AdaPtis: Reducing Pipeline Bubbles with Adaptive Pipeline Parallelism on Heterogeneous Models
作者: Jihu Guo, Tenghui Ma, Wei Gao, Peng Sun, Jiaxing Li, Xun Chen, Yuyang Jin, Dahua Lin
分类: cs.DC, cs.AI
发布日期: 2025-09-28
备注: 13 pages, 15 Figures; Under Review;
💡 一句话要点
AdaPtis:通过异构模型上的自适应流水线并行减少流水线气泡
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 流水线并行 大型语言模型 异构模型 模型训练 性能优化
📋 核心要点
- 现有流水线并行训练方法在异构模型架构下存在流水线气泡问题,导致训练效率降低。
- AdaPtis通过联合优化模型划分、模型放置和工作负载调度策略,自适应地调整流水线并行策略。
- 实验结果表明,AdaPtis在多种LLM架构和规模下,相比Megatron-LM I-1F1B实现了显著的加速。
📝 摘要(中文)
流水线并行被广泛应用于训练大型语言模型(LLMs)。然而,模型架构日益增长的异构性加剧了流水线气泡,从而降低了训练效率。现有方法忽略了模型划分、模型放置和工作负载调度的协同优化,导致效率提升有限甚至性能下降。为了解决这个问题,我们提出了AdaPtis,一个支持自适应流水线并行的LLM训练系统。首先,我们开发了一个流水线性能模型,以准确估计训练吞吐量。其次,AdaPtis在性能模型的指导下,联合优化模型划分、模型放置和工作负载调度策略。第三,我们设计了一个统一的流水线执行器,有效地支持各种流水线策略的执行。大量实验表明,在各种LLM架构和规模下,AdaPtis相对于Megatron-LM I-1F1B实现了平均1.42倍(最高2.14倍)的加速。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)训练中,由于模型架构异构性导致的流水线气泡问题。现有方法通常独立地考虑模型划分、模型放置和工作负载调度,无法充分利用异构硬件资源,导致训练效率低下,甚至可能出现性能下降。
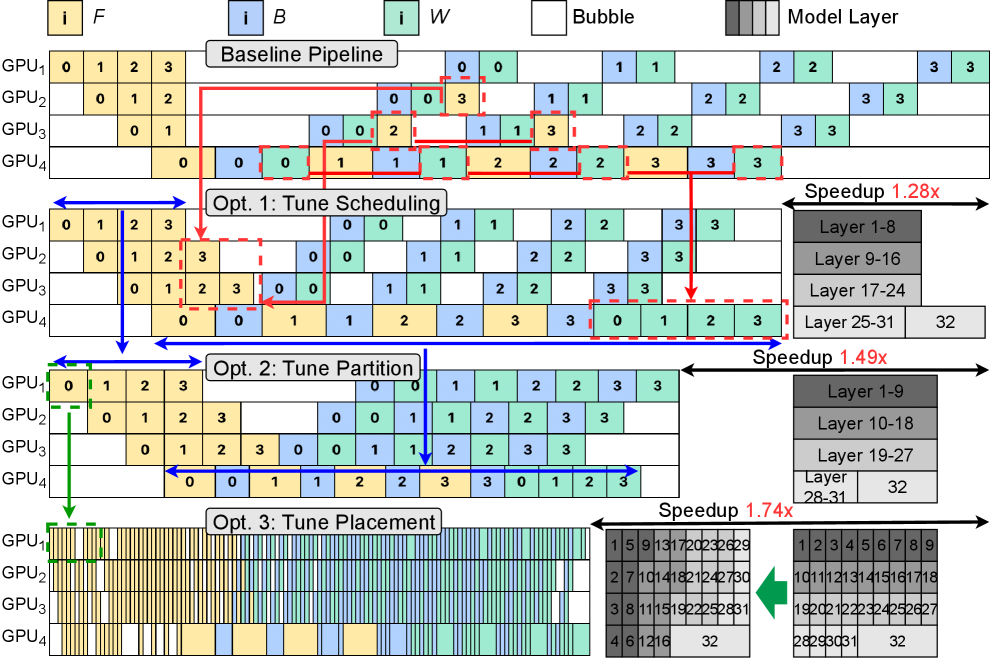
核心思路:AdaPtis的核心思路是协同优化模型划分、模型放置和工作负载调度,以最小化流水线气泡。通过建立精确的流水线性能模型,预测不同策略下的训练吞吐量,并以此为指导进行联合优化。这种协同优化能够更好地适应异构模型架构和硬件环境,从而提高训练效率。
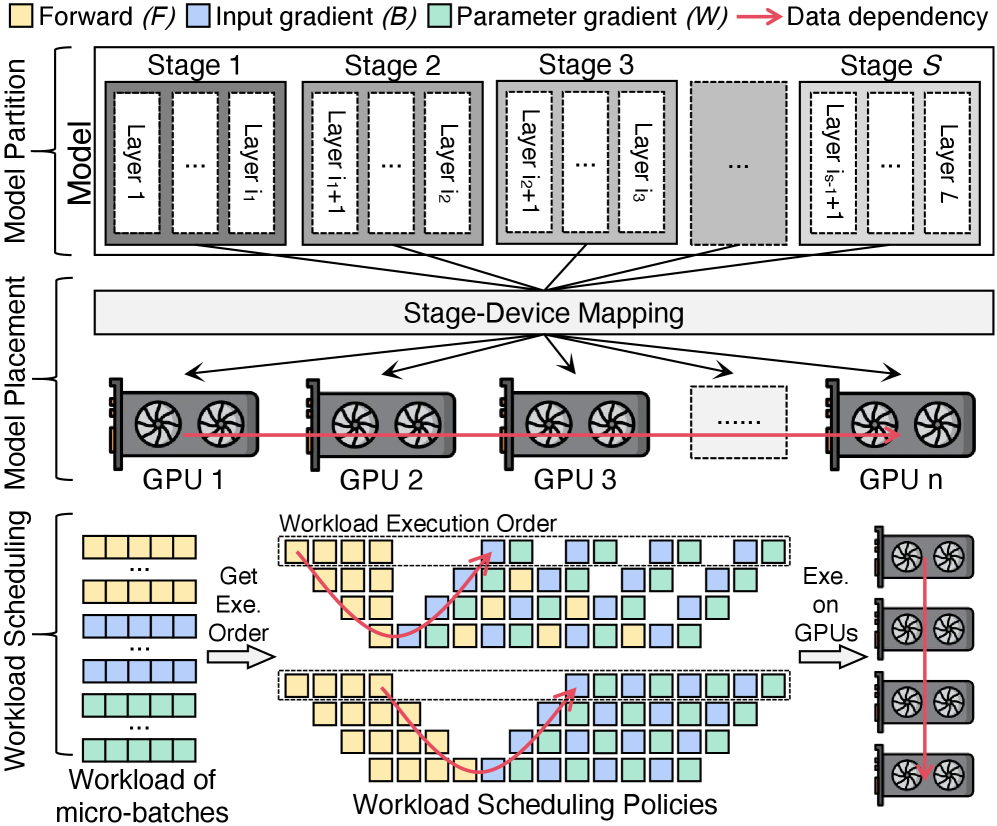
技术框架:AdaPtis包含三个主要模块:1) 流水线性能模型:用于准确估计不同流水线策略下的训练吞吐量。该模型考虑了模型架构、硬件资源和通信开销等因素。2) 联合优化器:基于流水线性能模型,联合优化模型划分、模型放置和工作负载调度策略。优化目标是最大化训练吞吐量。3) 统一流水线执行器:支持各种流水线策略的执行,并能够动态地调整执行计划以适应不同的硬件环境。
关键创新:AdaPtis的关键创新在于其联合优化方法和流水线性能模型。与现有方法相比,AdaPtis能够同时考虑模型划分、模型放置和工作负载调度,从而找到更优的流水线策略。流水线性能模型能够准确预测不同策略下的训练吞吐量,为联合优化提供可靠的依据。
