Uncovering Vulnerabilities of LLM-Assisted Cyber Threat Intelligence
作者: Yuqiao Meng, Luoxi Tang, Feiyang Yu, Jinyuan Jia, Guanhua Yan, Ping Yang, Zhaohan Xi
分类: cs.CR, cs.AI
发布日期: 2025-09-28 (更新: 2025-10-01)
💡 一句话要点
揭示LLM辅助网络威胁情报的脆弱性以提升安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 网络威胁情报 大型语言模型 脆弱性分析 安全分析 机器学习
📋 核心要点
- 现有LLM在网络威胁情报中的应用存在显著性能差距,尤其在实际部署中面临多种挑战。
- 论文提出了一种新颖的分类方法,结合分层、自动回归细化和人机协作监督,以分析LLM的失败实例。
- 通过实验发现LLM在CTI中存在三种脆弱性,提供了针对这些问题的设计建议,以提升系统的鲁棒性。
📝 摘要(中文)
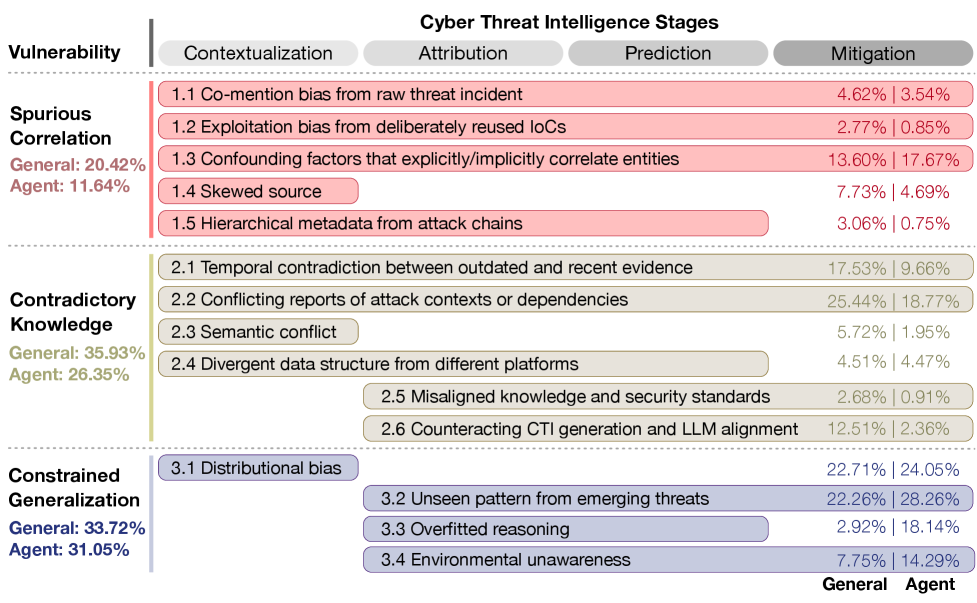
大型语言模型(LLMs)被广泛用于协助安全分析师应对网络威胁的快速利用,提供网络威胁情报(CTI)以支持漏洞评估和事件响应。尽管LLMs在威胁分析、漏洞检测和入侵防御等CTI任务中表现出色,但在实际应用中仍存在显著的性能差距。本文探讨了LLMs在CTI中的内在脆弱性,重点关注来自威胁环境本质的挑战。通过对多个CTI基准和真实威胁报告的大规模评估,提出了一种新颖的分类方法,结合分层、自动回归细化和人机协作监督,以可靠分析失败实例。通过广泛的实验和人工检查,揭示了三种基本脆弱性:虚假相关、矛盾知识和受限泛化,这些限制了LLMs在有效支持CTI方面的能力。最后,提供了设计更强健的LLM驱动CTI系统的可行见解,以促进未来研究。
🔬 方法详解
问题定义:本文旨在解决LLM在网络威胁情报(CTI)应用中的内在脆弱性,现有方法在面对复杂威胁环境时表现不佳,导致性能不足。
核心思路:通过引入分层、自动回归细化和人机协作监督的分类方法,论文旨在深入分析LLM在CTI任务中的失败案例,从而识别并解决其脆弱性。
技术框架:整体架构包括数据收集、模型评估、失败实例分析和设计建议四个主要模块。首先收集多个CTI基准和真实威胁报告,然后对LLM进行评估,接着分析失败实例,最后提出改进建议。
关键创新:论文的主要创新在于提出了一种综合性的分类方法,能够有效识别LLM在CTI中的三种基本脆弱性:虚假相关、矛盾知识和受限泛化,这些都是现有方法未能充分考虑的因素。
关键设计:在实验中,采用了多种参数设置和损失函数,以确保模型在不同CTI任务中的适应性和鲁棒性,同时引入人机协作监督以增强分析的准确性。
🖼️ 关键图片


📊 实验亮点
实验结果显示,LLM在CTI任务中存在显著的脆弱性,尤其是在虚假相关和矛盾知识方面。通过新提出的分类方法,识别出这些问题后,系统的鲁棒性得到了显著提升,具体性能提升幅度未知。
🎯 应用场景
该研究的潜在应用领域包括网络安全、威胁检测和应急响应等。通过揭示LLM在CTI中的脆弱性,研究为设计更强健的安全系统提供了理论基础,未来可望在实际网络防护中发挥重要作用。
📄 摘要(原文)
Large Language Models (LLMs) are intensively used to assist security analysts in counteracting the rapid exploitation of cyber threats, wherein LLMs offer cyber threat intelligence (CTI) to support vulnerability assessment and incident response. While recent work has shown that LLMs can support a wide range of CTI tasks such as threat analysis, vulnerability detection, and intrusion defense, significant performance gaps persist in practical deployments. In this paper, we investigate the intrinsic vulnerabilities of LLMs in CTI, focusing on challenges that arise from the nature of the threat landscape itself rather than the model architecture. Using large-scale evaluations across multiple CTI benchmarks and real-world threat reports, we introduce a novel categorization methodology that integrates stratification, autoregressive refinement, and human-in-the-loop supervision to reliably analyze failure instances. Through extensive experiments and human inspections, we reveal three fundamental vulnerabilities: spurious correlations, contradictory knowledge, and constrained generalization, that limit LLMs in effectively supporting CTI. Subsequently, we provide actionable insights for designing more robust LLM-powered CTI systems to facilitate future research.