How LLMs Learn to Reason: A Complex Network Perspective
作者: Sihan Hu, Xiansheng Cai, Yuan Huang, Zhiyuan Yao, Linfeng Zhang, Pan Zhang, Youjin Deng, Kun Chen
分类: cs.AI, cond-mat.dis-nn, cond-mat.stat-mech, cs.LG, physics.soc-ph
发布日期: 2025-09-28 (更新: 2025-11-21)
备注: 24 pages, 11 figures, 1 table, under review as a conference paper at ICLR 2026
💡 一句话要点
提出Annealed-RLVR算法,通过调控概念网络拓扑结构提升LLM推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 概念网络 推理能力 灾难性遗忘 拓扑结构 自组织 RLVR
📋 核心要点
- 现有RLVR训练LLM方法存在双阶段学习、V型轨迹和灾难性遗忘等问题,缺乏有效解释。
- 论文提出概念网络模型CoNet,揭示LLM推理能力与语义空间中概念网络的拓扑结构演化密切相关。
- 提出Annealed-RLVR算法,通过调控概念网络拓扑结构,在多个基准测试中超越标准RLVR。
📝 摘要(中文)
本文研究了使用可验证奖励的强化学习(RLVR)训练大型语言模型(LLM)时出现的一系列独特且令人困惑的行为,包括双阶段学习曲线、V型响应长度轨迹以及对灾难性遗忘的显著脆弱性。我们提出这些行为是由语义空间中潜在推理图的拓扑演化所支配的涌现集体现象,而非神经实现的细节。通过论证一个15亿参数的LLM和一个最小概念网络模型(CoNet)之间的动态同构性,我们将因果源追溯到固定在平均度数为2的稀疏概念网络的自组织。这种几何视角为观察到的异常现象提供了一个统一的物理学解释:V型轨迹跟踪了从并行局部技能优化到全局网络集成的演变;灾难性遗忘源于关键“主干”边的拓扑断开;策略崩溃源于网络叶节点上顺序转换的积累,在这些节点上,广泛的探索突然冻结为刚性的、高奖励的轨迹。通过识别学习阶段之间转换时的“最大受挫状态”,我们提出了一种基于原则的算法Annealed-RLVR,该算法注入一个有针对性的SFT“加热”步骤来解决这个拓扑瓶颈。实验证实,这种理论驱动的干预在分布内和分布外基准测试(包括Minerva和AIME)上均优于标准RLVR。通过将RLVR从黑盒优化重塑为结构自组织的可预测过程,我们的工作为设计未来AI系统的涌现推理能力提供了一种新的物理直觉。
🔬 方法详解
问题定义:现有基于RLVR训练LLM的方法,在提升模型推理能力的同时,会产生一些难以解释的现象,如双阶段学习曲线、V型响应长度轨迹以及灾难性遗忘。这些现象表明,模型的学习过程并非简单的优化,而是涉及更复杂的机制。现有方法缺乏对这些现象的深入理解,难以有效控制模型的学习过程。
核心思路:论文的核心思路是将LLM的推理过程视为语义空间中概念网络的演化。通过构建概念网络模型(CoNet),将LLM的学习过程映射到网络拓扑结构的自组织过程。认为这些现象是概念网络拓扑结构演化的结果,例如,灾难性遗忘是由于关键连接的断裂导致的。
技术框架:论文构建了一个概念网络模型(CoNet),该模型模拟了LLM在RLVR训练过程中的行为。CoNet通过强化学习进行训练,目标是构建一个稀疏的概念网络,其中节点代表概念,边代表概念之间的关系。论文还提出了Annealed-RLVR算法,该算法在RLVR训练过程中引入了一个“加热”步骤,通过有针对性的SFT来调整概念网络的拓扑结构。
关键创新:论文的关键创新在于将LLM的推理过程与概念网络的拓扑结构联系起来,提供了一种新的视角来理解LLM的学习过程。通过这种视角,可以更好地理解RLVR训练中出现的各种现象,并设计更有效的训练方法。Annealed-RLVR算法是基于这种理解而提出的,它通过调控概念网络的拓扑结构来提升LLM的推理能力。
关键设计:Annealed-RLVR算法的关键设计在于“加热”步骤,该步骤通过SFT来调整概念网络的拓扑结构。具体来说,该步骤旨在解决学习阶段之间转换时的“最大受挫状态”,通过增加网络的连接性来促进全局网络集成。算法的具体实现细节包括SFT的训练数据选择、训练强度以及何时进行“加热”等。
🖼️ 关键图片
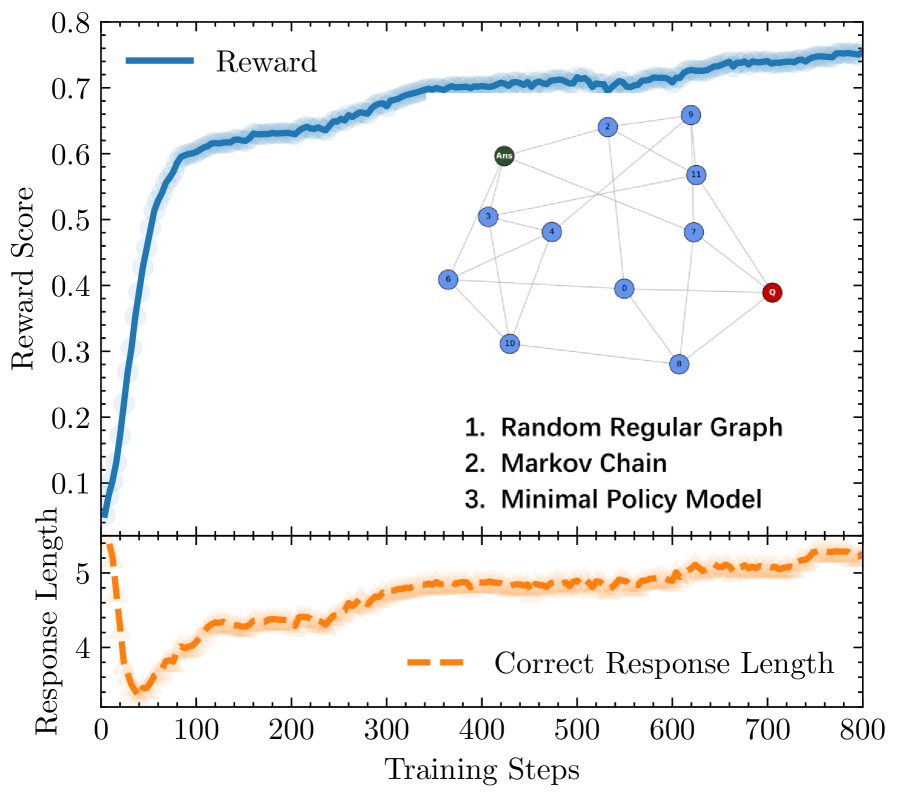
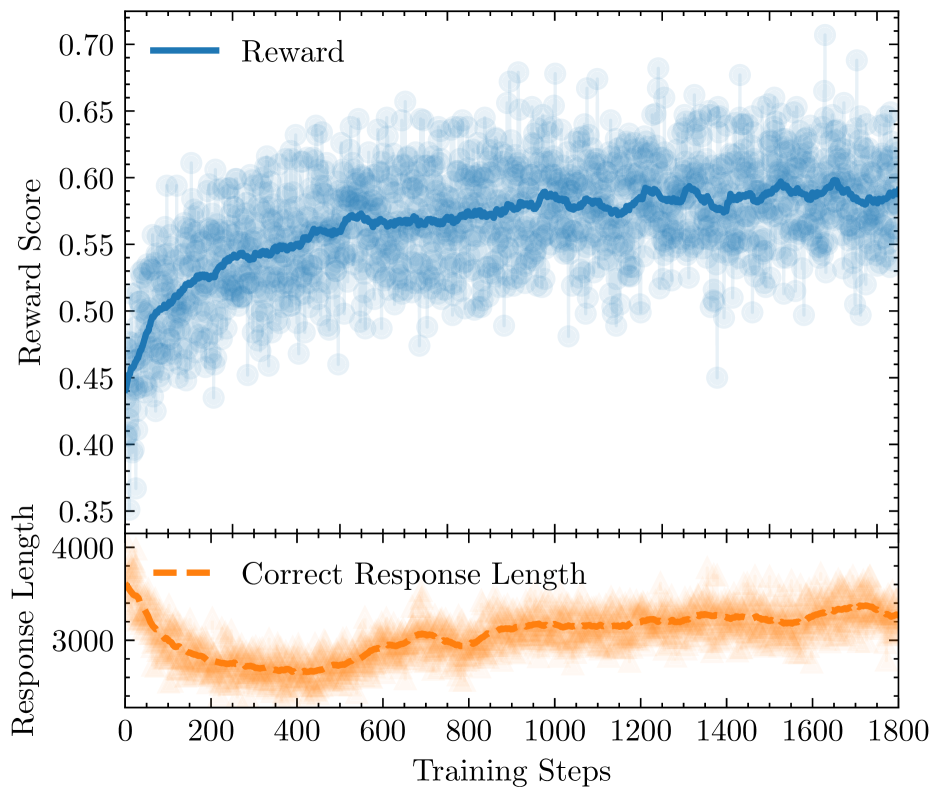
📊 实验亮点