关键设计:流水线性能模型的设计需要考虑多种因素,包括模型各层的计算复杂度、硬件设备的计算能力、以及数据传输的带宽等。联合优化器通常采用搜索算法,例如遗传算法或强化学习,以寻找最优的策略组合。统一流水线执行器需要支持不同的数据并行和模型并行策略,并能够动态地调整执行计划以适应不同的硬件环境。
🖼️ 关键图片
📊 实验亮点
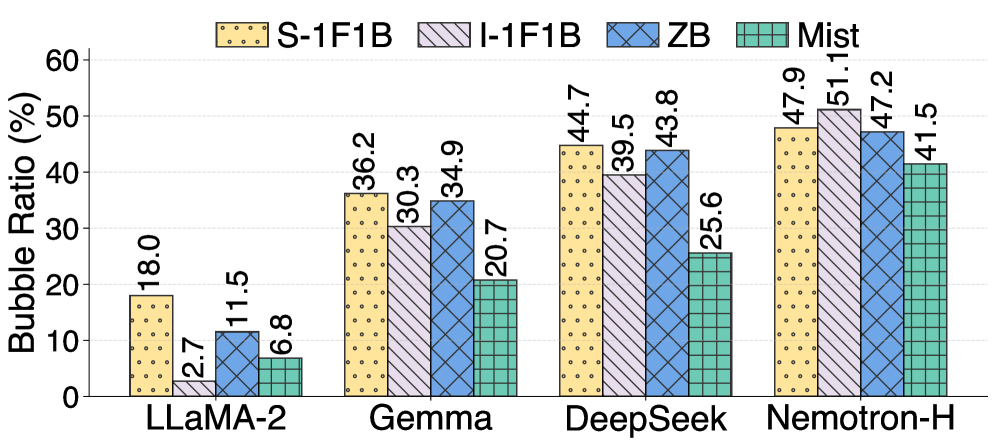
实验结果表明,AdaPtis在各种LLM架构和规模下,相对于Megatron-LM I-1F1B实现了平均1.42倍的加速,最高可达2.14倍。这些结果证明了AdaPtis在提高流水线并行训练效率方面的有效性。实验涵盖了多种LLM架构,验证了AdaPtis的通用性和适应性。
🎯 应用场景
AdaPtis可应用于各种需要大规模模型训练的领域,如自然语言处理、计算机视觉和推荐系统。通过提高训练效率,AdaPtis能够加速新模型的开发和部署,降低训练成本,并促进人工智能技术的广泛应用。尤其是在资源受限的环境下,AdaPtis的优势更加明显。
📄 摘要(原文)
Pipeline parallelism is widely used to train large language models (LLMs). However, increasing heterogeneity in model architectures exacerbates pipeline bubbles, thereby reducing training efficiency. Existing approaches overlook the co-optimization of model partition, model placement, and workload scheduling, resulting in limited efficiency improvement or even performance degradation. To respond, we propose AdaPtis, an LLM training system that supports adaptive pipeline parallelism. First, we develop a pipeline performance model to accurately estimate training throughput. Second, AdaPtis jointly optimizes model partition, model placement, and workload scheduling policies guided by this performance model. Third, we design a unified pipeline executor that efficiently supports the execution of diverse pipeline strategies. Extensive experiments show that AdaPtis achieves an average speedup of 1.42x (up to 2.14x) over Megatron-LM I-1F1B across various LLM architectures and scales.