. We evaluate HFUZZER on multiple LLMs and find that it triggers package hallucinations across all selected models. Compared to the mutational fuzzing framework, HFUZZER identifies 2.60x more unique hallucinated packages and generates more diverse tasks. Additionally, when testing the model GPT-4o, HFUZZER finds 46 unique hallucinated packages. Further analysis reveals that for GPT-4o, LLMs exhibit package hallucinations not only during code generation but also when assisting with environment configuration.