Your Dense Retriever is Secretly an Expeditious Reasoner
作者: Yichi Zhang, Jun Bai, Zhixin Cai, Shuhan Qin, Zhuofan Chen, Jinghua Guan, Wenge Rong
分类: cs.IR, cs.AI, cs.LG
发布日期: 2025-09-27 (更新: 2025-10-28)
备注: 16 pages, 11 figures
💡 一句话要点
提出AdaQR,自适应混合查询重写框架,提升推理检索效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稠密检索 查询重写 大型语言模型 自适应推理 混合框架
📋 核心要点
- 稠密检索器在处理复杂推理查询时面临挑战,计算成本高昂。
- AdaQR框架通过Reasoner Router动态选择稠密推理或LLM推理,实现效率与准确率的平衡。
- 实验表明,AdaQR在BRIGHT基准测试中降低了28%的推理成本,并提升了7%的检索性能。
📝 摘要(中文)
稠密检索器通过将查询和文档编码为连续向量来增强检索效果,但它们通常难以处理需要大量推理的查询。虽然大型语言模型(LLM)可以重构查询以捕捉复杂的推理,但普遍应用它们会产生巨大的计算成本。在这项工作中,我们提出了自适应查询推理(AdaQR),这是一个混合查询重写框架。在该框架内,Reasoner Router动态地将每个查询定向到快速稠密推理或深度LLM推理。稠密推理由稠密推理器实现,该推理器直接在嵌入空间中执行LLM风格的推理,从而实现效率和准确性之间的可控权衡。在大型检索基准BRIGHT上的实验表明,AdaQR将推理成本降低了28%,同时保持甚至提高了7%的检索性能。
🔬 方法详解
问题定义:稠密检索器在处理需要复杂推理的查询时表现不佳,而直接使用大型语言模型(LLM)进行查询重写虽然可以提升性能,但计算成本过高,难以在实际应用中普及。因此,如何高效地处理需要推理的查询,在性能和效率之间取得平衡,是本文要解决的问题。
核心思路:本文的核心思路是设计一个自适应的查询推理框架,根据查询的复杂程度,动态地选择使用高效的稠密推理或强大的LLM推理。对于简单的查询,使用稠密推理以保证效率;对于复杂的查询,则使用LLM推理以提升准确率。通过这种方式,可以在保证检索性能的同时,显著降低计算成本。
技术框架:AdaQR框架包含两个主要模块:Reasoner Router和Dense Reasoner。Reasoner Router负责判断查询是否需要LLM推理,并将其路由到相应的推理器。Dense Reasoner则在嵌入空间中执行LLM风格的推理,实现快速且高效的推理过程。整体流程为:输入查询 -> Reasoner Router -> (Dense Reasoner 或 LLM) -> 检索。
关键创新:AdaQR的关键创新在于提出了一个混合推理框架,能够根据查询的复杂程度自适应地选择推理方式。此外,Dense Reasoner的设计也十分巧妙,它能够在嵌入空间中模拟LLM的推理过程,从而在保证一定准确率的前提下,显著提升推理效率。
关键设计:Reasoner Router可以使用分类模型进行训练,判断查询是否需要LLM推理。Dense Reasoner的具体实现方式未知,但推测可能使用了对比学习或知识蒸馏等技术,使其能够在嵌入空间中学习到LLM的推理能力。损失函数的设计需要同时考虑检索性能和推理成本,以达到最佳的平衡。
🖼️ 关键图片
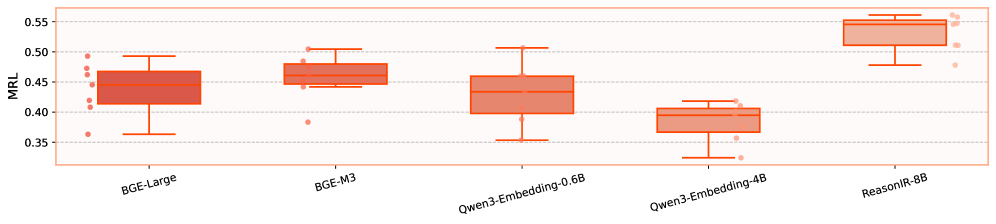

📊 实验亮点
实验结果表明,AdaQR在BRIGHT基准测试中,与直接使用LLM进行查询重写相比,将推理成本降低了28%,同时保持甚至提高了7%的检索性能。这表明AdaQR能够在保证检索质量的前提下,显著提升推理效率,具有很强的实用价值。
🎯 应用场景
AdaQR框架可应用于各种需要高效信息检索的场景,例如搜索引擎、问答系统、推荐系统等。通过降低推理成本,该框架可以使LLM推理在实际应用中更加可行,从而提升用户体验。未来,该研究可以进一步扩展到其他领域,例如知识图谱推理、对话系统等。
📄 摘要(原文)
Dense retrievers enhance retrieval by encoding queries and documents into continuous vectors, but they often struggle with reasoning-intensive queries. Although Large Language Models (LLMs) can reformulate queries to capture complex reasoning, applying them universally incurs significant computational cost. In this work, we propose Adaptive Query Reasoning (AdaQR), a hybrid query rewriting framework. Within this framework, a Reasoner Router dynamically directs each query to either fast dense reasoning or deep LLM reasoning. The dense reasoning is achieved by the Dense Reasoner, which performs LLM-style reasoning directly in the embedding space, enabling a controllable trade-off between efficiency and accuracy. Experiments on large-scale retrieval benchmarks BRIGHT show that AdaQR reduces reasoning cost by 28% while preserving-or even improving-retrieval performance by 7%.