EAPO: Enhancing Policy Optimization with On-Demand Expert Assistance
作者: Siyao Song, Cong Ma, Zhihao Cheng, Shiye Lei, Minghao Li, Ying Zeng, Huaixiao Tou, Kai Jia
分类: cs.AI
发布日期: 2025-09-28
💡 一句话要点
EAPO:通过按需专家辅助增强策略优化,提升LLM推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 策略优化 专家辅助 大型语言模型 数学推理
📋 核心要点
- 现有方法依赖于基于结果的监督来强化LLM内部推理,导致探索效率低下和奖励稀疏。
- EAPO通过引入与外部专家的多轮交互,激励策略自适应地决定何时以及如何咨询专家,从而丰富奖励信号。
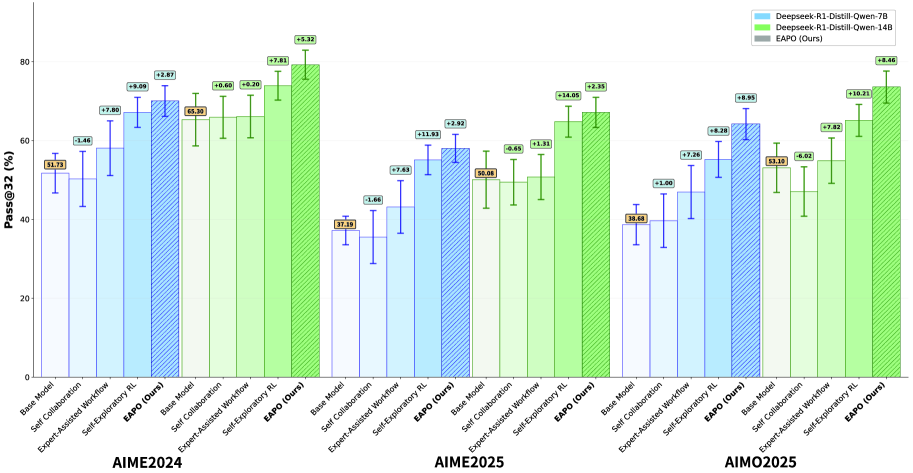
- 实验表明,EAPO在数学推理基准测试中始终优于其他方法,平均比自我探索模型高出5分。
📝 摘要(中文)
本文提出了一种名为专家辅助策略优化(EAPO)的新型强化学习框架,旨在通过在训练期间引入与外部专家的多轮交互来增强探索,从而优化大型语言模型(LLM)在可验证奖励下的推理能力。与现有方法中策略孤立推理不同,EAPO激励策略自适应地决定何时以及如何咨询专家,从而产生更丰富的奖励信号和更可靠的推理轨迹。外部辅助最终将专家知识内化到策略模型中,从而增强模型固有的推理能力。评估表明,经过良好优化的策略模型能够独立解决问题,产生改进的推理路径和更准确的解决方案。在AIME 2024、AIME 2025和AIMO 2025等数学推理基准上的实验表明,EAPO始终优于专家辅助工作流程、专家提炼模型和强化学习基线,平均比自我探索模型高出5分。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在强化学习优化推理能力时,由于探索效率低下和奖励稀疏导致的学习困难问题。现有方法主要依赖于基于结果的监督,缺乏有效的探索机制,难以充分利用专家知识。
核心思路:EAPO的核心思路是让策略模型在训练过程中能够按需向外部专家寻求帮助,通过专家指导来丰富奖励信号,从而更有效地探索和学习。这种方式将专家知识内化到策略模型中,提升其独立推理能力。
技术框架:EAPO框架包含策略模型和外部专家两个主要组成部分。训练过程中,策略模型在每个步骤决定是否需要咨询专家。如果需要,策略模型将当前状态信息发送给专家,专家提供相应的指导或建议。策略模型根据专家的反馈和最终结果获得奖励,并利用强化学习算法进行优化。整体流程是一个策略模型与专家交互,并根据交互结果进行学习的循环。
关键创新:EAPO的关键创新在于引入了按需专家辅助机制。与传统的专家蒸馏或专家辅助工作流不同,EAPO允许策略模型自主决定何时以及如何利用专家资源,从而实现更灵活和高效的学习。这种自适应的专家辅助方式能够更好地将专家知识融入到策略模型中。
关键设计:EAPO的关键设计包括:1) 策略模型需要学习一个决策函数,用于判断是否需要咨询专家;2) 定义合适的奖励函数,鼓励策略模型在需要时寻求专家帮助,并根据专家的反馈进行学习;3) 设计有效的专家交互协议,确保专家能够提供有用的指导信息。具体的网络结构和损失函数选择取决于具体的应用场景。
🖼️ 关键图片


📊 实验亮点
EAPO在AIME 2024、AIME 2025和AIMO 2025等数学推理基准测试中取得了显著的性能提升。实验结果表明,EAPO始终优于专家辅助工作流程、专家提炼模型和强化学习基线,平均比自我探索模型高出5分。这些结果表明,EAPO能够有效地利用专家知识,提升LLM的推理能力。
🎯 应用场景
EAPO具有广泛的应用前景,可以应用于各种需要复杂推理和决策的任务中,例如数学问题求解、代码生成、游戏AI等。通过引入专家辅助,EAPO可以显著提升LLM在这些任务中的性能,并降低对大量标注数据的依赖。未来,EAPO还可以扩展到其他领域,例如医疗诊断、金融分析等,为这些领域提供更智能的解决方案。
📄 摘要(原文)
Large language models (LLMs) have recently advanced in reasoning when optimized with reinforcement learning (RL) under verifiable rewards. Existing methods primarily rely on outcome-based supervision to strengthen internal LLM reasoning, often leading to inefficient exploration and sparse rewards. To mitigate this issue, we propose Expert-Assisted Policy Optimization (EAPO), a novel RL framework that enhances exploration by incorporating multi-turn interactions with external experts during training. Unlike prior methods, where policies reason in isolation, EAPO incentivizes the policy to adaptively determine when and how to consult experts, yielding richer reward signals and more reliable reasoning trajectories. External assistance ultimately internalizes expert knowledge into the policy model, amplifying the model's inherent reasoning capabilities. During evaluation, the policy model has been well-optimized to solve questions independently, producing improved reasoning paths and more accurate solutions. Experiments on mathematical reasoning benchmarks, including AIME 2024, AIME 2025, and AIMO 2025, show that EAPO consistently outperforms expert-assisted workflow, expert-distilled models, and RL baselines, with an average gain of 5 points over self-exploratory models.