Benchmarking LLM-Assisted Blue Teaming via Standardized Threat Hunting
作者: Yuqiao Meng, Luoxi Tang, Feiyang Yu, Xi Li, Guanhua Yan, Ping Yang, Zhaohan Xi
分类: cs.CR, cs.AI
发布日期: 2025-09-28 (更新: 2025-10-01)
💡 一句话要点
CyberTeam:通过标准化威胁狩猎评估LLM辅助蓝队防御能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 威胁狩猎 蓝队防御 网络安全 标准化基准
📋 核心要点
- 现有蓝队防御在面对日益复杂和大规模的网络威胁时,缺乏有效利用LLM进行威胁狩猎的标准化方法。
- CyberTeam通过构建标准化威胁狩猎工作流程,将威胁分析分解为模块化步骤,引导LLM执行任务。
- 实验结果表明,CyberTeam的标准化设计能够有效提升LLM在威胁狩猎任务中的表现,优于开放式推理策略。
📝 摘要(中文)
随着网络威胁规模和复杂性的不断增长,蓝队防御者越来越需要先进的工具来主动检测和缓解风险。大型语言模型(LLM)在增强威胁分析方面展现出巨大的潜力。然而,它们在真实蓝队威胁狩猎场景中的有效性尚未得到充分探索。本文提出了CyberTeam,一个旨在指导LLM进行蓝队实践的基准。CyberTeam构建了一个包含两个阶段的标准化工作流程。首先,它通过捕获从威胁归因到事件响应的分析任务之间的依赖关系来模拟真实的威胁狩猎工作流程。其次,每个任务都通过一组根据其特定分析需求量身定制的操作模块来解决。这会将威胁狩猎转换为一个结构化的推理步骤序列,每个步骤都基于一个离散操作,并根据特定于任务的依赖关系进行排序。在该框架的指导下,LLM被引导通过模块化步骤执行威胁狩猎任务。总体而言,CyberTeam集成了30个任务和9个操作模块,以指导LLM完成标准化威胁分析。我们评估了领先的LLM和最先进的网络安全代理,并将CyberTeam与开放式推理策略进行比较。我们的结果突出了标准化设计带来的改进,同时也揭示了开放式推理在真实威胁狩猎中的局限性。
🔬 方法详解
问题定义:论文旨在解决如何有效利用大型语言模型(LLM)辅助蓝队进行威胁狩猎的问题。现有方法主要依赖于开放式的推理,缺乏结构化指导,导致LLM在复杂威胁场景下的表现不稳定,难以复现和评估。现有方法的痛点在于无法将复杂的威胁狩猎任务分解为可控的、可解释的步骤,从而限制了LLM的应用效果。
核心思路:论文的核心思路是将威胁狩猎过程分解为一系列标准化的任务和操作模块,构建一个结构化的工作流程。通过明确任务之间的依赖关系,并为每个任务设计特定的操作模块,引导LLM逐步完成威胁分析。这种模块化的方法使得LLM的推理过程更加可控和可解释,同时也方便了性能评估和优化。
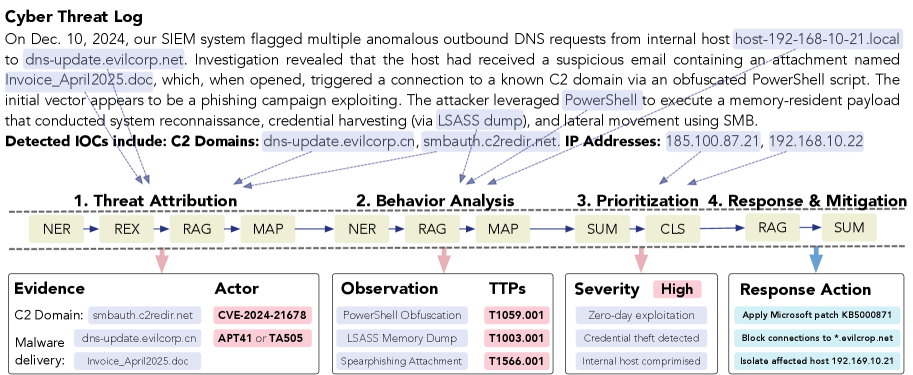
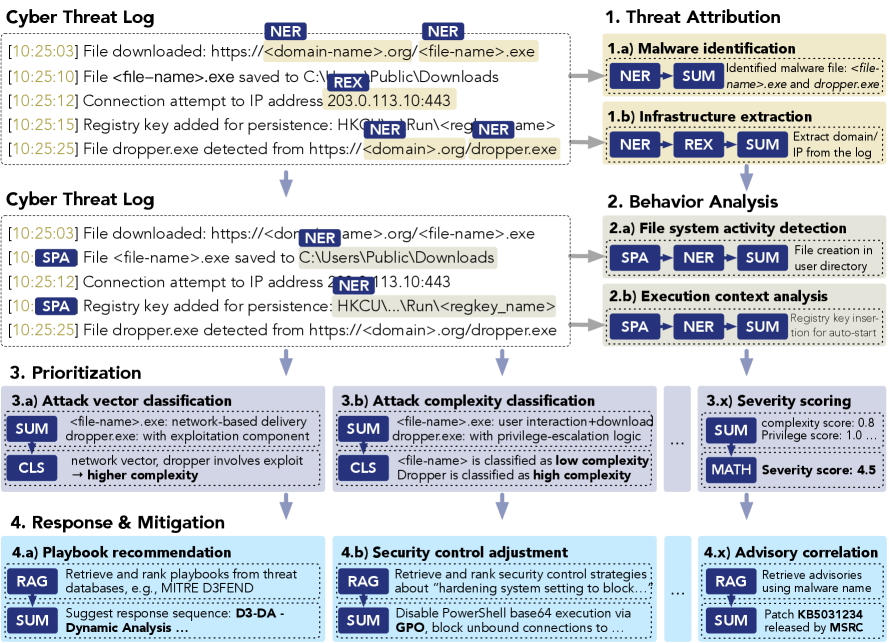
技术框架:CyberTeam框架包含两个主要阶段:威胁狩猎工作流程建模和模块化操作。首先,通过分析真实的威胁狩猎场景,提取出30个关键任务,并建立这些任务之间的依赖关系。然后,为每个任务设计一组操作模块,这些模块包含了执行该任务所需的具体操作,例如数据查询、日志分析、恶意代码检测等。LLM在CyberTeam的指导下,按照任务依赖关系依次执行相应的操作模块,完成整个威胁狩猎过程。框架集成了30个任务和9个操作模块。
关键创新:论文最重要的技术创新点在于提出了一个标准化的、模块化的威胁狩猎框架,将复杂的威胁分析任务分解为一系列可控的步骤。与传统的开放式推理方法相比,CyberTeam能够更好地引导LLM进行推理,提高威胁狩猎的效率和准确性。此外,CyberTeam作为一个基准,也为评估和比较不同LLM在威胁狩猎任务中的表现提供了一个统一的标准。