实验结果表明,Annealed-RLVR算法在多个基准测试中优于标准RLVR,包括Minerva和AIME等具有挑战性的数据集。这些结果表明,通过调控概念网络的拓扑结构,可以有效提升LLM的推理能力。具体的性能提升数据在论文中给出,证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于提升大型语言模型的推理能力和鲁棒性,尤其是在需要复杂推理和知识整合的任务中。通过理解和控制概念网络的拓扑结构,可以更好地优化LLM的训练过程,减少灾难性遗忘,并提高模型在分布外数据上的泛化能力。这对于开发更可靠、更智能的AI系统具有重要意义。
📄 摘要(原文)
Training large language models with Reinforcement Learning with Verifiable Rewards (RLVR) exhibits a set of distinctive and puzzling behaviors that remain poorly understood, including a two-stage learning curve, a V-shaped response-length trajectory, and a pronounced vulnerability to catastrophic forgetting. In this work, we propose that these behaviors are emergent collective phenomena governed not by neural implementation details, but by the topological evolution of the latent reasoning graph in semantic space. By demonstrating a dynamical isomorphism between a 1.5B-parameter LLM and a minimal Concept Network Model (CoNet), we trace the causal source to the self-organization of a sparse concept web pinned to an average degree of two. This geometric perspective provides a unified physical explanation for the observed anomalies: the V-shaped trajectory tracks the evolution from parallel local skill optimization to global network integration; catastrophic forgetting stems from the topological disconnection of critical
trunk'' edges; and policy collapse arises from the accumulation of sequential transitions at the web's leaf nodes, where broad exploration abruptly freezes into rigid, high-reward trajectories. Identifying amaximally frustrated state'' at the transition between learning stages, we propose Annealed-RLVR, a principled algorithm that injects a targeted SFT ``heating'' step to resolve this topological bottleneck. Experiments confirm that this theory-driven intervention outperforms standard RLVR on both in-distribution and out-of-distribution benchmarks (including Minerva and AIME). By recasting RLVR from black-box optimization into a predictable process of structural self-organization, our work provides a new physical intuition for engineering the emergent reasoning capabilities of future AI systems.