关键设计:CyberTeam的关键设计在于任务依赖关系的建模和操作模块的构建。任务依赖关系决定了LLM执行任务的顺序,而操作模块则定义了每个任务的具体执行方式。论文通过分析真实的威胁狩猎案例,人工构建了任务依赖关系图,并为每个任务设计了相应的操作模块。这些操作模块涵盖了各种常用的威胁分析技术,例如正则表达式匹配、YARA规则检测、网络流量分析等。具体参数设置和损失函数等细节未在摘要中提及,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CyberTeam的标准化设计能够显著提升LLM在威胁狩猎任务中的表现。与开放式推理策略相比,CyberTeam能够更有效地引导LLM进行推理,提高威胁检测的准确率和效率。具体的性能数据和提升幅度在摘要中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于提升企业和机构的网络安全防御能力,通过LLM辅助蓝队进行更高效、更准确的威胁狩猎。CyberTeam作为一个基准,可以促进LLM在网络安全领域的应用研究,推动开发更智能化的安全工具。未来,该框架可以扩展到更广泛的安全领域,例如漏洞挖掘、入侵检测等。
📄 摘要(原文)
As cyber threats continue to grow in scale and sophistication, blue team defenders increasingly require advanced tools to proactively detect and mitigate risks. Large Language Models (LLMs) offer promising capabilities for enhancing threat analysis. However, their effectiveness in real-world blue team threat-hunting scenarios remains insufficiently explored. This paper presents CyberTeam, a benchmark designed to guide LLMs in blue teaming practice. CyberTeam constructs a standardized workflow in two stages. First, it models realistic threat-hunting workflows by capturing the dependencies among analytical tasks from threat attribution to incident response. Next, each task is addressed through a set of operational modules tailored to its specific analytical requirements. This transforms threat hunting into a structured sequence of reasoning steps, with each step grounded in a discrete operation and ordered according to task-specific dependencies. Guided by this framework, LLMs are directed to perform threat-hunting tasks through modularized steps. Overall, CyberTeam integrates 30 tasks and 9 operational modules to guide LLMs through standardized threat analysis. We evaluate both leading LLMs and state-of-the-art cybersecurity agents, comparing CyberTeam against open-ended reasoning strategies. Our results highlight the improvements enabled by standardized design, while also revealing the limitations of open-ended reasoning in real-world threat hunting.